GPT-5.3-Codex: Codex går fra kodeagent til fuld computerkollega
OpenAI har præsenteret GPT‑5.3‑Codex som den hidtil mest kapable agentic (agent-baserede) coding-model i Codex-familien. Det, der gør lanceringen interessant for os som webudviklere, er ikke kun, at den skriver og reviewer kode bedre – men at den i stigende grad kan agere som en “computer-kollega”: researche, bruge værktøjer, køre kommandoer, følge op på fejl, og holde en opgave kørende i lang tid uden at miste kontekst.
Ifølge OpenAI kombinerer GPT‑5.3‑Codex frontier coding-performance fra GPT‑5.2‑Codex med ræsonnering og professionel viden fra GPT‑5.2 i én model – og den kører samtidig 25% hurtigere. Det gør en forskel i praksis, fordi lange agent-forløb ofte er begrænset af latency og interaktionsomkostning mere end “rå IQ”.
En ekstra detalje, der skiller sig ud: GPT‑5.3‑Codex er den første model, OpenAI beskriver som værende med til at skabe sig selv. Codex-teamet brugte tidlige versioner til at debugge træningen, håndtere deployment og diagnosticere test- og evalueringsresultater. Med andre ord: agenten blev et aktiv i sin egen udviklingspipeline.
Frontier agentic capabilities: hvorfor benchmark-snakken faktisk betyder noget
OpenAI fremhæver især fire benchmarks til at måle coding, agentic og real-world evner: SWE‑Bench Pro, Terminal‑Bench, OSWorld og GDPval. Pointen er ikke bare “højere score”, men at modellen ser ud til at være mere alsidig på tværs af software engineering, terminal-arbejde og almindelige computeropgaver.
Coding: SWE‑Bench Pro og Terminal‑Bench 2.0
På SWE‑Bench Pro sætter GPT‑5.3‑Codex ifølge OpenAI en ny industri-høj. SWE‑Bench Pro er tænkt som en mere robust og industrirelevant måling end SWE‑bench Verified: hvor Verified kun tester Python, spænder Pro over fire sprog, og den er designet til at være mere modstandsdygtig over for contamination (at en model har set opgaverne eller løsningerne før).
Derudover overgår den tidligere state-of-the-art på Terminal‑Bench 2.0, som specifikt måler de terminalfærdigheder en coding-agent har brug for (tænk: navigere projekter, køre kommandoer, håndtere output og iterere). En detalje OpenAI selv fremhæver: GPT‑5.3‑Codex klarer resultaterne med færre tokens end tidligere modeller, hvilket i praksis kan betyde, at du får mere “byggearbejde” for samme interaktionsbudget.
Webudvikling: lange autonome forløb og bedre defaults
Der er også et tydeligt webudviklingsspor i lanceringen. OpenAI beskriver en kombination af (1) frontier coding-evner, (2) bedre æstetik og (3) compaction (komprimering af adfærd/evner i modellen) som årsag til, at GPT‑5.3‑Codex kan bygge mere komplette apps og spil fra bunden over flere dage.
For at teste netop webdev + long-running agentic kapacitet bad de modellen om at bygge to spil: en version 2 af et racing game (kendt fra Codex app-lanceringen) og et dykker-spil. De brugte en “develop web game”-skill (en specialiseret evne/arbejdsgang i Codex) og nogle forudvalgte, generiske follow-up prompts som fx “fix the bug” eller “improve the game”. Modellen itererede derefter autonomt over millioner af tokens.
- Racing game: flere racers, otte maps, og items der aktiveres med space bar. Spil det her: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Diving game: udforsk rev, saml dem for at fuldføre din fish codex, og styr ilt, tryk og hazards. Spil det her: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
I mere hverdagsnære webopgaver påstår OpenAI også, at GPT‑5.3‑Codex bedre forstår intentionen bag prompts, når du beder om “dagligdags websites”. Under-specificerede prompts ender oftere med sider, der har mere funktionalitet og mere fornuftige defaults – altså et bedre udgangspunkt, før du begynder at finpudse.
De giver et konkret eksempel med to landing pages, hvor GPT‑5.3‑Codex bl.a. (a) viste en årsplan som en nedsat månedspris, så rabatten fremstod bevidst og tydelig, frem for blot at gange en årspris ud, og (b) lavede en testimonial carousel der auto-transitioner og indeholder tre forskellige citater i stedet for ét. Det er præcis den slags “produkt-færdige” detaljer, som ellers typisk først kommer i en anden eller tredje iteration, hvis man starter fra en mere rå skabelon.
Beyond coding: hele software-livscyklussen (og mere)
OpenAIs framing er, at softwarefolk ikke kun genererer kode. Derfor er GPT‑5.3‑Codex bygget til at støtte arbejde på tværs af livscyklussen: debugging, deploying, monitoring, skrive PRDs, redigere copy, user research, tests, metrics osv. Og agentic-delen rækker ud over software: fx at bygge slide decks eller analysere data i sheets.
Her kobler de det til GDPval, en evaluering OpenAI lancerede i 2025, som måler performance på veldefinerede knowledge-work opgaver på tværs af 44 professioner. OpenAI skriver, at GPT‑5.3‑Codex – med custom skills på linje med dem, de brugte for tidligere GDPval-resultater – matcher GPT‑5.2 på GDPval (altså videnarbejde), samtidig med at den løfter agent- og coding-delen.
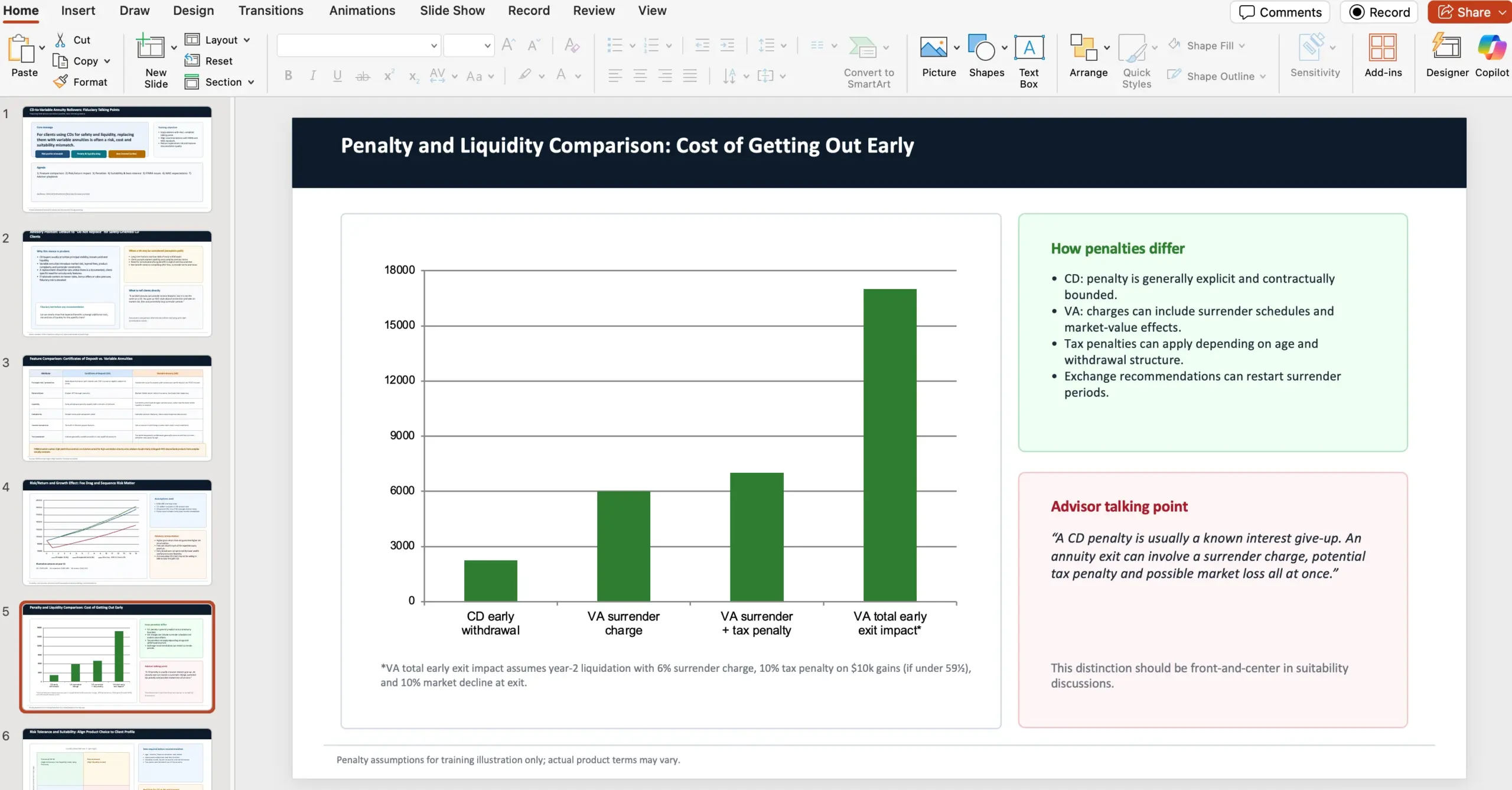
Eksempel: finansrådgiver-opgave (prompt + kontekst)
Et af deres GDPval-eksempler er en opgave, hvor agenten skal agere finansrådgiver i en wealth management-kontekst og lave en 10-slide PowerPoint til interne field advisors. Målet er at forklare, hvorfor man som fiduciary bør fraråde at rulle certificates of deposits over i variable annuities, selvom tilbuddet kan virke tillokkende pga. markedsafkast og livslang månedlig udbetaling.
Præsentationen skulle bl.a. dække:
- Sammenligning af features mellem certificates of deposits og variable annuities med investor-advarsler (sourced af FINRA)
- Risk/return-analyse og effekt på vækst
- Forskelle i penalties mellem de to produkter
- Kontrast i risikotolerance og suitability (sourced af NAIC Best Interest Regulations)
- FINRA concerns/issues
- NAIC issues/regulations
I opgaven bad de også agenten om at tage udgangspunkt i to konkrete webkilder:
- https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf
- https://www.finra.org/investors/insights/high-yield-cds
En vigtig detalje i GDPval-setup’et: OpenAI skriver, at hver opgave er designet af en erfaren fagperson og afspejler reelt videnarbejde i det pågældende job.
På OSWorld (agentic computer-use benchmark i et visuelt desktop-miljø) skriver OpenAI, at GPT‑5.3‑Codex demonstrerer langt stærkere computer-use evner end tidligere GPT-modeller. De nævner også OSWorld-Verified som et regime, hvor modeller bruger vision til at løse varierede computeropgaver, og at mennesker scorer omkring 72%.
Samlet er budskabet: GPT‑5.3‑Codex er ikke kun bedre til enkelte delopgaver, men bevæger sig mod en mere generel agent, der kan ræsonnere, bygge og eksekvere på tværs af “rigtigt arbejde” på en computer.
En interaktiv samarbejdspartner: styring mens agenten arbejder
Når agenters kapacitet vokser, flytter flaskehalsen sig ofte fra “kan modellen?” til “kan vi som mennesker styre og supervisere effektivt?” OpenAI positionerer Codex app’en som svaret på den udfordring – og med GPT‑5.3‑Codex bliver interaktionen mere løbende.
I stedet for at vente på et endeligt resultat, får du ifølge OpenAI hyppige statusopdateringer, så du kan følge nøglebeslutninger og fremdrift. Du kan stille spørgsmål, diskutere tilgang og styre retningen undervejs. Modellen forklarer, hvad den gør, responderer på feedback og holder dig i loopet fra start til slut.
Hvis du vil slå den adfærd til i app’en, peger OpenAI på denne indstilling: Settings > General > Follow-up behavior (idéen er at tillade “steering” under arbejdet).
Sådan brugte OpenAI Codex til at træne og deploye GPT‑5.3‑Codex
OpenAI beskriver de seneste Codex-forbedringer som resultatet af forskningsprojekter, der har kørt i måneder eller år – men som nu bliver accelereret af Codex selv. De skriver direkte, at mange forskere og ingeniører oplever deres job som fundamentalt anderledes end for bare to måneder siden, fordi tidlige versioner af GPT‑5.3‑Codex allerede kunne bidrage til at forbedre træningen og støtte deployment af senere versioner.
De understreger også, at Codex er brugbart på så mange opgavetyper, at det er svært at lave en udtømmende liste. Men de giver en række konkrete eksempler, som er ret genkendelige, hvis du selv har forsøgt at operationalisere en større AI- eller infra-release.
Research: overvågning, debugging og adfærdsanalyse gennem træningsløb
Research-teamet brugte Codex til at overvåge og debugge training runs for releaset. Men ifølge OpenAI var gevinsten ikke kun at løse infra-bugs: Codex hjalp med at spore mønstre gennem hele træningsforløbet, leverede dyb analyse af interaction quality, foreslog fixes, og byggede rige applikationer så menneskelige forskere mere præcist kunne se, hvordan modellens adfærd afveg fra tidligere modeller.
Engineering: harness-optimering, edge cases og cache-problemer
Engineering-teamet brugte Codex til at optimere og tilpasse harness’et (test- og evalueringsharness/infrastruktur) til GPT‑5.3‑Codex. Da de begyndte at se mærkelige edge cases, brugte teammedlemmer Codex til at identificere context rendering-bugs og finde root cause til lave cache hit rates.
OpenAI skriver også, at GPT‑5.3‑Codex fortsat hjælper under launch ved dynamisk at skalere GPU-clusters, så de kan håndtere traffic surges og holde latency stabil.
Alpha: regex-klassifikatorer over session logs og produktivitetsmålinger
Under alpha-test ville en forsker forstå, hvor meget ekstra arbejde GPT‑5.3‑Codex fik lavet per turn, og hvad produktivitetsforskellen var. Ifølge OpenAI foreslog modellen nogle simple regex-klassifikatorer til at estimere:
- Frekvens af clarifications (opklarende spørgsmål)
- Positive user responses
- Negative user responses
- Fremdrift på opgaven
Derefter kørte den analyserne skalerbart over alle session logs og producerede en rapport med konklusioner. Observationen var, at folk, der byggede med Codex, var mere tilfredse, fordi agenten bedre forstod deres intent og gjorde mere fremdrift per turn – med færre opklarende spørgsmål.
Data science: nye pipelines og rigere visualiseringer end standard dashboards
OpenAI nævner også, at fordi GPT‑5.3‑Codex adskilte sig markant fra sine forgængere, viste alpha-data en række usædvanlige og kontraintuitive resultater. En data scientist arbejdede sammen med GPT‑5.3‑Codex for at bygge nye data pipelines og visualisere resultaterne langt rigere, end deres standard dashboarding-værktøjer tillod. Resultaterne blev co-analyseret med Codex, som kondenserede nøgleindsigter fra tusindvis af datapunkter på under tre minutter.
Samlet set er OpenAIs pointe, at de nye egenskaber ikke kun er “nice demos”, men gav en mærkbar acceleration på tværs af research, engineering og produktteams.
Cybersikkerhed: High capability, sårbarheder og en strammere safety stack
OpenAI fremhæver, at de over de seneste måneder har set tydelige forbedringer på cybersecurity-opgaver, til gavn for både udviklere og security-professionals. Samtidig har de forberedt “strengthened cyber safeguards” for at støtte defensiv brug og robusthed i økosystemet.
GPT‑5.3‑Codex er – ifølge OpenAI – den første model, de klassificerer som High capability på cybersecurity-relaterede opgaver under deres Preparedness Framework, og den første, de direkte har trænet til at identificere software-vulnerabilities. De skriver også, at de ikke har endegyldigt bevis for, at modellen kan automatisere cyber attacks end-to-end, men at de anlægger en forsigtighedstilgang og deployer deres mest omfattende cybersecurity safety stack til dato.
De nævner, at mitigations inkluderer:
- Safety training
- Automated monitoring
- Trusted access for advanced capabilities
- Enforcement pipelines inklusive threat intelligence
Fordi cybersikkerhed er dual-use, beskriver OpenAI en evidensbaseret, iterativ tilgang: accelerér defenders’ evne til at finde og fixe sårbarheder, men gør misbrug sværere. Som del af det lancerer de Trusted Access for Cyber, et pilotprogram der skal accelerere cyber defense research.
Derudover investerer de i økosystem-safeguards, fx ved at udvide private beta af Aardvark, deres security research agent, som første offering i en suite af Codex Security-produkter og værktøjer. De nævner også partnerskaber med open-source maintainers om gratis codebase scanning for udbredte projekter som Next.js, hvor en security researcher brugte Codex til at finde sårbarheder, der blev disclosed her: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472.
Til sidst bygger de videre på deres $1M Cybersecurity Grant Program fra 2023 ved at committe $10M i API credits til at accelerere cyber defense med deres mest kapable modeller – især for open source og kritisk infrastruktur. Organisationer, der arbejder i god tro med security research, kan ansøge om API credits og support via deres Cybersecurity Grant Program: https://openai.com/index/openai-cybersecurity-grant-program/.
Tilgængelighed og praktiske detaljer
GPT‑5.3‑Codex er tilgængelig på betalte ChatGPT-planer, alle de steder du kan bruge Codex: app, CLI, IDE extension og web. OpenAI skriver, at de arbejder på at enable API access “snart”, men med fokus på sikker aktivering.
De understreger også, at Codex-brugere nu får GPT‑5.3‑Codex kørt 25% hurtigere pga. forbedringer i deres infrastruktur og inference stack, hvilket giver hurtigere interaktion og hurtigere resultater.
Hardwaremæssigt skriver OpenAI, at GPT‑5.3‑Codex blev co-designet til, trænet med og served på NVIDIA GB200 NVL72-systemer, og de takker NVIDIA for partnerskabet.
Hvad er næste skridt (ifølge OpenAI)?
OpenAI positionerer GPT‑5.3‑Codex som et skridt fra “at skrive kode” til “at bruge kode som et værktøj til at operere en computer” og dermed løse arbejde end-to-end. Ved at skubbe grænsen for, hvad en coding agent kan, åbner de ifølge deres egen fortælling for en bredere klasse af knowledge work: bygge og deploye software, researche, analysere og eksekvere komplekse opgaver.
Det er også en interessant re-framing af Codex’ mål: det, der startede som en satsning på at være den bedste coding agent, bliver nu præsenteret som fundamentet for en mere generel computer-samarbejdspartner, der udvider både hvem der kan bygge, og hvad der kan bygges.
Appendix: nøglebenchmarks (xhigh) samlet
OpenAI har også publiceret en tabel over udvalgte evalueringer. Alle evalueringer i blogindlægget blev kørt på GPT‑5.3‑Codex med xhigh reasoning effort.
SWE-Bench Pro (Public)
- GPT-5.3-Codex (xhigh): 56.8%
- GPT-5.2-Codex (xhigh): 56.4%
- GPT-5.2 (xhigh): 55.6%
Terminal-Bench 2.0
- GPT-5.3-Codex (xhigh): 77.3%
- GPT-5.2-Codex (xhigh): 64.0%
- GPT-5.2 (xhigh): 62.2%
OSWorld-Verified
- GPT-5.3-Codex (xhigh): 64.7%
- GPT-5.2-Codex (xhigh): 38.2%
- GPT-5.2 (xhigh): 37.9%
GDPval (wins or ties)
- GPT-5.3-Codex (xhigh): 70.9%
- GPT-5.2-Codex (xhigh): -
- GPT-5.2 (xhigh): 70.9% (high)
Cybersecurity Capture The Flag Challenges
- GPT-5.3-Codex (xhigh): 77.6%
- GPT-5.2-Codex (xhigh): 67.4%
- GPT-5.2 (xhigh): 67.7%
SWE-Lancer IC Diamond
- GPT-5.3-Codex (xhigh): 81.4%
- GPT-5.2-Codex (xhigh): 76.0%
- GPT-5.2 (xhigh): 74.6%Codex app: download-link fra OpenAI
Codex app (macOS .dmg)


Referencer / Kilder
Mads Jensen
Kubernetes og container orchestration ekspert. Microservices deployment og cluster management er min hverdag. Skalerbarhed i centrum.
Alle indlæg