GPT‑5.3‑Codex: Codex už není jen „coding agent“, ale prakticky kolega pro práci na počítači
OpenAI 5. února 2026 představilo GPT‑5.3‑Codex – nový model pro Codex, který má ambici pokrýt prakticky celé spektrum profesionální práce na počítači. Nejde jen o další iteraci „modelu na kód“: podle oznámení kombinuje frontier výkon GPT‑5.2‑Codex v programování s rozumovými a znalostními schopnostmi GPT‑5.2 do jednoho modelu, a zároveň běží o 25 % rychleji. V praxi to znamená delší běhy úloh, víc práce s nástroji (tool use) a víc komplexního vykonávání kroků bez toho, aby se ztrácel kontext.
Zajímavý detail: GPT‑5.3‑Codex je podle OpenAI první model, který byl „instrumentální“ při vytváření sebe sama. Tým Codexu použil rané verze k ladění vlastního tréninku, k řízení nasazení i k diagnostice testů a evaluací. Jinými slovy: model zrychloval vývoj vlastního nástupce.
A ještě jedna posunová věta, která dobře vystihuje směr: Codex se tímhle krokem posouvá z agenta, který píše a kontroluje kód, na agenta, který zvládne téměř cokoli, co vývojáři a další profesionálové běžně dělají na počítači.
Frontier agentní schopnosti: co se vlastně zlepšilo
OpenAI v oznámení staví GPT‑5.3‑Codex jako nový „industry high“ na benchmarkových sadách SWE‑Bench Pro a Terminal‑Bench a zároveň zmiňuje silný výkon na OSWorld a GDPval. Tyhle čtyři benchmarky používají interně pro měření programování, agentního chování a „real‑world“ schopností.
Programování: SWE‑Bench Pro a Terminal‑Bench 2.0
V čistě softwarovém inženýrství se GPT‑5.3‑Codex podle OpenAI dostává na state‑of‑the‑art na SWE‑Bench Pro. Tohle je podstatné i kvůli tomu, co se testuje: zatímco SWE‑bench Verified je omezený na Python, SWE‑Bench Pro pokrývá čtyři jazyky a má být odolnější vůči kontaminaci (contamination‑resistant), náročnější, pestřejší a blíž realitě v průmyslu.
Současně model výrazně překonává předchozí state‑of‑the‑art na Terminal‑Bench 2.0, který cílí na „terminálové“ dovednosti, které agent typu Codex potřebuje (typicky práce s příkazy, iterativní diagnostika, skriptování a podobně). OpenAI navíc vypichuje, že GPT‑5.3‑Codex tohle zvládá s menším počtem tokenů než dřívější modely – což v praxi znamená lepší využití kontextu a víc prostoru na užitečnou práci.
Webový vývoj: dlouhé běhy, estetika a „compaction“
Vedle benchmarků se OpenAI snaží ukázat, že model umí dělat výrazně komplexnější webové věci „od nuly“ a vydržet na nich pracovat dlouho. Kombinace frontier kódování, zlepšení v estetice a tzv. compaction (v kontextu agentů typicky zhušťování/komprimace průběžného kontextu tak, aby se dalo pokračovat ve velkých bězích) má vést k tomu, že model zvládne stavět funkční hry a aplikace přes dny iterací.
Konkrétně OpenAI otestovalo web dev i dlouhotrvající agentní chování tak, že požádalo GPT‑5.3‑Codex o vytvoření dvou her:
- druhou verzi závodní hry z předchozího uvedení Codex appu (viz odkaz níže),
- a potápěčskou hru založenou na průzkumu útesů a sběratelském „fish codex“ s managementem kyslíku, tlaku a hazardů.
Test probíhal s použitím skillu „develop web game“ a s předvybranými, obecnými follow‑up prompty typu „fix the bug“ nebo „improve the game“. Model pak měl iterovat autonomně „over millions of tokens“.
OpenAI zveřejnilo i hratelné výsledky:
- Závodní hra s více jezdci, osmi mapami a itemy na mezerník: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Potápěčská hra s útesy, sběrem, kyslíkem/tlakem a hazardy: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
V běžnějším webu OpenAI tvrdí, že GPT‑5.3‑Codex líp chápe záměr u „day‑to‑day“ webů než GPT‑5.2‑Codex: jednoduché nebo nedostatečně specifikované prompty prý častěji končí stránkou s rozumnými defaulty a větší funkčností, tedy lepším „plátnem“ pro další úpravy.
Jako ilustraci uvádí srovnání dvou landing pages (stejný prompt pro GPT‑5.3‑Codex i GPT‑5.2‑Codex). GPT‑5.3‑Codex podle popisu automaticky:
- zobrazil roční plán jako zlevněnou měsíční cenu (místo prostého přepočtu roční sumy), takže sleva působí záměrněji a čitelněji,
- vytvořil automaticky přecházející carousel s testimonials se třemi odlišnými citacemi (ne jen jednou), takže stránka působí kompletji a blíž produkci už v základu.
Mimo kód: celý software lifecycle i „knowledge work“
Silná část oznámení je přesun důrazu z pouhého generování kódu na podporu práce napříč software lifecycle: debugging, deployment, monitoring, psaní PRD (Product Requirements Document), editace textů, user research, testy, metriky a další. A zároveň přiznání, že spousta rolí (engineer, designer, PM, data scientist) tráví výrazný čas výstupy, které nejsou kód – prezentace, tabulky, dokumentace, analýzy.
K tomu OpenAI odkazuje na GDPval (eval z roku 2025), který měří výkon na dobře specifikovaných úlohách znalostní práce napříč 44 profesemi. GPT‑5.3‑Codex má na GDPval vykazovat silný výkon a podle oznámení „matching GPT‑5.2“.
V článku jsou ukázky typů výstupů, které agent v rámci těchto úloh vytvářel (např. slides s finančním poradenstvím, školící dokument pro retail, NPV analýzu v tabulce, fashion prezentaci do PDF). Jeden z uvedených příkladů obsahuje i celý kontext zadání: agent v roli finančního poradce připravuje 10slidovou prezentaci, proč jako fiduciary doporučit klientům nevolit převod CD (certificates of deposits) do variable annuities, s explicitními srovnáními a oporou ve zdrojích NAIC a FINRA.
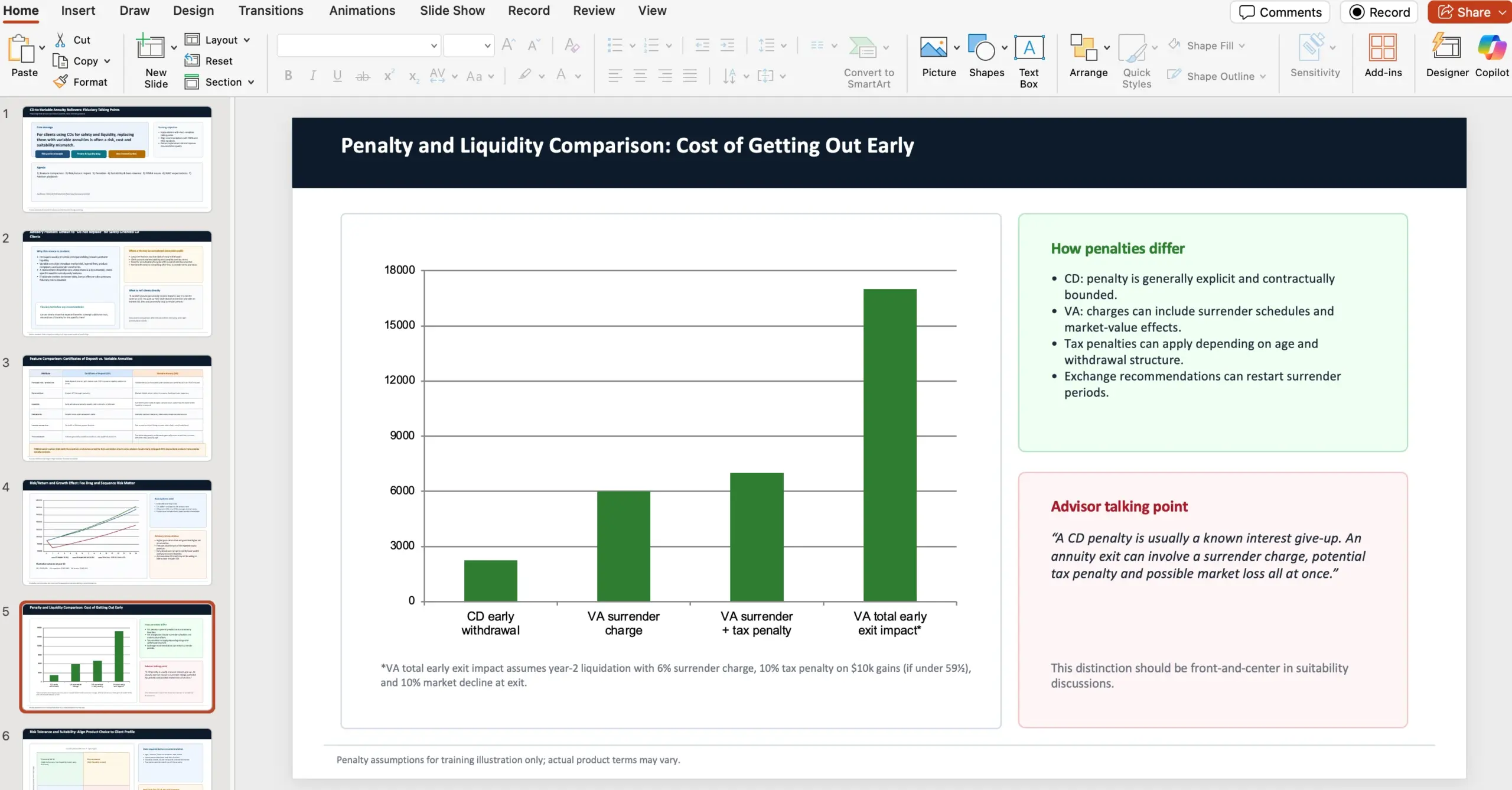
OpenAI připomíná, že jednotlivé úlohy v GDPval navrhují zkušení profesionálové a mají odpovídat reálné práci v dané profesi.
Další důležitý benchmark je OSWorld: agent má plnit produktivní úkoly ve vizuálním desktopovém prostředí, a model používá vision. OpenAI tvrdí, že GPT‑5.3‑Codex zde ukazuje výrazně lepší schopnosti práce s počítačem než předchozí GPT modely. V OSWorld‑Verified se v článku zmiňuje, že lidé dosahují přibližně ~72 %.
Celkový rámec, který OpenAI staví, je jasný: kombinace výsledků v kódování, frontendu a „computer‑use“ úlohách naznačuje posun směrem k jednomu obecnějšímu agentovi, který umí přemýšlet, stavět i vykonávat kroky napříč reálnou technickou prací.
Interaktivní spolupráce: méně čekání na finále, víc řízení v průběhu
S rostoucími schopnostmi agentů se podle OpenAI posouvá bottleneck od „co agent umí“ k tomu, jak snadno se dá řídit, zadávat a dohlížet na více agentů paralelně. V tomhle směru má Codex app zjednodušovat management agentů a s GPT‑5.3‑Codex se má stát víc interaktivní.
Praktický rozdíl je v průběžných updatech: místo čekání na finální výstup má Codex častěji reportovat klíčová rozhodnutí a progres. V reálném čase se pak dá doptávat, diskutovat přístupy a „steerovat“ směrem k řešení. Model má průběžně vysvětlovat, co dělá, reagovat na zpětnou vazbu a držet uživatele v obraze od začátku do konce.
Pokud chceš steering zapnout, v Codex appu je to podle oznámení v: Settings > General > Follow-up behavior.
Jak OpenAI použilo Codex při tréninku a nasazení GPT‑5.3‑Codex
Z technického pohledu je na oznámení nejzajímavější to, jak otevřeně popisuje, že Codex se stal interním akcelerátorem pro výzkum i engineering. OpenAI píše, že poslední rychlé zlepšování Codexu stojí na výzkumných projektech napříč firmou (v horizontu měsíců až let) – a zároveň tyhle projekty samotné Codex urychluje. Někteří výzkumníci a inženýři to prý popisují tak, že jejich práce je dnes fundamentálně jiná než před dvěma měsíci.
Už rané verze GPT‑5.3‑Codex měly podle OpenAI natolik výjimečné schopnosti, že tým s nimi dokázal zlepšovat trénink a podporovat nasazení pozdějších verzí. Zmíněné příklady použití jsou hodně konkrétní:
- Výzkumný tým použil Codex k monitoringu a ladění trénovacího běhu pro tento release.
- Codex neřešil jen infrastrukturu: pomáhal sledovat vzorce v průběhu tréninku, dělal hlubokou analýzu kvality interakcí, navrhoval opravy a stavěl bohaté aplikace pro lidi, aby přesně viděli, jak se chování modelu liší od předchozích verzí.
- Engineering tým s Codexem optimalizoval a adaptoval „harness“ (testovací/integrační rámec) pro GPT‑5.3‑Codex.
- Když se začaly objevovat zvláštní edge‑casy dopadající na uživatele, Codex pomohl identifikovat bugy v renderování kontextu a najít root cause nízkých cache hit rates.
- Během launch fáze má GPT‑5.3‑Codex dál pomáhat dynamicky škálovat GPU clustery kvůli traffic špičkám a držet stabilní latenci.
- V alpha testování chtěl jeden výzkumník odhadnout, kolik práce navíc model udělá „per turn“ a jak se liší produktivita. GPT‑5.3‑Codex navrhl několik jednoduchých regex klasifikátorů (frekvence upřesňujících dotazů, pozitivní/negativní reakce uživatele, progres na úloze) a škálovatelně je spustil nad session logy a vytvořil report se závěry.
- Pozorování z alpha: lidé byli spokojenější, protože agent lépe chápal záměr a udělal víc práce na tah s méně upřesňujícími otázkami.
- Data z alpha testů měla kvůli odlišnosti modelu mnoho nezvyklých a kontraintuitivních výsledků. Data scientist s pomocí GPT‑5.3‑Codex postavil nové datové pipeline a vizualizoval výsledky bohatěji, než umožňovaly standardní dashboardy.
- Výsledky pak společně s Codexem ko‑analyzovali; Codex shrnul klíčové insighty přes tisíce datových bodů za méně než tři minuty.
OpenAI to uzavírá tím, že jednotlivé příklady jsou zajímavé samy o sobě, ale dohromady prý vedly k výraznému urychlení práce výzkumu, engineeringu i produktových týmů.
Kyberbezpečnost: „High capability“ klasifikace a silnější ochrany
V posledních měsících OpenAI pozoruje podle oznámení výrazné zlepšení výkonu na úlohách kyberbezpečnosti – pro vývojáře i security profesionály. Paralelně firma připravovala posílené ochrany (cyber safeguards) pro defenzivní použití a celkovou odolnost ekosystému.
GPT‑5.3‑Codex je podle OpenAI první model klasifikovaný pro kyberbezpečnostní úlohy jako „High capability“ v rámci jejich Preparedness Framework a zároveň první model, který byl přímo trénovaný na identifikaci softwarových zranitelností. OpenAI zároveň říká, že nemá definitivní důkazy, že by model dokázal automatizovat kyberútoky end‑to‑end – přesto volí preventivní (precautionary) přístup a nasazuje dosud nejkomplexnější cyber security safety stack.
Konkrétně vyjmenované mitigace zahrnují:
- safety training,
- automatizované monitorování,
- trusted access pro pokročilé schopnosti,
- enforcement pipelines včetně threat intelligence.
Protože kyberbezpečnost je z principu dual‑use oblast, OpenAI popisuje evidence‑based a iterativní přístup: zrychlovat schopnost obránců hledat a opravovat zranitelnosti a současně zpomalovat zneužití.
Součástí toho je spuštění pilotního programu Trusted Access for Cyber, který má akcelerovat výzkum kybernetické obrany.
Na úrovni „ekosystémových“ pojistek OpenAI zmiňuje:
- rozšíření private bety Aardvark (security research agent) jako první nabídky v sadě Codex Security produktů a nástrojů,
- partnerství s maintainery open source, aby poskytli bezplatné skenování codebase pro široce používané projekty, například Next.js – v oznámení se odkazuje na příklad, kdy security researcher s Codexem našel zranitelnosti zveřejněné minulý týden: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
A z pohledu podpory obrany navazuje OpenAI na svůj $1M Cybersecurity Grant Program z roku 2023 a oznamuje další závazek: $10M v API kreditech pro urychlení cyber defense s nejpokročilejšími modely, zejména pro open source software a systémy kritické infrastruktury. Organizace, které dělají security research v dobré víře (good‑faith), mohou žádat o API kredity a podporu skrze Cybersecurity Grant Program.
Dostupnost, rychlost a infrastruktura
GPT‑5.3‑Codex je podle oznámení dostupný v rámci placených tarifů ChatGPT všude tam, kde lze používat Codex: v aplikaci, CLI, IDE extension i na webu. OpenAI zároveň uvádí, že na bezpečném zpřístupnění přes API teprve pracuje (API access má přijít „soon“).
Kromě schopností modelu OpenAI zmiňuje i čistě praktický benefit: pro uživatele Codexu teď GPT‑5.3‑Codex běží o 25 % rychleji díky zlepšením v infrastruktuře a inference stacku, což má znamenat rychlejší interakce i výsledky.
Hardwarová poznámka pro ty, kdo sledují infrastrukturu: GPT‑5.3‑Codex byl co‑designovaný pro, trénovaný s a servírovaný na NVIDIA GB200 NVL72 systémech. OpenAI v textu děkuje NVIDIA za partnerství.
Co tím OpenAI naznačuje dál
V části „What’s next“ OpenAI rámuje GPT‑5.3‑Codex jako krok od psaní kódu k používání kódu jako nástroje k ovládání počítače a dokončování práce end‑to‑end. Tlačení hranice coding agentů má podle nich odemykat i širší třídu „knowledge work“: od stavění a nasazování software po výzkum, analýzu a exekuci komplexních úloh.
Z „nejlepšího coding agenta“ se tak stává základ pro obecnějšího spolupracovníka na počítači – což v důsledku rozšiřuje jak to, kdo může stavět, tak i to, co je s Codexem možné.
Appendix: čísla z benchmarků v jedné tabulce
OpenAI přidalo přehled výsledků (vše s „xhigh reasoning effort“ pro GPT‑5.3‑Codex v blogu):
- SWE‑Bench Pro (Public): GPT‑5.3‑Codex 56.8 %, GPT‑5.2‑Codex 56.4 %, GPT‑5.2 55.6 %
- Terminal‑Bench 2.0: GPT‑5.3‑Codex 77.3 %, GPT‑5.2‑Codex 64.0 %, GPT‑5.2 62.2 %
- OSWorld‑Verified: GPT‑5.3‑Codex 64.7 %, GPT‑5.2‑Codex 38.2 %, GPT‑5.2 37.9 %
- GDPval (wins or ties): GPT‑5.3‑Codex 70.9 %, GPT‑5.2 -, GPT‑5.2 70.9 % (high)
- Cybersecurity Capture The Flag Challenges: GPT‑5.3‑Codex 77.6 %, GPT‑5.2‑Codex 67.4 %, GPT‑5.2 67.7 %
- SWE‑Lancer IC Diamond: GPT‑5.3‑Codex 81.4 %, GPT‑5.2‑Codex 76.0 %, GPT‑5.2 74.6 %
Poznámka k evaluacím
V oznámení je uvedeno, že všechny evaluace v blogu běžely na GPT‑5.3‑Codex s „xhigh reasoning effort“.
Odkazy z oznámení (užitečné pro kontext)
Tereza Novotná
Šéfredaktorka českého týmu, agile koučka a scrum master. Vedení týmů a optimalizace vývojových procesů je mou specializací.
Všechny příspěvky