

GPT-5.3-Codex: när Codex blir en fullskalig agent på datorn (och dessutom bygger sig själv)
OpenAI har lanserat GPT‑5.3‑Codex, en ny modell som positioneras som den mest kapabla agentic coding model hittills – alltså en modell som inte bara skriver kod, utan kan planera, använda verktyg och genomföra längre uppgifter på en dator med bibehållen kontext. Nyckelpoängen i släppet är att modellen kombinerar kodprestandan från GPT‑5.2‑Codex med resonemang och professionell kunskap från GPT‑5.2 – i en och samma modell – och att den enligt OpenAI dessutom körs 25% snabbare för Codex-användare.
Det som sticker ut mest är inte en enskild benchmark-siffra, utan skiftet i ambition: Codex ska gå från att vara en agent som kan skriva och granska kod till en agent som kan göra nästan allt som utvecklare (och andra yrkesroller) gör på en dator: debugga, deploya, övervaka, producera dokument, analysera data i kalkylark, bygga appar och driva arbetet framåt över många turer.
Frontier agentic capabilities: vad OpenAI faktiskt mäter
OpenAI lyfter fyra benchmarksviter som de använder för att mäta kodning, agentbeteende och “real-world”-kapacitet: SWE‑Bench Pro, Terminal‑Bench, OSWorld och GDPval. Påståendet är att GPT‑5.3‑Codex sätter en ny industrinivå på SWE‑Bench Pro och Terminal‑Bench, och visar starka resultat på OSWorld och GDPval.
Kodning: SWE‑Bench Pro och Terminal‑Bench 2.0
På kodsidan framhålls SWE‑Bench Pro som en mer “industrirelevant” och mer kontaminationsresistent uppföljare till SWE‑bench Verified. Skillnaden som betonas är att Verified bara testar Python, medan SWE‑Bench Pro spänner över fyra språk och ska vara mer utmanande och diversifierad.
Utöver ren SWE‑Bench presterar GPT‑5.3‑Codex enligt OpenAI också långt över tidigare state of the art på Terminal‑Bench 2.0, som fokuserar på terminalfärdigheter en kodagent behöver. En detalj OpenAI lyfter är att modellen uppnår detta med färre tokens än tidigare modeller, vilket i praktiken ska göra att man “får mer gjort” inom samma tokenbudget.
Webbutveckling: långkörande iteration över miljoner tokens
För att testa webb- och agentkapacitet i mer “verkliga” långkörningar lät OpenAI modellen bygga två spel från grunden över flera dagar. Upplägget var att använda en förmåga som kallas develop web game skill (en anpassad “skill”, alltså en förkonfigurerad förmåga/verktygskedja i Codex) samt förvalda, generiska uppföljningsprompter som “fix the bug” och “improve the game”.
Resultatet blev att GPT‑5.3‑Codex itererade autonomt över miljoner tokens på spelen:
- Ett racingspel (version två av racingspelet från lanseringen av Codex-appen) med olika racers, åtta banor och items som används med mellanslagstangenten. Spelet går att spela här: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Ett dykspel där du utforskar olika rev, samlar dem för att fylla din “fish codex”, samtidigt som du hanterar syre, tryck och faror. Spelet går att spela här: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
En annan vardagsnära detalj: OpenAI menar att GPT‑5.3‑Codex bättre förstår intent när du ber den bygga “vanliga” webbplatser, jämfört med GPT‑5.2‑Codex. När promptar är enkla eller underspecificerade ska den oftare landa i mer funktionella standardval som ger en bättre startyta.
De visar bland annat ett exempel där modellen bygger en landing page. Skillnader som lyfts fram är att GPT‑5.3‑Codex automatiskt presenterar årsplanen som ett rabatterat månadspris (i stället för att multiplicera årssumman) och att den skapar en automatiskt övergående testimonial-karusell med tre distinkta citat i stället för ett, vilket gör att sidan känns mer komplett och mer “production-ready” som default.
Bortom kod: hela mjukvarulivscykeln och kunskapsarbete
OpenAI trycker hårt på att “software engineering” i praktiken inkluderar betydligt mer än att spotta ut kod. GPT‑5.3‑Codex är tänkt att stötta hela livscykeln: debugging, deploy, monitoring, skriva PRDs, copy editing, user research, tester, metrics och mer. Och agentförmågan ska även kunna användas till saker som slide decks och kalkylarksanalys.
För att sätta detta i en mätbar ram refererar OpenAI till GDPval – en utvärdering de släppte 2025 för väl specificerade kunskapsarbetsuppgifter över 44 yrken. De skriver att GPT‑5.3‑Codex visar stark prestanda på professionellt kunskapsarbete mätt via GDPval, och att den matchar GPT‑5.2 på detta mått.
Som exempel visar de arbetsprodukter som agenten kan ta fram, bland annat:
- Financial advice slides
- Retail training doc
- NPV analysis spreadsheet
- Fashion presentation PDF
Exempelprompt: 10-slide PowerPoint för rådgivare (NAIC + FINRA)
I ett av exemplen får modellen en tydlig roll och kontext: du är finansiell rådgivare på en wealth management-firma och ska skapa en 10-slide PowerPoint med talking points om varför rådgivare (som fiduciaries) ska avråda kunder från att rulla certificates of deposits till variable annuities via lokala banker – trots att erbjudandet kan upplevas lockande (marknadsavkastning + livslång månatlig utbetalning). Uppgiften specificerar att presentationen ska jämföra features, risk/avkastning och tillväxtpåverkan, skilja på straffavgifter, och kontrastera riskprofil/suitability med källor och regelverk.
Prompten kräver uttryckligen att innehållet ska täcka följande punkter:
- Jämför features mellan certificates of deposits och variable annuities med källa från FINRA som varnar investerare.
- Jämför risk/avkastningsanalys och effekt på tillväxt.
- Särskilj skillnader i penalties mellan instrumenten.
- Kontrastera risk tolerans och lämplighet (suitability) med källa från NAIC Best Interest Regulations.
- Lyft FINRA:s concerns/issues.
- Lyft NAIC:s issues/regulations.
- Notera att NAIC och FINRA har etablerat best interest- och suitability-riktlinjer för rekommendationer kring variable annuities p.g.a. produktens komplexitet.
- Använd angivna webbkällor när presentationen tas fram: https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf och https://www.finra.org/investors/insights/high-yield-cds
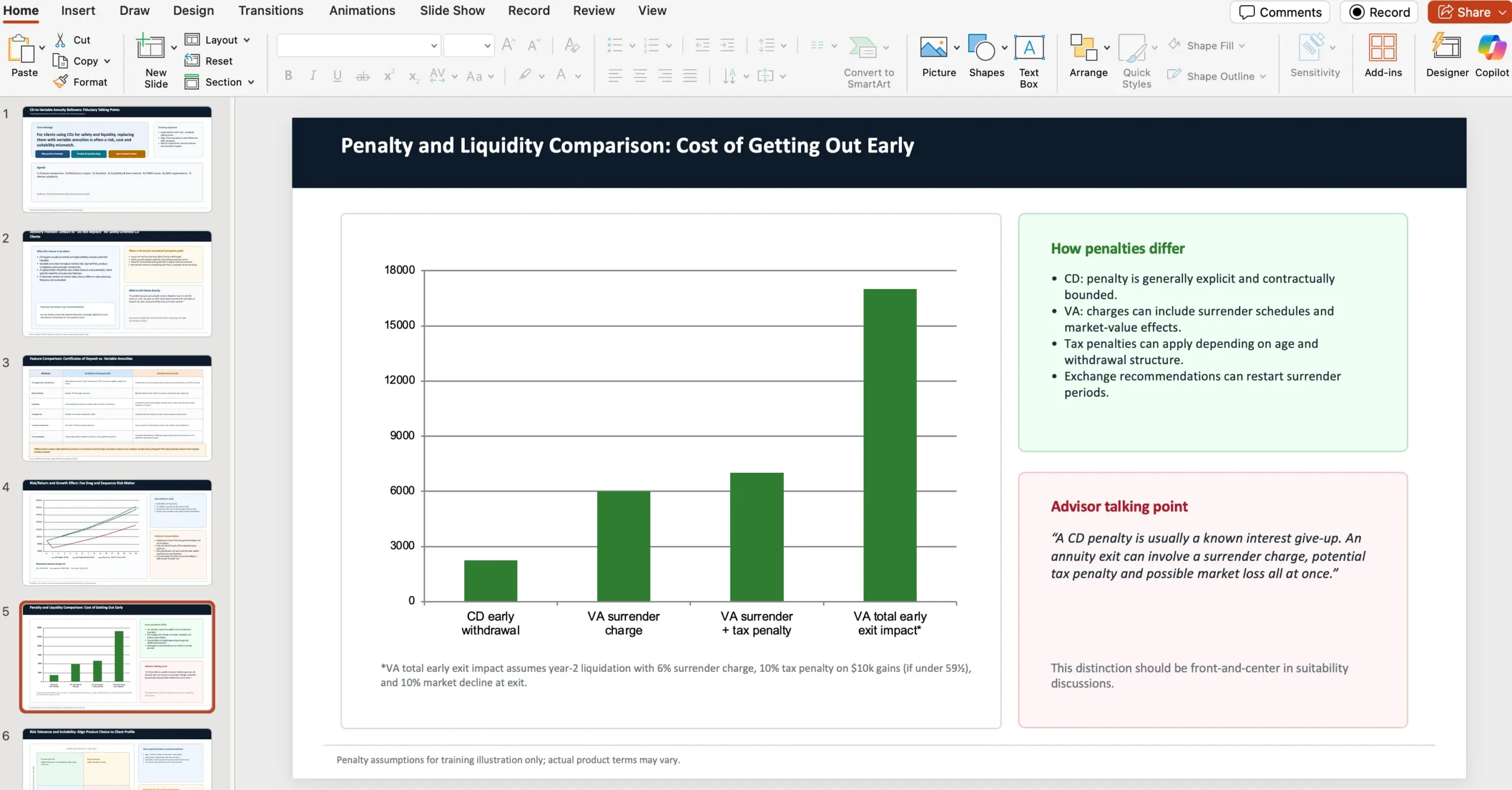
OpenAI poängterar att varje GDPval-task är designad av en erfaren yrkesperson och ska spegla verkligt kunskapsarbete inom respektive roll.
OSWorld: agent som jobbar i en visuell desktopmiljö
OSWorld beskrivs som ett agentbenchmark för datoranvändning där agenten måste lösa produktivitetsuppgifter i en visuell desktopmiljö (med vision). OpenAI säger att GPT‑5.3‑Codex visar betydligt starkare “computer use”-kapacitet än tidigare GPT-modeller. De nämner även att människor ligger runt ~72% på OSWorld‑Verified.
Summeringen OpenAI gör av helheten är att resultaten över kodning, frontend och datoranvändning pekar på ett “step change” mot en mer generell agent som kan resonera, bygga och exekvera över ett brett spektrum av tekniskt arbete.
En mer interaktiv samarbetspartner i Codex-appen
När agentförmågor blir kraftfullare flyttar flaskhalsen från “vad agenten kan” till “hur enkelt vi kan styra och övervaka flera agenter parallellt”. Här lyfter OpenAI interaktionen i Codex-appen som en central del av produkten – och med GPT‑5.3‑Codex ska den bli mer interaktiv.
Det konkreta är att Codex med den nya modellen ger frekventa uppdateringar så att du löpande ser viktiga beslut och progress. I stället för att vänta på en slutleverans kan du interagera i realtid: ställa frågor, diskutera angreppssätt och styra agenten mot rätt lösning. Modellen “pratar igenom” vad den gör, tar feedback och håller dig uppdaterad från start till mål.
Vill du aktivera styrning medan modellen jobbar i appen anger OpenAI följande väg: Settings > General > Follow-up behavior.
Så använde OpenAI Codex för att träna och driftsätta GPT‑5.3‑Codex
En detalj som är rätt unik i den här lanseringen: OpenAI beskriver GPT‑5.3‑Codex som den första modellen som var instrumentell i att skapa sig själv. Codex-teamet använde tidiga versioner för att debugga sin egen träning, hantera sin egen deployment och diagnostisera testresultat och utvärderingar. De skriver att teamet blev överraskat av hur mycket Codex kunde accelerera den egna utvecklingen.
De ramar också in de snabba förbättringarna som resultatet av forskningsprojekt som pågått i månader eller år, men att dessa projekt nu accelereras av Codex. Flera forskare och ingenjörer beskriver enligt OpenAI att jobbet idag är fundamentalt annorlunda än för bara två månader sedan.
Exempel: researchteamet (träning, övervakning, analysverktyg)
OpenAI ger flera konkreta exempel på hur researchteamet använde Codex under träningskörningen för releasen:
- Övervaka och debugga själva träningskörningen.
- Identifiera mönster genom träningsförloppet (inte bara fixa infrastrukturproblem).
- Göra djup analys av interaction quality.
- Föreslå fixar.
- Bygga rika applikationer som gör det möjligt för mänskliga forskare att precis förstå hur modellens beteende skiljer sig från tidigare modeller.
Exempel: engineeringteamet (harness, edge cases, cache, GPU-skalning)
På engineering-sidan beskriver OpenAI hur Codex användes för att optimera och anpassa harness (test- och körmiljö) för GPT‑5.3‑Codex. När de såg märkliga edge cases som påverkade användare använde teammedlemmar Codex för att:
- Identifiera buggar i context rendering.
- Hitta rotorsaken till låga cache hit rates.
Under själva lanseringen uppges GPT‑5.3‑Codex fortsätta hjälpa teamet genom att dynamiskt skala GPU-kluster för att hantera trafiktoppar och hålla latensen stabil.
Exempel: alpha-test och produktivitetsmätning med regex-klassificerare
Under alpha-testning ville en forskare förstå hur mycket extra arbete GPT‑5.3‑Codex faktiskt fick gjort per tur, och skillnaden i produktivitet. Enligt OpenAI tog GPT‑5.3‑Codex fram flera enkla regex-klassificerare för att estimera:
- Frekvens av förtydliganden (clarifications).
- Positiva användarsvar.
- Negativa användarsvar.
- Progress på uppgiften.
Sedan körde modellen detta skalbart över alla sessionsloggar och producerade en rapport med slutsatser. Slutsatsen som återges är att personer som byggde med Codex var nöjdare när agenten bättre förstod intent och gjorde mer framsteg per tur, med färre förtydligande frågor.
Exempel: data science (nya pipelines, rikare visualisering, analys på minuter)
OpenAI beskriver också hur datan från alpha-testningen gav många ovanliga och kontraintuitiva resultat eftersom modellen skiljer sig så mycket från föregångarna. En data scientist byggde tillsammans med GPT‑5.3‑Codex nya datapipelines och visualiserade resultaten rikare än standarddashboardar klarade. Resultaten co-analyserades med Codex, som sammanfattade nyckelinsikter över tusentals datapunkter på under tre minuter.
OpenAI:s egen summering är att dessa nya förmågor, sammantaget, gav en kraftig acceleration för research-, engineering- och produktteam.
Säkerhet: “High capability” för cybersäkerhetsuppgifter och en större safety stack
På säkerhetssidan säger OpenAI att de senaste månaderna gett meningsfulla lyft i modellprestanda på cybersäkerhetsuppgifter, vilket ska gynna både utvecklare och security-proffs. Parallellt hänvisar de till att de förberett stärkta skydd för cyberanvändning: https://openai.com/index/strengthening-cyber-resilience/.
GPT‑5.3‑Codex är enligt OpenAI den första modellen de klassar som “High capability” för cybersäkerhetsrelaterade uppgifter under deras Preparedness Framework, och den första de direkt tränat för att identifiera mjukvarusårbarheter. De skriver samtidigt att de inte har definitiv evidens för att modellen kan automatisera cyberattacker end-to-end – men att de ändå tar en försiktighetslinje och deployar sin mest omfattande cybersäkerhetsinriktade safety stack hittills.
De mitigeringar som nämns inkluderar:
- Safety training.
- Automated monitoring.
- Trusted access för avancerade förmågor.
- Enforcement pipelines inklusive threat intelligence.
Eftersom cybersäkerhet är dual-use (kan användas både defensivt och offensivt) beskriver OpenAI en evidensbaserad och iterativ strategi: snabba på defenders förmåga att hitta och fixa sårbarheter, samtidigt som missbruk bromsas.
Som del i detta lanseras Trusted Access for Cyber, ett pilotprogram för att accelerera forskning inom cyberförsvar: https://openai.com/index/trusted-access-for-cyber/.
De investerar också i skydd på ekosystemnivå, bland annat genom att expandera private beta för Aardvark, deras security research agent och första erbjudandet i en svit av Codex Security-produkter och verktyg: https://openai.com/index/introducing-aardvark/.
OpenAI nämner även partnerskap med open source-maintainers för gratis scanning av kodbaser i brett använda projekt som Next.js. Som konkret exempel länkar de till en Vercel-sammanfattning av CVE:er som en researcher hittade med hjälp av Codex och som publicerades förra veckan: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472.
Slutligen bygger de vidare på ett $1M Cybersecurity Grant Program som lanserades 2023 och åtar sig nu $10M i API credits för att accelerera cyberförsvar med deras mest kapabla modeller, särskilt för open source och kritisk infrastruktur. Organisationer som bedriver “good-faith security research” kan ansöka om API credits och stöd via: https://openai.com/index/openai-cybersecurity-grant-program/.
Tillgänglighet och drift: app, CLI, IDE och web (API “snart”)
GPT‑5.3‑Codex är tillgänglig med betalplaner i ChatGPT, överallt där du kan använda Codex: appen, CLI, IDE extension och web. OpenAI skriver att de arbetar på att säkert möjliggöra API access soon (utan att ange datum).
OpenAI uppger också att de nu kör GPT‑5.3‑Codex 25% snabbare för Codex-användare tack vare förbättringar i infrastruktur och inference stack, vilket ska ge snabbare interaktion och snabbare resultat.
På hårdvarusidan: GPT‑5.3‑Codex ska vara co-designad för, tränad med och serverad på NVIDIA GB200 NVL72-system, och OpenAI tackar NVIDIA för partnerskapet.
Appendix: benchmark-tabellen (xhigh) och en viktig fotnot
I appendix listar OpenAI en tabell med resultat för GPT‑5.3‑Codex (xhigh), GPT‑5.2‑Codex (xhigh) och GPT‑5.2 (xhigh). Siffrorna som publiceras är:
- SWE‑Bench Pro (Public): GPT‑5.3‑Codex 56.8%, GPT‑5.2‑Codex 56.4%, GPT‑5.2 55.6%
- Terminal‑Bench 2.0: GPT‑5.3‑Codex 77.3%, GPT‑5.2‑Codex 64.0%, GPT‑5.2 62.2%
- OSWorld‑Verified: GPT‑5.3‑Codex 64.7%, GPT‑5.2‑Codex 38.2%, GPT‑5.2 37.9%
- GDPval (wins or ties): GPT‑5.3‑Codex 70.9%, GPT‑5.2‑Codex – , GPT‑5.2 70.9% (high)
- Cybersecurity Capture The Flag Challenges: GPT‑5.3‑Codex 77.6%, GPT‑5.2‑Codex 67.4%, GPT‑5.2 67.7%
- SWE‑Lancer IC Diamond: GPT‑5.3‑Codex 81.4%, GPT‑5.2‑Codex 76.0%, GPT‑5.2 74.6%
Fotnoten som är lätt att missa
OpenAI anger att alla utvärderingar i blogginlägget kördes på GPT‑5.3‑Codex med xhigh reasoning effort.
Praktisk take för oss som bygger webben
Det intressanta med GPT‑5.3‑Codex är att det inte bara handlar om att den löser fler GitHub-issues eller skriver snyggare komponenter. OpenAI ramar in modellen som en agent som kan hålla i en hel kedja: research → implementering → terminalarbete → deploy/övervakning → rapportering och dokumentation, samtidigt som du kan styra den under tiden utan att den tappar kontext.
Om den här interaktiva “kollega”-modellen håller i praktiken är det sannolikt där den stora produktivitetsvinsten finns: inte att allt blir helautomatiskt, utan att längre uppgifter kan drivas framåt kontinuerligt medan du fortfarande kan ställa följdfrågor, korrigera riktning och ta beslut när det spelar roll.


För den som vill testa direkt pekar OpenAI på Codex-appen och en nedladdningslänk för macOS.
Ladda ner Codex-appen (macOS)
Erik Johansson
Förespråkare för Spotify-stil ingenjörskultur. Squad- och chapter-modeller, agil organisationsdesign är mitt område. Teamens prestation är nyckeln.
Alla inlägg

