

GPT-5.3-Codex: ko agent za kodo postane sodelavec za cel računalnik
Codex smo do zdaj večinoma jemali kot zelo dober “pair programmer”: napiše funkcijo, popravi test, pregleda PR, sestavi skripto in ti prihrani uro ali dve. Z objavo GPT-5.3-Codex OpenAI precej jasno kaže, da je cilj širši: Codex želi postati agent, ki zna na računalniku opraviti skoraj vse, kar razvijalci in drugi “knowledge workerji” v praksi počnemo – od raziskovanja do uporabe orodij, zagona procesov, iteriranja čez dneve in dostave končnega artefakta.
Po navedbah OpenAI je GPT‑5.3‑Codex trenutno najbolj sposoben agentni (agentic) model za programiranje. Združuje “frontier” coding zmogljivosti iz linije GPT‑5.2‑Codex in sklepanje ter profesionalno znanje iz GPT‑5.2 – v enem modelu – in je hkrati 25% hitrejši. Posledica je zelo praktična: agent lahko drži kontekst dlje časa, dela na dolgih nalogah in ostaja uporaben tudi, ko gre za kompleksno izvedbo z več koraki.
Najbolj zanimiv detajl iz objave: GPT‑5.3‑Codex je prvi model, za katerega OpenAI eksplicitno pravi, da je bil instrumentalen pri ustvarjanju samega sebe. Ekipa Codex je zgodnje različice uporabila za razhroščevanje treninga, za upravljanje deploya in za diagnostiko testov ter evalvacij. V praksi to pomeni, da agent ni samo produkt, ampak tudi pospeševalnik razvojnega cikla modela.
Frontier agentne sposobnosti: benchmarki, ki jih je vredno spremljati
OpenAI pri tej izdaji izpostavi štiri benchmarke, ki jih uporabljajo za merjenje programerskih, agentnih in “real-world” sposobnosti: SWE-Bench Pro, Terminal-Bench, OSWorld in GDPval. GPT‑5.3‑Codex naj bi dosegal industrijski vrh na SWE‑Bench Pro in Terminal‑Bench ter močan rezultat na OSWorld in GDPval.
Programiranje: SWE-Bench Pro + Terminal-Bench 2.0
SWE‑Bench Pro je predstavljen kot stroga evalvacija realnega software engineeringa. Ključna razlika, ki jo OpenAI poudari: kjer SWE‑bench Verified testira samo Python, SWE‑Bench Pro pokriva štiri jezike, hkrati pa je bolj odporen na kontaminacijo (contamination-resistant), raznolik in bolj industrijsko relevanten.
Poleg tega GPT‑5.3‑Codex “močno preseže” prejšnji state‑of‑the‑art na Terminal‑Bench 2.0, ki meri terminalske veščine, ki jih agent (kot je Codex) potrebuje za delo: premikanje po filesystemu, zaganjanje ukazov, interpretiranje izhodov, iteriranje. Zanimiv poudarek: model to doseže z manj tokeni kot prejšnji modeli, kar je pomembno, ker manj tokenov pogosto pomeni več prostora za dejansko gradnjo in iteriranje v realnih sejah.
Spletni razvoj: večdnevno iteriranje, estetika in boljši privzeti “canvas”
OpenAI tukaj ne govori samo o tem, da model napiše komponento ali landing page. Fokus je na kombinaciji: frontier coding + izboljšana estetika + “compaction” (kompaktnejši output in bolj smiselne privzete odločitve), kar omogoča, da agent iz nule izdela kompleksne igre in aplikacije ter jih avtonomno izboljšuje več dni.
Za test “long‑running” agentnih sposobnosti v web developmentu so GPT‑5.3‑Codex prosili, da izdela dve igri: (1) drugo verzijo dirkalne igre iz objave o lansiranju Codex appa in (2) potapljaško igro. Z uporabo veščine develop web game ter generičnih nadaljnjih pozivov, kot sta “fix the bug” ali “improve the game”, je model igre iteriral avtonomno skozi milijone tokenov.
- Dirkalna igra: več različnih dirkačev, osem map in predmeti, ki jih uporabiš s preslednico. Igro lahko preizkusiš tukaj: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Potapljaška igra: raziskovanje grebenov, zbiranje za “fish codex”, upravljanje kisika, pritiska in nevarnosti. Igra je tukaj: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Za bolj “vsakdanji” frontend OpenAI trdi, da GPT‑5.3‑Codex bolje razume namen uporabnika kot GPT‑5.2‑Codex. Pri enostavnih ali premalo specificiranih promptih naj bi zato privzeto zgradil bolj funkcionalne strani z bolj smiselnimi defaulti – kot boljši začetni osnutek, ki ga potem dodelaš.
V njihovem primeru primerjave landing page-a je GPT‑5.3‑Codex samodejno prikazal letni paket kot znižano mesečno ceno (namesto da bi uporabniku serviral letni total, ki ga mora mentalno deliti), dodal je samodejno preklapljajoč carousel s tremi različnimi citati in na splošno ustvaril stran, ki deluje bolj “production‑ready” že v privzeti verziji.
Onkraj programiranja: “knowledge work” in GDPval
Pomemben del sporočila je, da v realnem življenju ne delamo samo kode: debugging, deploy, monitoring, pisanje PRD-jev (Product Requirements Document), urejanje copyja, user research, testi, metrike… in še veliko stvari, ki so bližje dokumentom, tabelam in predstavitvam kot pa IDE-ju.
GPT‑5.3‑Codex je zasnovan tako, da podpira celoten software lifecycle in tudi širše. OpenAI pove, da model z “custom skills” (po vzoru tistih, ki so jih uporabili pri prejšnjih GDPval rezultatih) kaže močan rezultat na GDPval, kjer naj bi dosegal GPT‑5.2.
GDPval je evalvacija, ki jo je OpenAI izdal leta 2025 in meri uspešnost modela pri dobro specificiranih nalogah znanja (knowledge work) skozi 44 poklicev. Naloge vključujejo izdelavo predstavitev, spreadsheetov in drugih delovnih artefaktov. V objavi poudarijo, da je vsako nalogo zasnoval izkušen profesionalec in da odraža realno delo znotraj poklica.
Primer iz objave: 10-slajdna predstavitev za finančne svetovalce
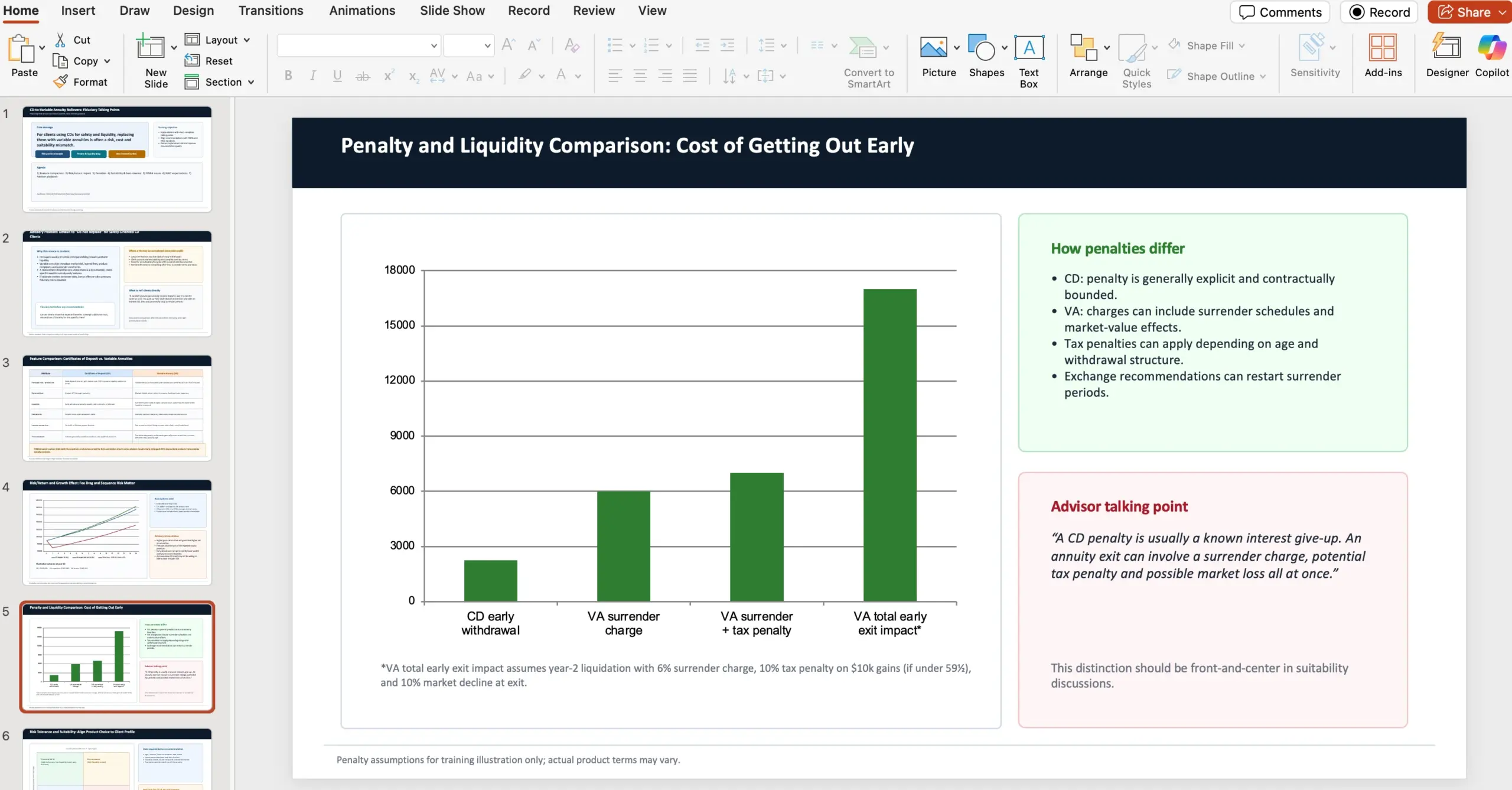
Eden od konkretnih prikazov je naloga, kjer agent nastopa kot finančni svetovalec v wealth management podjetju. Kontekst: stranke razmišljajo o tem, da bi “rolling” certificate of deposits (CD) preusmerile v variable annuities, ker jih privlači kombinacija tržnega donosa in obljube doživljenjskih mesečnih izplačil. Naloga agenta je pripraviti 10-slajdno PowerPoint predstavitev z argumenti, zakaj naj fiduciary finančni svetovalci takšno odločitev močno odsvetujejo.
V zahtevah je bilo eksplicitno navedeno, da mora predstavitev zajeti: primerjavo feature-jev med CD-ji in variable annuities (z opozorili za investitorje, vir FINRA), primerjavo risk/return in vpliva na rast, razlike v penalih med produktoma, kontrast risk tolerance in suitability (vir NAIC Best Interest Regulations), izpostavitev FINRA concerns/issues in izpostavitev NAIC issues/regulations. Kot referenčna vira sta bila navedena: https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf in https://www.finra.org/investors/insights/high-yield-cds
OSWorld: agent, ki uporablja računalnik v vizualnem namiznem okolju
OSWorld je benchmark za agentno uporabo računalnika, kjer agent v vizualnem desktop okolju opravlja produktivnostne naloge. OpenAI pri GPT‑5.3‑Codex poudari, da kaže precej močnejše “computer use” sposobnosti kot prejšnji GPT modeli. V OSWorld‑Verified modeli uporabljajo vision za dokončanje raznolikih nalog; v objavi je omenjeno tudi, da ljudje dosegajo približno ~72%.
Če to povežemo: rezultati na programiranju, frontendu, “computer-use” in realnih nalogah kažejo, da GPT‑5.3‑Codex ni samo boljši pri posameznih točkah, ampak nakazuje premik proti enemu bolj splošnemu agentu, ki zna razmišljati, graditi in izvrševati čez spekter realnega tehničnega dela.
Interaktivni sodelavec: nadzor in “steering” medtem ko agent dela
Ko agenti postajajo močnejši, ozko grlo ni več samo “kaj zmorejo”, ampak kako jih človek vodi, usmerja in nadzoruje, še posebej, ko jih imaš več vzporedno. Codex app naj bi bil v tej izdaji pomemben kos zgodbe: upravljanje agentov je lažje, z GPT‑5.3‑Codex pa tudi bolj interaktivno.
OpenAI opisuje, da Codex z novim modelom daje pogostejše posodobitve, da si sproti na tekočem s ključnimi odločitvami in napredkom. Namesto čakanja na končni output lahko v realnem času sprašuješ, debatiraš pristop in usmerjaš proti rešitvi. Model razlaga, kaj počne, se odziva na feedback in te drži v zanki od začetka do konca.
Kje vklopiš “steering” med delom
V Codex appu lahko vklopiš usmerjanje med izvajanjem v nastavitvah: Settings > General > Follow-up behavior.
Kako je Codex pomagal trenirati in deployati GPT-5.3-Codex
OpenAI pravi, da je zadnje hitro izboljševanje Codexa rezultat raziskav, ki so tekle mesece ali leta, in da jih Codex zdaj aktivno pospešuje. Zanimiva je trditev, da mnogi raziskovalci in inženirji v OpenAI opisujejo svoje delo kot “fundamentalno drugačno” kot še pred dvema mesecema – ker zgodnje verzije GPT‑5.3‑Codex že tako močno dvignejo produktivnost.
V objavi naštejejo več konkretnih načinov uporabe v internih ekipah, kar je koristno tudi za nas, ker pokaže realen “operating model” za agentno delo (torej: agent ni samo chat, ampak orodje, ki se vpenja v procese).
Raziskovalna ekipa: monitoring treninga, diagnostika in analitika interakcij
- Codex je pomagal spremljati in razhroščevati trening run za to izdajo.
- Ni ostal pri infrastrukturnih težavah: pomagal je slediti vzorcem skozi trening, pripravil poglobljeno analizo kakovosti interakcij, predlagal popravke in zgradil bogate aplikacije, s katerimi so raziskovalci natančno razumeli razlike v vedenju modela glede na prejšnje modele.
Inženirska ekipa: harness, edge case-i, caching in stabilna latenca
- Codex je pomagal optimizirati in prilagoditi “harness” za GPT‑5.3‑Codex.
- Ko so se pojavili nenavadni edge case-i, so člani ekipe uporabili Codex za identifikacijo “context rendering” bugov in za iskanje root cause za nizke cache hit rate.
- Med lansiranjem naj bi GPT‑5.3‑Codex še naprej pomagal tako, da dinamično skaluje GPU clustre glede na prometne sunke in ohranja latenco stabilno.
Alpha test: merjenje produktivnosti na turn in analiza logov z regex klasifikatorji
Med alpha testiranjem je eden od raziskovalcev želel razumeti, koliko dodatnega dela GPT‑5.3‑Codex opravi “per turn” in kakšna je razlika v produktivnosti. Model je predlagal in pripravil več preprostih regex klasifikatorjev za oceno pogostosti: pojasnjevalnih vprašanj, pozitivnih in negativnih uporabniških odzivov ter napredka na nalogi. Nato je to skalabilno pognal čez vse session loge in pripravil poročilo z zaključki.
OpenAI iz tega izpelje opažanje: ljudje, ki gradijo s Codexom, so bili bolj zadovoljni, ker agent bolje razume njihov namen in naredi več napredka v vsakem turnu, z manj dodatnimi pojasnjevalnimi vprašanji.
Neintuitivni rezultati in bolj bogate vizualizacije
Ker je GPT‑5.3‑Codex precej drugačen od predhodnikov, so podatki iz alpha testiranja vsebovali tudi precej nenavadnih in kontraintuitivnih rezultatov. V objavi opisujejo primer, kjer je data scientist skupaj z GPT‑5.3‑Codex zgradil nove data pipeline-e in vizualizacije, ki so bile bogatejše od tistih v standardnih dashboard orodjih. Rezultate so nato so-analizirali s Codexom, ki je ključne vpoglede čez tisoče podatkovnih točk povzel v manj kot treh minutah.
Če vse skupaj sešteješ: ne gre za en “wow demo”, ampak za vzorec uporabe, kjer agent sistematično skrajša čas od vprašanja do razlage, od anomalije do root cause in od ideje do deploya.
Kibernetska varnost: “High capability”, neposredno treniran za ranljivosti in novi varnostni programi
OpenAI posebej izpostavi kibernetsko varnost kot področje, kjer so v zadnjih mesecih videli opazne izboljšave. Hkrati pa pravijo, da so vzporedno pripravljali okrepljene varovalke, da bi podprli defenzivno uporabo in odpornost ekosistema. V objavi se sklicujejo na svoj zapis o krepitvi cyber resilience: https://openai.com/index/strengthening-cyber-resilience/
Ključna oznaka pri tej izdaji: GPT‑5.3‑Codex je prvi model, ki ga OpenAI pod svojim Preparedness Framework klasificira kot “High capability” za naloge povezane s kibernetsko varnostjo. Povezavi, ki ju navajajo: system card (https://openai.com/index/gpt-5-3-codex-system-card/) in Preparedness Framework (https://openai.com/index/updating-our-preparedness-framework/).
Še ena pomembna tehnična točka: to je prvi model, ki so ga neposredno trenirali za prepoznavanje programskih ranljivosti. OpenAI hkrati pravi, da nimajo dokončnih dokazov, da bi model lahko avtomatiziral kibernetske napade “end-to-end”, vendar kljub temu ubirajo previdnostni pristop.
Zato uvajajo svoj “najbolj celovit cybersecurity safety stack do zdaj”, med mitigacijami pa naštejejo:
- safety training
- avtomatiziran monitoring
- trusted access za napredne zmogljivosti
- enforcement pipeline-i, vključno z threat intelligence
Ker je cybersecurity po definiciji dual-use, OpenAI opisuje evidence-based in iterativen pristop: pospešiti delo branilcev (defenders) pri iskanju in odpravljanju ranljivosti, hkrati pa upočasniti zlorabe.
Trusted Access for Cyber (pilot)
Kot del tega lansirajo Trusted Access for Cyber, pilot program za pospeševanje raziskav na področju cyber defense: https://openai.com/index/trusted-access-for-cyber/
Aardvark in skeniranje odprtokodnih projektov (primer Next.js)
Na nivoju ekosistemskih varovalk OpenAI omenja širitev private bete Aardvark, svojega security research agenta, kot prve ponudbe v naboru Codex Security produktov in orodij: https://openai.com/index/introducing-aardvark/
Omenijo tudi partnerstva z open-source vzdrževalci, kjer ponujajo brezplačno skeniranje kode za široko uporabljene projekte, npr. Next.js. Kot konkretno referenco navedejo, da je security researcher s Codexom našel ranljivosti, ki so bile razkrite prejšnji teden: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
10M USD v API kreditih za cyber defense (Cybersecurity Grant Program)
Na finančni strani OpenAI pove, da na podlagi svojega $1M Cybersecurity Grant Program (lansiran 2023) zdaj namenjajo še $10M v API kreditih za pospeševanje cyber defense z njihovimi najbolj zmogljivimi modeli, še posebej za open source in kritično infrastrukturo. Organizacije, ki delajo v dobri veri na varnostnih raziskavah, se lahko prijavijo za API kredite in podporo prek programa: https://openai.com/index/openai-cybersecurity-grant-program/
Dostopnost, hitrost in infrastruktura
GPT‑5.3‑Codex je po navedbah OpenAI na voljo z plačljivimi ChatGPT paketi povsod, kjer lahko uporabljaš Codex: v aplikaciji, prek CLI, v IDE razširitvi in na webu. Za API dostop pravijo, da ga “delajo” in ga želijo varno omogočiti kmalu (torej še ni splošno odprt v času objave).
Z isto posodobitvijo naj bi za uporabnike Codexa poganjali GPT‑5.3‑Codex 25% hitreje, zaradi izboljšav v infrastrukturi in inference stacku. To pomeni hitrejše interakcije in hitrejše rezultate.
Model je bil so-načrtovan, treniran in serviran na NVIDIA GB200 NVL72 sistemih; OpenAI se v objavi zahvaljuje NVIDIA za partnerstvo.
Kaj to pomeni v praksi: premik od “coding agenta” k generalnemu sodelavcu
Glavna rdeča nit objave je, da Codex z GPT‑5.3‑Codex premika fokus: koda ni več samo cilj, ampak orodje, s katerim agent upravlja računalnik in dokonča delo od začetka do konca. Ko enkrat agent dovolj dobro piše, poganja in popravi kodo, se logično odpre širši razred nalog: raziskovanje, analiza, priprava dokumentacije, izdelava predstavitev, delo s spreadsheeti, monitoring in izvedba kompleksnih korakov.
Za razvojne ekipe (tudi v WordPress ekosistemu) je največja praktična sprememba pogosto prav interakcijski model: agent, ki ga lahko usmerjaš medtem ko dela, in ki redno poroča o odločitvah, je bistveno bližje dejanskemu sodelavcu kot pa “enkratni generator” outputa.
Dodatek: številke iz appendix tabele
OpenAI v dodatku objavi primerjavo (GPT‑5.3‑Codex (xhigh) vs GPT‑5.2‑Codex (xhigh) vs GPT‑5.2 (xhigh)). V opombi je navedeno, da so bile vse evalvacije v blogu izvedene z xhigh reasoning effort.
- SWE-Bench Pro (Public): GPT-5.3-Codex 56.8% | GPT-5.2-Codex 56.4% | GPT-5.2 55.6%
- Terminal-Bench 2.0: GPT-5.3-Codex 77.3% | GPT-5.2-Codex 64.0% | GPT-5.2 62.2%
- OSWorld-Verified: GPT-5.3-Codex 64.7% | GPT-5.2-Codex 38.2% | GPT-5.2 37.9%
- GDPval (wins or ties): GPT-5.3-Codex 70.9% | GPT-5.2-Codex – | GPT-5.2 70.9% (high)
- Cybersecurity Capture The Flag Challenges: GPT-5.3-Codex 77.6% | GPT-5.2-Codex 67.4% | GPT-5.2 67.7%
- SWE-Lancer IC Diamond: GPT-5.3-Codex 81.4% | GPT-5.2-Codex 76.0% | GPT-5.2 74.6%
Relevantne povezave iz objave
- Prenos Codex appa (macOS .dmg): https://persistent.oaistatic.com/codex-app-prod/Codex.dmg
- GPT-5.3-Codex System Card: https://openai.com/index/gpt-5-3-codex-system-card/
- Strengthening cyber resilience: https://openai.com/index/strengthening-cyber-resilience/
- Trusted Access for Cyber: https://openai.com/index/trusted-access-for-cyber/
- Aardvark: https://openai.com/index/introducing-aardvark/
- Preparedness Framework: https://openai.com/index/updating-our-preparedness-framework/
- Cybersecurity Grant Program: https://openai.com/index/openai-cybersecurity-grant-program/
- GDPval: https://openai.com/index/gdpval/
- Introducing the Codex app: https://openai.com/index/introducing-the-codex-app/
- Introducing GPT-5.2-Codex: https://openai.com/index/introducing-gpt-5-2-codex/
- Primer razkritij za Next.js (Vercel): https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
- Web demo – racing game v2: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Web demo – diving game: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Reference / Viri
Luka Horvat
Razvijalec progresivnih spletnih aplikacij in offline-first pristopa. Service workerji in strategije predpomnjenja so moja specialnost. Splet naj deluje povsod!
Vse objave

