GPT-5.3-Codex: o salto do Codex de “agente de código” para colaborador completo no computador
A OpenAI apresentou o GPT‑5.3‑Codex como o modelo mais capaz até agora dentro do Codex – e a mudança aqui não é apenas “mais qualidade de código”. A ideia declarada é expandir o Codex para todo o espectro de trabalho profissional num computador: desde escrever e rever código até operar ambientes, gerir tarefas longas, criar artefactos (docs, slides, folhas de cálculo), e manter-te no loop enquanto o agente executa.
Em termos de posicionamento, o GPT‑5.3‑Codex combina duas frentes num só modelo: a performance de coding “frontier” do GPT‑5.2‑Codex com as capacidades de raciocínio e conhecimento profissional do GPT‑5.2 – com a nota adicional de ser 25% mais rápido. O resultado prático é um agente mais apto para trabalho prolongado que envolve pesquisa, uso de ferramentas e execução complexa, sem perder contexto quando vais orientando o processo.
Capacidades agentic de fronteira: o que mudou na prática
A OpenAI enquadra este lançamento com resultados fortes em quatro benchmarks usados para medir capacidades de programação, agência e execução em ambientes reais: SWE‑Bench Pro, Terminal‑Bench, OSWorld e GDPval. O ponto importante, para quem desenvolve, é que o GPT‑5.3‑Codex está a ser tratado como um agente que não só escreve código, mas que consegue executar trabalho em ambiente de computador de forma mais consistente.
Coding: SWE‑Bench Pro e Terminal‑Bench 2.0
No eixo de engenharia de software, o GPT‑5.3‑Codex atinge state‑of‑the‑art no SWE‑Bench Pro, uma avaliação centrada em tarefas reais de software engineering. A comparação que a OpenAI faz é relevante: enquanto o SWE‑bench Verified só testa Python, o SWE‑Bench Pro cobre quatro linguagens, é mais resistente a contaminação e é descrito como mais desafiante, diverso e alinhado com necessidades de indústria.
Além disso, o modelo “dispara” no Terminal‑Bench 2.0, que mede competências de terminal necessárias a um agente como o Codex. Um detalhe com impacto direto no custo/escala: a OpenAI nota que o GPT‑5.3‑Codex alcança estes resultados com menos tokens do que qualquer modelo anterior, o que tende a deixar mais margem para construir (e iterar) antes de bater em limites práticos.
Desenvolvimento web: autonomia a longo prazo (milhões de tokens)
Para testar a vertente de web dev e a capacidade de sustentar tarefas longas, a OpenAI pediu ao GPT‑5.3‑Codex para construir dois jogos: a versão 2 do jogo de corrida mostrado no lançamento da Codex app e um jogo de mergulho. A metodologia foi interessante porque não dependeu de prompts “artesanais”: usaram uma skill específica (“develop web game”) e prompts genéricos de follow‑up como “fix the bug” ou “improve the game”.
O modelo iterou de forma autónoma ao longo de milhões de tokens, refinando mecânicas e funcionalidades. A OpenAI disponibilizou os resultados para jogar diretamente no browser:
- Jogo de corrida com diferentes pilotos, oito mapas e itens ativados com a barra de espaço: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Jogo de mergulho com exploração de recifes, coleção de itens para completar um “fish codex”, e gestão de oxigénio, pressão e perigos: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Outro ponto que aparece de forma muito “produto”: em pedidos mais simples (ou subespecificados), o GPT‑5.3‑Codex tende a assumir defaults mais sensatos e entregar páginas com mais funcionalidade de base. A OpenAI mostra um exemplo com duas landing pages geradas por GPT‑5.3‑Codex vs GPT‑5.2‑Codex, onde o GPT‑5.3‑Codex tomou decisões que fazem diferença em produção: apresentar o plano anual como mensal com desconto (em vez de multiplicar o total anual) e criar um carrossel de testemunhos a transitar automaticamente com três citações distintas, resultando numa página que parece mais completa por defeito.
Para além do código: suporte ao ciclo inteiro (e ao trabalho “de escritório” também)
A OpenAI também faz questão de frisar o óbvio que muitas equipas vivem: engenheiros, designers, PMs e data scientists fazem muito mais do que gerar código. O GPT‑5.3‑Codex foi desenhado para apoiar tarefas ao longo do ciclo de vida: debugging, deployment, monitoring, escrita de PRDs, edição de copy, user research, testes, métricas e mais.
E a ambição vai além do software: o modelo é apresentado como capaz de ajudar a “construir o que quiseres construir”, incluindo apresentações (slide decks) e análise de dados em spreadsheets.
No benchmark GDPval, o GPT‑5.3‑Codex mostra performance forte em trabalho de conhecimento bem especificado, igualando o GPT‑5.2 segundo a OpenAI. O GDPval é descrito como uma avaliação lançada em 2025 para medir performance em tarefas de knowledge work ao longo de 44 profissões, incluindo a criação de apresentações, folhas de cálculo e outros outputs.
Exemplo (GDPval): slides de aconselhamento financeiro com fontes
Um exemplo incluído no anúncio descreve um task completo: atuar como consultor financeiro numa wealth management firm e preparar uma apresentação PowerPoint de 10 slides para aconselhar contra trocar certificados de depósito por variable annuities, com tópicos específicos e referências a fontes externas (NAIC e FINRA). A OpenAI mostra um screenshot do output gerado:
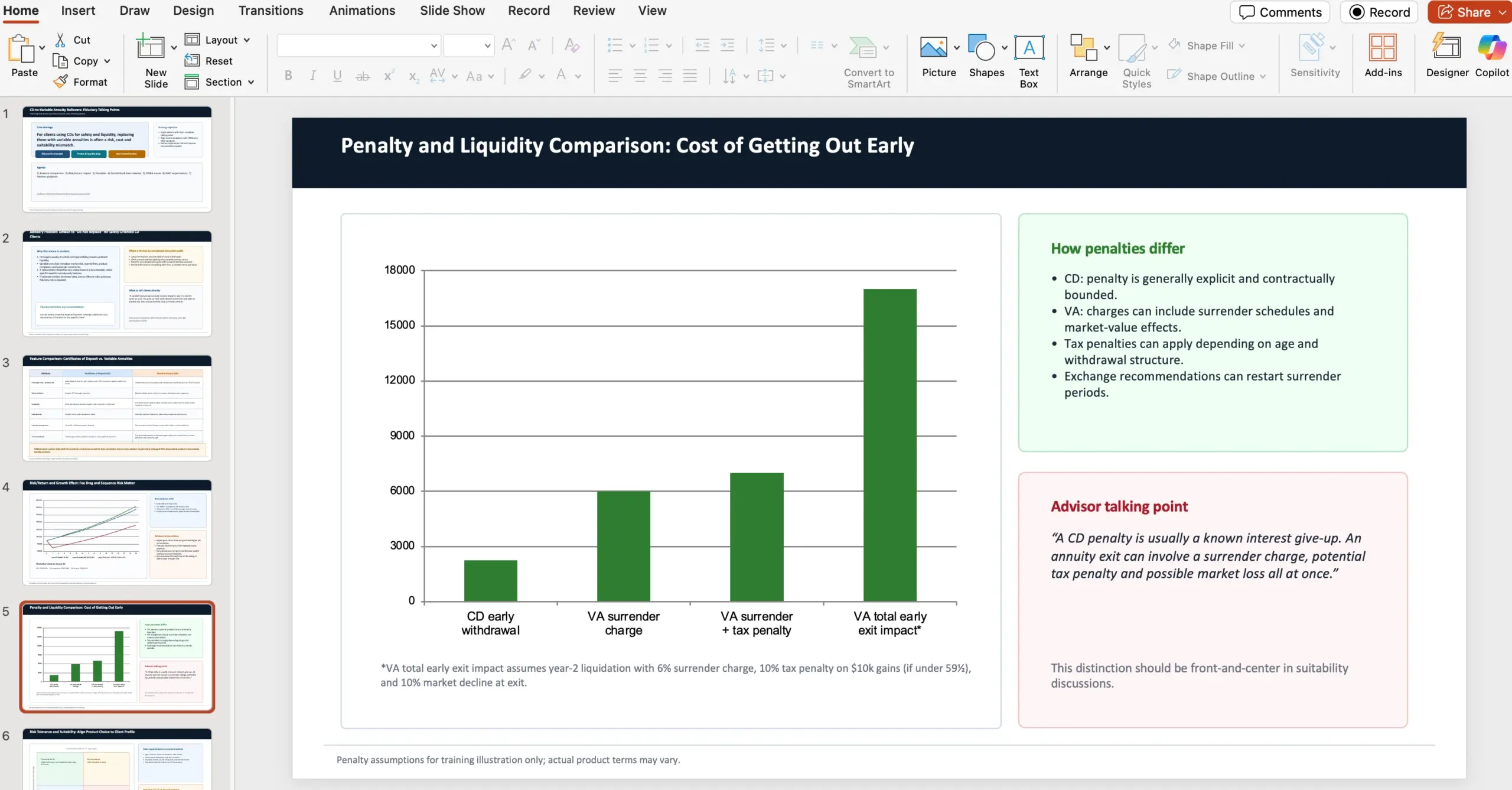
A mensagem por trás deste exemplo é que cada tarefa no GDPval é desenhada por um profissional experiente e tenta refletir trabalho real daquela ocupação – ou seja, menos “demo bonita” e mais trabalho com requisitos.
Já no OSWorld, que é um benchmark de uso do computador em ambiente visual (tipo desktop), a OpenAI afirma que o GPT‑5.3‑Codex dá um salto grande face a modelos GPT anteriores, com resultados muito superiores em OSWorld‑Verified.
Colaborador interativo: a interface passa a ser metade do produto
Há aqui um ponto que, como dev, vale prestar atenção: à medida que os agentes ficam mais capazes, o gargalo desloca-se do “o que conseguem fazer” para “como é que os humanos conseguem dirigir e supervisionar vários agentes em paralelo”. A Codex app é o veículo para isto, e com o GPT‑5.3‑Codex o foco é torná-la mais interativa.
Segundo o anúncio, o Codex passa a fornecer updates frequentes enquanto trabalha. Em vez de esperares por um output final, consegues interagir em tempo real: fazer perguntas, discutir abordagens, e orientar a execução. O modelo explica o que está a fazer, responde a feedback e mantém-te informado do início ao fim.
Onde ativar o “steering” na Codex app
Para permitir que possas orientar o modelo enquanto ele trabalha, ativa a opção em Settings > General > Follow-up behavior.
Como o Codex ajudou a treinar e a lançar o próprio GPT‑5.3‑Codex
A parte mais curiosa deste lançamento é quase “meta”: a OpenAI diz que o GPT‑5.3‑Codex é o primeiro modelo que foi instrumental na sua própria criação. A equipa do Codex usou versões iniciais do modelo para debug do treino, para gerir deployment, e para diagnosticar resultados de testes e avaliações – e descreve que ficou surpreendida com a aceleração que isto trouxe.
Eles enquadram isto num contexto maior: melhorias rápidas no Codex resultam de projetos de investigação que vêm de meses/anos, mas esses projetos estão a ser acelerados pelo próprio Codex. A OpenAI chega a dizer que muitos investigadores e engenheiros sentem que o trabalho hoje é “fundamentalmente diferente” do que era há dois meses, dado o nível de assistência que estes agentes já dão.
Exemplos concretos (research): monitorizar e depurar o treino
Do lado de research, o Codex foi usado para monitorizar e depurar o training run desta release. Mas não ficou pela infraestrutura: ajudou a identificar padrões ao longo do treino, produziu análises profundas sobre qualidade de interação, propôs correções e chegou a construir aplicações ricas para investigadores humanos perceberem, com precisão, como o comportamento diferia face a modelos anteriores.
Exemplos concretos (engineering): harness, edge cases e GPU scaling
Do lado de engenharia, o Codex foi usado para otimizar e adaptar o harness (o conjunto de tooling e infraestrutura que executa/avaliza o modelo) para o GPT‑5.3‑Codex. Quando apareceram edge cases estranhos a impactar utilizadores, membros da equipa usaram o Codex para identificar bugs de rendering de contexto e para encontrar a root cause de baixas cache hit rates.
Durante o lançamento, o GPT‑5.3‑Codex continua a ser usado para tarefas operacionais: escalar dinamicamente clusters de GPU para lidar com picos de tráfego e manter a latência estável.
Exemplos concretos (produtividade): classificadores com regex e análise de logs
Em alpha testing, um investigador quis medir quanto trabalho extra o GPT‑5.3‑Codex conseguia por turno e o impacto na produtividade. O próprio GPT‑5.3‑Codex propôs classificadores simples com regex para estimar: frequência de pedidos de clarificação, respostas positivas/negativas dos utilizadores e progresso na tarefa. Depois correu esses classificadores de forma escalável sobre logs de sessões e gerou um relatório com conclusões.
A OpenAI destaca a conclusão operacional: à medida que o agente entendia melhor a intenção, avançava mais por turno e fazia menos perguntas de clarificação, as pessoas a construir com Codex ficavam mais satisfeitas.
Exemplos concretos (dados): pipelines novos e visualizações mais ricas
Como o GPT‑5.3‑Codex difere bastante dos predecessores, os dados de alpha testing mostraram resultados incomuns e contraintuitivos. Um data scientist trabalhou com o modelo para criar novos data pipelines e visualizar resultados de forma mais rica do que as ferramentas standard de dashboarding permitiam. A análise foi feita em conjunto com o Codex, que resumiu insights-chave em milhares de data points em menos de três minutos.
A OpenAI fecha esta secção com uma leitura agregada: isoladamente, são bons exemplos; em conjunto, estas capacidades resultaram numa aceleração significativa das equipas de research, engineering e produto.
Cibersegurança: “High capability” e um stack de mitigação mais pesado
Nos últimos meses (segundo a OpenAI), houve ganhos relevantes em tarefas de cibersegurança, úteis tanto para developers como para profissionais de segurança. Em paralelo, a empresa diz que tem vindo a preparar salvaguardas reforçadas para suportar uso defensivo e resiliência do ecossistema.
O anúncio marca um ponto novo: o GPT‑5.3‑Codex é o primeiro modelo que a OpenAI classifica como High capability para tarefas relacionadas com cibersegurança sob o seu Preparedness Framework, e o primeiro que foi treinado diretamente para identificar vulnerabilidades de software. Ao mesmo tempo, a OpenAI afirma não ter evidência definitiva de que o modelo consiga automatizar ataques end‑to‑end – mas opta por uma abordagem de precaução.
Por isso, está a ser lançado com o que descrevem como o stack de segurança de ciber mais abrangente até hoje. As mitigações citadas incluem:
- Safety training (treino orientado para segurança)
- Automated monitoring (monitorização automatizada)
- Trusted access para capacidades avançadas
- Enforcement pipelines, incluindo threat intelligence
Como a cibersegurança é inerentemente dual‑use, a OpenAI descreve a estratégia como iterativa e baseada em evidência: acelerar a capacidade de defensores encontrarem e corrigirem vulnerabilidades, enquanto se tenta travar abuso.
Dentro disso, há três iniciativas e compromissos anunciados:
- Lançamento do Trusted Access for Cyber (programa piloto) para acelerar investigação defensiva.
- Expansão da private beta do Aardvark, um agente de investigação de segurança, como primeira oferta de uma suite de produtos e ferramentas Codex Security.
- Parcerias com maintainers open source para oferecer scanning gratuito a projetos amplamente usados (ex.: Next.js), citando um caso recente onde um investigador de segurança usou o Codex para encontrar vulnerabilidades que foram divulgadas: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
Além do programa de bolsas de 2023 (US$1M), a OpenAI também comunica um compromisso adicional: US$10M em créditos de API para acelerar defesa cibernética com os seus modelos mais capazes, com foco especial em software open source e sistemas de infraestrutura crítica. Organizações envolvidas em investigação de segurança de boa fé podem candidatar-se a créditos e suporte via o Cybersecurity Grant Program.
Disponibilidade, velocidade e infraestrutura
Em termos de acesso, o GPT‑5.3‑Codex está disponível em planos pagos do ChatGPT e em todo o sítio onde o Codex existe: app, CLI, extensão de IDE e web. A OpenAI diz que está a trabalhar para ativar acesso via API “em breve”, com segurança.
O update também inclui uma melhoria de performance operacional: a OpenAI afirma estar a correr o GPT‑5.3‑Codex 25% mais rápido para utilizadores do Codex, graças a melhorias na infraestrutura e no inference stack, trazendo interações e resultados mais rápidos.
A nível de hardware, o GPT‑5.3‑Codex foi co-desenhado, treinado e servido em NVIDIA GB200 NVL72. A OpenAI agradece explicitamente a parceria com a NVIDIA.
O que os números do apêndice dizem (benchmarks e configurações)
No apêndice, a OpenAI publica uma tabela com métricas lado a lado para GPT‑5.3‑Codex (xhigh), GPT‑5.2‑Codex (xhigh) e GPT‑5.2 (xhigh). Estes são os valores apresentados:
- SWE‑Bench Pro (Public): 56.8% (GPT‑5.3‑Codex) vs 56.4% (GPT‑5.2‑Codex) vs 55.6% (GPT‑5.2)
- Terminal‑Bench 2.0: 77.3% vs 64.0% vs 62.2%
- OSWorld‑Verified: 64.7% vs 38.2% vs 37.9%
- GDPval (wins or ties): 70.9% (GPT‑5.3‑Codex) | (sem valor indicado para GPT‑5.2‑Codex) | 70.9% (high) (GPT‑5.2)
- Cybersecurity Capture The Flag Challenges: 77.6% vs 67.4% vs 67.7%
- SWE‑Lancer IC Diamond: 81.4% vs 76.0% vs 74.6%
Nota sobre as avaliações
A OpenAI indica em rodapé que todas as avaliações no blog foram executadas no GPT‑5.3‑Codex com xhigh reasoning effort.
Try it: download da Codex app
O anúncio inclui um link direto para experimentar o Codex via app (macOS):
Codex app (macOS) – downloadO que vem a seguir (segundo o anúncio)
O framing final da OpenAI é que, com o GPT‑5.3‑Codex, o Codex está a evoluir de “escrever código” para usar código como ferramenta para operar o computador e concluir trabalho end‑to‑end. Ao empurrar o limite do que um coding agent consegue fazer, abre-se espaço para uma classe mais ampla de trabalho de conhecimento – desde construir e deployar software até pesquisar, analisar e executar tarefas complexas.
O que começou como uma aposta em ser o melhor agente de coding é descrito como base para um colaborador mais geral no computador, expandindo quem consegue construir e o que é possível fazer com o Codex.



Referências / Fontes
Inês Silva
Editora da equipa portuguesa, especialista em SEO e otimização de performance. Core Web Vitals e Lighthouse são os meus favoritos. Sites rápidos, utilizadores felizes.
Todos os posts