

GPT-5.3-Codex: What Changes When Your Coding Agent Can Run the Whole Computer
OpenAI has introduced GPT-5.3-Codex, positioning it as its most capable agentic coding model so far-meaning it’s built not only to write code, but to plan, use tools, and execute multi-step tasks over long time horizons. The headline claim is a step-change from “coding assistant” to “general-purpose computer collaborator,” with enough speed and context-handling to stay useful while it works for hours (or days) on complex builds.
What makes this release particularly notable is that GPT-5.3-Codex was reportedly instrumental in creating itself: OpenAI’s Codex team used early versions to debug training, manage deployment, and interpret evaluations. That feedback loop-using the agent to improve the agent-is a big signal about how seriously OpenAI is leaning into agent-driven engineering workflows.
Frontier agentic capabilities: what OpenAI is benchmarking
OpenAI highlights four benchmarks to describe GPT-5.3-Codex’s “real work” profile-covering coding, terminal fluency, computer-use in a desktop environment, and professional knowledge work. The model is described as both more capable than GPT-5.2-Codex on frontier coding tasks and as combining the reasoning + professional knowledge strengths of GPT-5.2 into a single model.
They also emphasize a practical detail developers will care about: GPT-5.3-Codex achieves its results with fewer tokens than prior models, which generally translates to lower overhead for long sessions and more room for iteration inside fixed budgets.
Coding: SWE-Bench Pro and Terminal-Bench 2.0
On the software engineering side, OpenAI points to SWE-Bench Pro as the key proof point. Unlike SWE-bench Verified (which only tests Python), SWE-Bench Pro spans four languages and is designed to be more contamination-resistant, more diverse, and more representative of industry codebases.
They also report a major jump on Terminal-Bench 2.0, which targets the “agent in a terminal” skillset: navigating repos, running commands, interpreting output, making changes, rerunning tests, and iterating until a task is actually complete.
Web development: long-running, autonomous iteration
Beyond unit tasks, OpenAI tested GPT-5.3-Codex on long-running agent workflows by having it build and iterate on two web games using a “develop web game” skill and generic follow-up prompts such as “fix the bug” or “improve the game.” The key detail here is duration and scale: the model iterated autonomously over millions of tokens across multiple days, which is exactly the regime where weaker agents typically lose coherence or get stuck in shallow loops.
The two example outputs are publicly playable:
- A racing game sequel (v2) with different racers, eight maps, and items triggered via the space bar: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- A diving exploration game with reefs to collect for a “fish codex,” plus oxygen/pressure/hazards management: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
OpenAI also claims better default behavior for “day-to-day website” prompts: if a prompt is simple or underspecified, GPT-5.3-Codex tends to generate more complete starting points with sensible defaults. Their landing-page comparison example calls out two concrete improvements: displaying yearly pricing as a discounted monthly equivalent (instead of just multiplying the annual total), and generating a testimonial carousel that actually contains three distinct testimonials by default.
Beyond coding: professional knowledge work (GDPval)
A recurring theme in the announcement is that modern software work is wider than code-PRDs, testing strategy, deployment, monitoring, copy edits, user research summaries, metrics analysis, and so on. GPT-5.3-Codex is presented as an agent for the whole lifecycle, and even broader “knowledge work” tasks like building slides or manipulating spreadsheets.
To quantify this, OpenAI references GDPval, an evaluation it released in 2025 that measures performance on well-specified knowledge-work tasks across 44 occupations. GPT-5.3-Codex is reported to match GPT-5.2 on GDPval (wins or ties), suggesting OpenAI’s goal here is consolidation: frontier coding + strong professional output in one model.
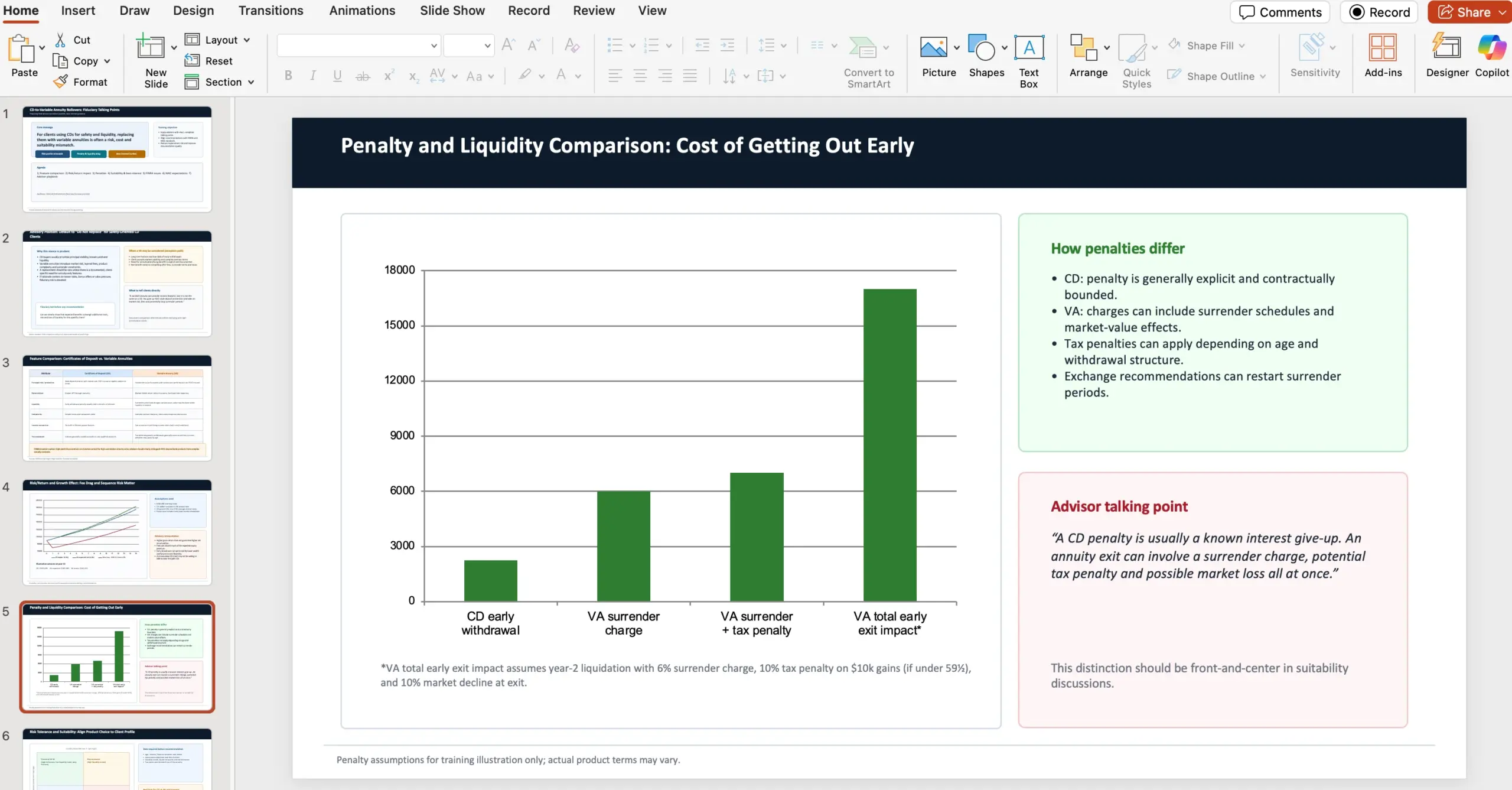
Example prompt: fiduciary guidance deck (variable annuities vs CDs)
One showcased GDPval-style task asks the agent (in the role of a financial advisor at a wealth management firm) to create a 10-slide PowerPoint explaining why advisors, acting as fiduciaries, should recommend against rolling certificates of deposits into variable annuities despite the appeal of market returns + lifetime monthly payments.
The task includes specific content requirements:
- Compare features between CDs and variable annuities, sourcing caution guidance from FINRA
- Compare risk/return analysis and the effect on growth
- Distinguish penalty differences between the two vehicles
- Contrast risk tolerance and suitability, sourcing from NAIC Best Interest Regulations
- Highlight FINRA concerns/issues
- Highlight NAIC issues/regulations
- Acknowledge that NAIC and FINRA have established best interest and suitability guidelines for variable annuity recommendations due to product complexity
And it explicitly provides source URLs to consult while drafting:
- https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf
- https://www.finra.org/investors/insights/high-yield-cds
Computer use: OSWorld
OpenAI also points to OSWorld, a benchmark where an agent must complete productivity tasks in a visual desktop environment (i.e., real computer-use: clicking, typing, navigating UI, managing files). GPT-5.3-Codex is described as substantially stronger than prior GPT models on OSWorld-Verified, which uses vision-based task completion. OpenAI notes human performance is around ~72% on this benchmark, providing a real-world anchor for what “good” looks like.
An interactive collaborator: steering while it works
A practical shift in agent workflows is moving from “wait for a final answer” to “supervise a process.” OpenAI frames the key bottleneck as interaction: once agents get powerful, the challenge becomes directing and supervising multiple agents in parallel without losing context.
With GPT-5.3-Codex inside the Codex app, the focus is on continuous collaboration: the agent provides frequent updates, explains key decisions, and supports real-time steering-so you can ask questions, change direction, and converge on the target without restarting the whole run.
If you want that behavior enabled, OpenAI points to a specific setting in the Codex app: Settings > General > Follow-up behavior (enable steering while the model works).
How OpenAI used Codex to train and deploy GPT-5.3-Codex
The most “engineering-culture” part of the announcement is how explicitly OpenAI describes using Codex internally across research, infra, and product launch operations. The claim is that rapid improvements are built on longer research arcs across OpenAI-but those arcs are now being accelerated by Codex enough that many researchers and engineers describe their day-to-day as fundamentally different even compared to two months earlier.
Research workflows: monitoring, debugging, and analysis tooling
On the research side, Codex was used to monitor and debug the training run itself, but also to do higher-level work: tracking patterns during training, analyzing interaction quality, proposing fixes, and building richer internal apps so human researchers could compare behavioral differences against prior models with more precision.
Engineering workflows: harness optimization and production edge cases
On the engineering side, OpenAI says Codex helped optimize and adapt the evaluation/serving harness for GPT-5.3-Codex. When odd edge cases surfaced that impacted users, team members used Codex to identify context rendering bugs and trace low cache hit rates to root causes.
They also describe a very “agentic ops” use: during launch, GPT-5.3-Codex helped keep the service stable by dynamically scaling GPU clusters to respond to traffic surges while keeping latency stable.
Alpha insights: measuring “work per turn” with lightweight classifiers
During alpha testing, a researcher wanted a quantitative view of how much additional work the new model completed “per turn” and how that affected productivity. GPT-5.3-Codex proposed several simple regex-based classifiers to estimate things like:
- Frequency of clarifications
- Positive vs negative user responses
- Progress on the task
It then ran these at scale across session logs and produced a report. The conclusion OpenAI highlights: people building with Codex were happier because the agent better understood intent, made more progress per turn, and asked fewer clarifying questions.
Data science workflows: richer pipelines and co-analysis
Because GPT-5.3-Codex differed significantly from predecessors, alpha data produced “unusual and counter-intuitive” results. OpenAI describes a data scientist collaborating with the model to build new pipelines and visualizations beyond what standard dashboards provided, then co-analyzing results where Codex summarized key insights across thousands of data points in under three minutes.
Securing the cyber frontier: stronger capabilities, stronger controls
OpenAI ties this release to recent improvements on cybersecurity tasks, explicitly treating cybersecurity as dual-use: the same capabilities that help defenders find and fix vulnerabilities can also be misused. Alongside capability gains, OpenAI says it has been preparing strengthened safeguards to support defensive usage and broader ecosystem resilience.
Two classification details matter here:
- GPT-5.3-Codex is the first model OpenAI classifies as “High capability” for cybersecurity-related tasks under its Preparedness Framework.
- It’s also the first model OpenAI says it has directly trained to identify software vulnerabilities.
Precautionary deployment posture
OpenAI says it does not have definitive evidence GPT-5.3-Codex can automate cyber attacks end-to-end, but is taking a precautionary approach by deploying its most comprehensive cybersecurity safety stack to date.
The mitigations OpenAI lists include:
- Safety training
- Automated monitoring
- Trusted access for advanced capabilities
- Enforcement pipelines including threat intelligence
On the ecosystem side, OpenAI announces and/or reiterates several programs and partnerships:
- Launching Trusted Access for Cyber, a pilot program intended to accelerate cyber defense research
- Expanding the private beta of Aardvark, described as a security research agent and the first offering in a suite of Codex Security products/tools
- Partnering with open-source maintainers to provide free codebase scanning for widely used projects such as Next.js (with a referenced disclosure summary from Vercel)
- Committing $10M in API credits to accelerate cyber defense work with its most capable models, especially for open source and critical infrastructure
- Continuing support via the OpenAI Cybersecurity Grant Program (building on the $1M program launched in 2023), where good-faith security research orgs can apply for credits and support
Availability & performance details
GPT-5.3-Codex is available with paid ChatGPT plans anywhere Codex is accessible today: the Codex app, CLI, IDE extension, and web. OpenAI says it is working to safely enable API access soon.
OpenAI also claims a concrete infra win: for Codex users, GPT-5.3-Codex is running 25% faster, credited to improvements in infrastructure and the inference stack-aimed at faster interactions and faster overall completion times for longer jobs.
On hardware, OpenAI notes the model was co-designed for, trained with, and served on NVIDIA GB200 NVL72 systems.
The appendix numbers (so you don’t have to hunt them down)
OpenAI includes a compact table of benchmark results comparing GPT-5.3-Codex (xhigh) against GPT-5.2-Codex (xhigh) and GPT-5.2 (xhigh):
- SWE-Bench Pro (Public): 56.8% (GPT-5.3-Codex) vs 56.4% (GPT-5.2-Codex) vs 55.6% (GPT-5.2)
- Terminal-Bench 2.0: 77.3% vs 64.0% vs 62.2%
- OSWorld-Verified: 64.7% vs 38.2% vs 37.9%
- GDPval (wins or ties): 70.9% vs – vs 70.9% (high)
- Cybersecurity Capture The Flag Challenges: 77.6% vs 67.4% vs 67.7%
- SWE-Lancer IC Diamond: 81.4% vs 76.0% vs 74.6%
Evaluation setting note
OpenAI notes that all evaluations in the announcement were run on GPT-5.3-Codex with xhigh reasoning effort.
What “Codex as a computer collaborator” means for dev teams
The through-line in OpenAI’s messaging is that code generation is becoming a smaller part of the story. GPT-5.3-Codex is framed as an agent that can operate the computer, not just draft code: research a library, edit files, run the build, inspect logs, fix issues, update docs, prepare a release, and keep going across long sessions while you supervise.
If the interaction loop in the Codex app holds up under real workload pressure, this is the kind of model that fits into an engineering org less like “autocomplete,” and more like a junior teammate that can execute well-scoped workstreams-while you stay responsible for direction, review, and security posture.



Emma Richardson
UI/UX designer and frontend developer. React and the modern JavaScript ecosystem are my expertise. Passionate about user experience and accessibility.
All posts

