GPT-5.3-Codex: Wenn Codex vom Coding-Agent zum Computer-Kollegen wird
OpenAI hat am 5. Februar 2026 GPT‑5.3‑Codex vorgestellt – ein Modell, das Codex deutlich breiter aufstellt als „nur“ Code schreiben und Review machen. Die Ansage ist klar: Codex soll nicht mehr bloß ein Coding‑Agent sein, sondern ein Agent, der nahezu alles erledigen kann, was Entwickler:innen und andere Professionals am Computer tun – inklusive Recherche, Tool‑Nutzung und komplexer Ausführung über längere Zeiträume.
Technisch spannend ist die Kombination aus zwei Linien: GPT‑5.3‑Codex bringt sowohl die Frontier‑Coding‑Performance aus der GPT‑5.2‑Codex‑Richtung als auch die Reasoning‑ und Professional‑Knowledge‑Stärken von GPT‑5.2 zusammen – und läuft laut OpenAI dabei 25% schneller. Das ist gerade dann relevant, wenn Agenten über viele Schritte iterieren, Logfiles durchkämmen, Tests anwerfen oder sich durch ein Projektverzeichnis und mehrere Tools arbeiten müssen.
Frontier-Agentic-Capabilities: Benchmarks, die mehr als nur „kann Code“ messen
OpenAI positioniert GPT‑5.3‑Codex als aktuell „fähigstes agentisches Coding‑Modell“ und verweist auf starke Ergebnisse in vier Benchmarks, die sie intern nutzen, um Coding‑, Agentic‑ und Real‑World‑Fähigkeiten einzuordnen: SWE‑Bench Pro, Terminal‑Bench, OSWorld und GDPval.
Coding: SWE‑Bench Pro und Terminal‑Bench 2.0
Bei SWE‑Bench Pro spricht OpenAI von State‑of‑the‑Art. Der wichtige Kontext: Während „SWE‑bench Verified“ nur Python testet, deckt SWE‑Bench Pro vier Sprachen ab und soll gleichzeitig kontaminationsresistenter, herausfordernder, diverser und industrierelevanter sein. Für uns als Web‑Dev‑Community ist das ein entscheidender Punkt: Es geht nicht um synthetische Puzzle‑Aufgaben, sondern um näher an der Realität liegende Software‑Engineering‑Arbeit.
Zusätzlich hebt OpenAI Terminal‑Bench 2.0 hervor – ein Benchmark, der gezielt Terminal‑Skills misst, die ein Agent wie Codex in der Praxis braucht (z. B. Navigieren, Ausführen, Interpretieren, Fixen). Bemerkenswert: GPT‑5.3‑Codex erreicht diese Werte laut OpenAI mit weniger Tokens als frühere Modelle, was in der Praxis bedeutet, dass mehr „Budget“ für tatsächliche Arbeit übrig bleibt.
Webentwicklung: Langläufer-Aufgaben über Millionen Tokens
Für Webentwicklung und „long‑running agentic capabilities“ hat OpenAI einen praxisnäheren Test gewählt: GPT‑5.3‑Codex sollte zwei Browser‑Games bauen und über längere Zeit weiterentwickeln – mit einem vordefinierten Skill („develop web game“) und generischen Folgeprompts wie „fix the bug“ oder „improve the game“. Das Modell iterierte dabei autonom über Millionen Tokens und soll die Games über Tage hinweg von Grund auf zu komplexen, funktionalen Apps ausgebaut haben – inklusive besserer Ästhetik und Kompaktheit („compaction“).
- Racing Game v2: mehrere Fahrer, acht Maps und Items, die per Spacebar genutzt werden können. Spielbar unter: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Diving Game: Riffe erkunden, sammeln, um ein „Fish Codex“ zu vervollständigen; gleichzeitig Sauerstoff, Druck und Gefahren managen. Spielbar unter: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Außerdem claimt OpenAI, dass GPT‑5.3‑Codex im Alltags‑Webdesign Absichten besser versteht als GPT‑5.2‑Codex. Unter-spezifizierte Prompts sollen häufiger zu Seiten führen, die sofort mehr sinnvolle Defaults mitbringen. Das Beispiel im Post: Bei einer Landing‑Page‑Aufgabe hat GPT‑5.3‑Codex automatisch eine Jahresoption als rabattierten Monatsbetrag dargestellt (statt schlicht den Jahrestotalbetrag zu verteilen) und zusätzlich ein automatisch rotierendes Testimonial‑Carousel mit drei unterschiedlichen Quotes erzeugt – also ein „production‑ready“ wirkenderes Ergebnis ohne extra Prompting.
Beyond Coding: Wissenarbeit und „Computer Use“
Ein wichtiger Teil der Ankündigung: GPT‑5.3‑Codex soll nicht nur Engineers unterstützen, sondern den gesamten Software‑Lifecycle abdecken – Debugging, Deploying, Monitoring, PRDs schreiben, Copy bearbeiten, User Research, Tests, Metrics und mehr. Und es endet nicht bei Software: Der Agent soll auch in klassischen Knowledge‑Work‑Artefakten helfen – von Slide‑Decks bis zu Spreadsheet‑Analysen.
Hier taucht GDPval auf: eine 2025 veröffentlichte Evaluation, die die Performance auf gut spezifizierten Knowledge‑Work‑Tasks über 44 Berufe misst. OpenAI schreibt, GPT‑5.3‑Codex zeige dort (mit Custom Skills wie in früheren GDPval‑Ergebnissen) starke Performance und matcht GPT‑5.2 in GDPval.
Daneben ist OSWorld zentral: ein agentischer Computer‑Use‑Benchmark, bei dem der Agent Produktivitätsaufgaben in einer visuellen Desktop‑Umgebung erledigen muss. OpenAI sagt, GPT‑5.3‑Codex zeige dort deutlich stärkere Computer‑Use‑Fähigkeiten als frühere GPT‑Modelle.
Ein interaktiver Kollaborateur: Arbeiten, während der Agent arbeitet
Mit leistungsfähigeren Agenten verschiebt sich das Problem laut OpenAI zunehmend: weniger „kann der Agent das?“, mehr „wie gut kann ich mehrere Agenten parallel steuern und überwachen?“. Genau hier setzt die Codex‑App an – und GPT‑5.3‑Codex soll das Interaktionsmodell nochmals verbessern.
- Codex liefert häufigere Updates, damit du wichtige Entscheidungen und Fortschritt während der Ausführung nachvollziehen kannst.
- Statt nur auf ein finales Ergebnis zu warten, kannst du in Echtzeit eingreifen: Fragen stellen, Ansätze diskutieren, Richtung ändern.
- GPT‑5.3‑Codex „spricht“ durch, was es tut, reagiert auf Feedback und hält dich von Anfang bis Ende auf dem Laufenden.
Wichtiges Detail für die Praxis: Das „Steering while the model works“ lässt sich in der App aktivieren über Settings > General > Follow-up behavior.
Wie OpenAI Codex genutzt hat, um GPT‑5.3‑Codex zu trainieren und zu deployen
Der bemerkenswerteste Teil der Story ist fast schon meta: GPT‑5.3‑Codex ist laut OpenAI das erste Modell, das „instrumental“ dabei war, sich selbst zu erschaffen. Das Codex‑Team nutzte frühe Versionen, um das eigene Training zu debuggen, Deployments zu managen sowie Testergebnisse und Evaluations zu diagnostizieren – und war laut OpenAI selbst überrascht, wie stark Codex die eigene Entwicklung beschleunigt.
OpenAI betont, dass die schnellen Verbesserungen Ergebnis von Forschungsprojekten sind, die über Monate oder Jahre liefen – aber dass diese Projekte inzwischen durch Codex nochmals schneller vorankommen. Einige Teams beschreiben laut OpenAI, dass sich ihr Job heute fundamental von dem unterscheidet, was sie „vor zwei Monaten“ gemacht haben.
Konkrete Beispiele aus Research und Engineering
- Research: Codex wurde genutzt, um Trainingsläufe für dieses Release zu monitoren und zu debuggen – nicht nur Infrastrukturprobleme, sondern auch Muster über den Trainingsverlauf hinweg.
- Research: Codex lieferte Deep‑Analysen zur Interaction Quality, schlug Fixes vor und baute reichhaltige Apps, um Unterschiede im Modellverhalten gegenüber Vorgängern präzise sichtbar zu machen.
- Engineering: Codex half, den Harness (Test-/Ausführungsrahmen) für GPT‑5.3‑Codex zu optimieren und anzupassen.
- Engineering: Bei ungewöhnlichen Edge‑Cases wurden mit Codex Context‑Rendering‑Bugs identifiziert sowie die Ursache für niedrige Cache‑Hit‑Rates analysiert.
- Launch-Betrieb: GPT‑5.3‑Codex hilft während des Launches, GPU‑Cluster dynamisch zu skalieren, auf Traffic‑Spitzen zu reagieren und die Latenz stabil zu halten.
Alpha-Testing: Produktivität messbar machen
Im Alpha‑Testing wollte ein Researcher quantifizieren, wie viel zusätzliche Arbeit GPT‑5.3‑Codex „pro Turn“ erledigt – und wie sich Produktivität verändert. Laut OpenAI hat GPT‑5.3‑Codex dafür mehrere einfache Regex‑Classifier entworfen, um in Session‑Logs u. a. Folgendes zu schätzen: Häufigkeit von Klarstellungen, positive/negative User‑Antworten und Task‑Progress. Diese Classifier wurden dann skalierbar über die Logs gefahren und als Report zusammengefasst.
Die daraus gezogenen Beobachtungen: Teams, die mit Codex bauen, waren zufriedener, weil der Agent die Intent besser verstand, pro Turn mehr Fortschritt machte und weniger Rückfragen stellte.
Weil GPT‑5.3‑Codex sich deutlich von den Vorgängern unterscheidet, gab es in den Alpha‑Daten laut OpenAI viele ungewöhnliche, kontraintuitive Ergebnisse. Eine Data Scientist arbeitete mit GPT‑5.3‑Codex daran, neue Data Pipelines zu bauen und Resultate reichhaltiger zu visualisieren als es Standard‑Dashboarding hergab. Die Co‑Analyse mit Codex endete in einer kompakten Zusammenfassung zentraler Insights über tausende Datenpunkte in unter drei Minuten.
Cybersecurity: „High capability“ und eine verschärfte Safety-Stack-Strategie
OpenAI berichtet über spürbare Performance‑Gewinne bei Cybersecurity‑Tasks in den letzten Monaten – relevant sowohl für Entwickler:innen als auch Security‑Teams. Parallel hat OpenAI laut Post an verstärkten Cyber‑Safeguards gearbeitet, um defensive Nutzung zu unterstützen und die Resilienz des Ökosystems zu erhöhen.
GPT‑5.3‑Codex ist dabei ein Einschnitt: Es ist das erste Modell, das OpenAI unter dem Preparedness Framework als „High capability“ für cybersecurity‑bezogene Aufgaben klassifiziert, und gleichzeitig das erste, das direkt darauf trainiert wurde, Software‑Vulnerabilities zu identifizieren.
OpenAI schreibt auch sehr explizit: Man habe keinen definitiven Nachweis, dass das Modell Cyberangriffe end‑to‑end automatisieren kann – trotzdem fährt OpenAI einen vorsorglichen Ansatz und deployt die bisher umfassendste Cybersecurity‑Safety‑Stack‑Variante. Genannt werden:
- Safety Training
- Automated Monitoring
- Trusted Access für fortgeschrittene Capabilities
- Enforcement Pipelines inklusive Threat Intelligence
Weil Cybersecurity inhärent Dual‑Use ist, will OpenAI evidenzbasiert und iterativ vorgehen: Defender schneller machen beim Finden und Fixen von Schwachstellen, Missbrauch aber bremsen. Dazu startet OpenAI Trusted Access for Cyber als Pilotprogramm, um Cyber‑Defense‑Research zu beschleunigen.
Zusätzlich investiert OpenAI in „Ecosystem Safeguards“: Die private Beta von Aardvark (Security‑Research‑Agent) wird erweitert – als erstes Angebot in einer Suite von Codex Security‑Produkten und Tools. Außerdem nennt OpenAI Partnerschaften mit Open‑Source‑Maintainers, um kostenloses Codebase‑Scanning für weit verbreitete Projekte bereitzustellen, z. B. Next.js. Als Beleg wird ein Fall genannt, in dem ein Security‑Researcher mit Codex Schwachstellen fand, die laut Quelle letzte Woche disclosed wurden.
Finanziell baut OpenAI zudem auf dem $1M Cybersecurity Grant Program (gestartet 2023) auf und commitet zusätzlich $10M in API Credits, um Cyber‑Defense mit den fähigsten Modellen zu beschleunigen – besonders für Open Source und kritische Infrastruktursysteme. Organisationen, die „good‑faith“ Security‑Research betreiben, können API Credits und Support über das Cybersecurity‑Grant‑Programm beantragen.
Verfügbarkeit & technische Details
GPT‑5.3‑Codex ist laut OpenAI in bezahlten ChatGPT‑Plänen verfügbar – überall dort, wo man Codex nutzen kann: App, CLI, IDE‑Extension und Web. API Access ist noch nicht allgemein freigeschaltet; OpenAI schreibt, man arbeite daran, ihn „bald“ sicher zu ermöglichen.
Mit dem Update läuft GPT‑5.3‑Codex für Codex‑User 25% schneller, begründet durch Verbesserungen in Infrastruktur und Inference‑Stack. Praktisch heißt das: schnellere Interaktionen und schnellere Ergebnisse – gerade bei agentischen Loops ein spürbarer Multiplikator.
Hardwareseitig wurde GPT‑5.3‑Codex laut OpenAI co‑designed, trainiert und serviert auf NVIDIA GB200 NVL72‑Systemen; OpenAI bedankt sich ausdrücklich für die Partnerschaft mit NVIDIA.
Was OpenAI als nächsten Schritt sieht
OpenAI beschreibt die Richtung als klaren Shift: Mit GPT‑5.3‑Codex geht Codex „beyond writing code“ – Code wird zum Tool, um den Computer zu bedienen und Arbeit end‑to‑end zu erledigen. Das soll nicht nur Software‑Build‑und‑Deploy‑Workflows verbessern, sondern auch eine breitere Klasse von Knowledge‑Work erschließen: recherchieren, analysieren, ausführen – inklusive komplexer Aufgabenketten.
Aus einem Projekt, das als „bester Coding‑Agent“ gestartet ist, wird damit laut OpenAI die Grundlage für einen allgemeineren „Collaborator“ am Computer – und erweitert sowohl, wer bauen kann, als auch, was mit Codex möglich wird.
Appendix: Alle im Post genannten Benchmarkwerte (xhigh)
OpenAI listet im Anhang eine Tabelle mit Ergebnissen für drei Modelle. Alle Evaluations wurden laut Fußnote mit xhigh reasoning effort für GPT‑5.3‑Codex ausgeführt.
- SWE‑Bench Pro (Public): GPT‑5.3‑Codex (xhigh) 56.8% · GPT‑5.2‑Codex (xhigh) 56.4% · GPT‑5.2 (xhigh) 55.6%
- Terminal‑Bench 2.0: GPT‑5.3‑Codex (xhigh) 77.3% · GPT‑5.2‑Codex (xhigh) 64.0% · GPT‑5.2 (xhigh) 62.2%
- OSWorld‑Verified: GPT‑5.3‑Codex (xhigh) 64.7% · GPT‑5.2‑Codex (xhigh) 38.2% · GPT‑5.2 (xhigh) 37.9%
- GDPval (wins or ties): GPT‑5.3‑Codex (xhigh) 70.9% · GPT‑5.2‑Codex (xhigh) – · GPT‑5.2 (xhigh) 70.9% (high)
- Cybersecurity Capture The Flag Challenges: GPT‑5.3‑Codex (xhigh) 77.6% · GPT‑5.2‑Codex (xhigh) 67.4% · GPT‑5.2 (xhigh) 67.7%
- SWE‑Lancer IC Diamond: GPT‑5.3‑Codex (xhigh) 81.4% · GPT‑5.2‑Codex (xhigh) 76.0% · GPT‑5.2 (xhigh) 74.6%
Codex-App: Direkt ausprobieren
Codex app (macOS) herunterladen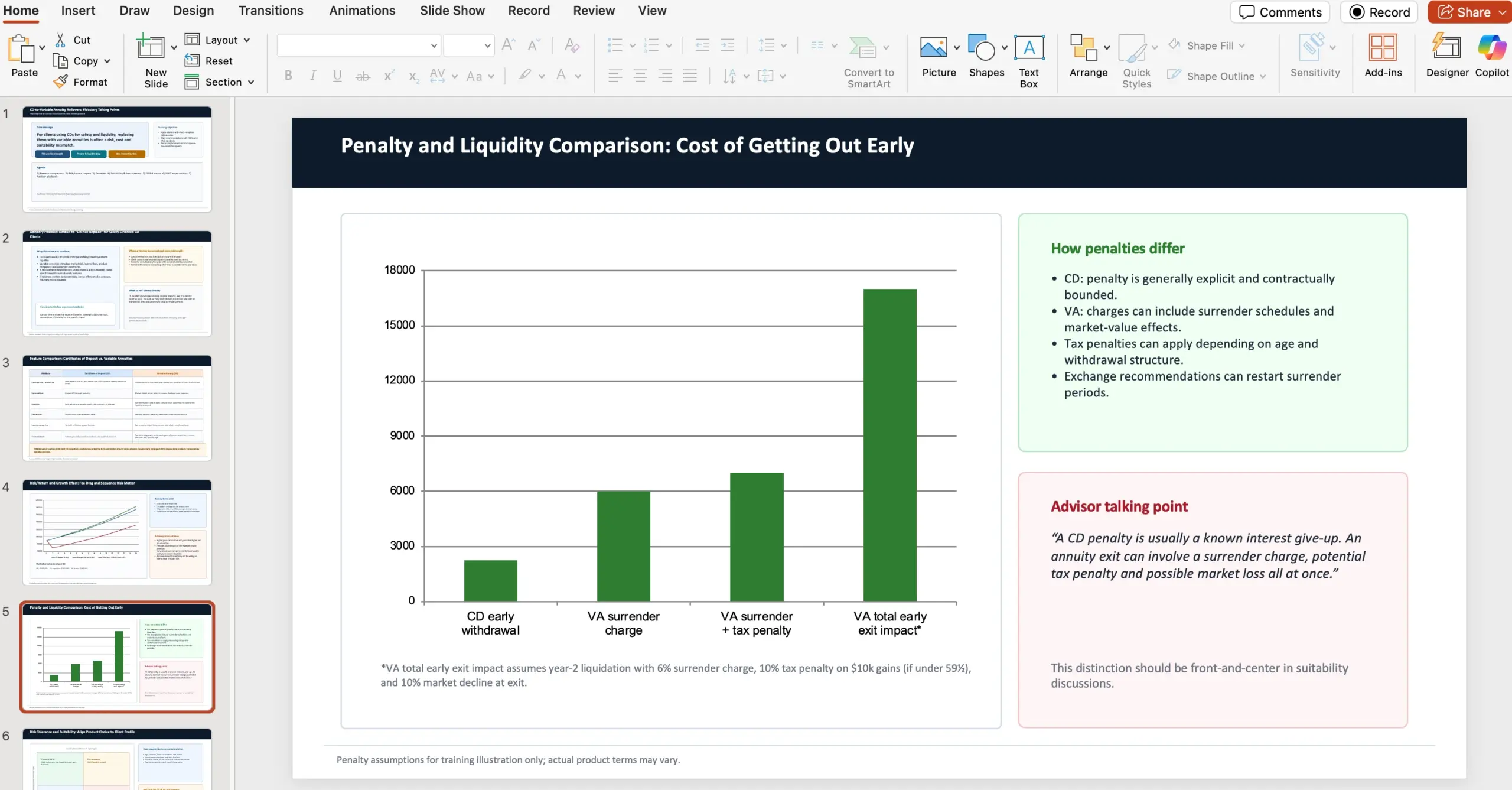



Referenzen / Quellen
Julia Schneider
Leiterin der deutschen Redaktion, Softwarearchitektin und technische Mentorin. Java- und Spring-Framework-Expertin. Präzision und Qualität über alles.
Alle Beiträge