

GPT-5.3-Codex: Codex przestaje być „agentem do kodu” i zaczyna ogarniać całą pracę na komputerze
OpenAI zaprezentowało GPT‑5.3‑Codex jako kolejny krok w rozwoju Codex – z narzędzia do generowania i przeglądania kodu do agenta (czyli modelu potrafiącego planować, korzystać z narzędzi i wykonywać zadania) obejmującego praktycznie pełne spektrum profesjonalnej pracy na komputerze. W praktyce chodzi o długie runy: research, iteracje, uruchamianie poleceń w terminalu, naprawy w projekcie, budowę aplikacji czy przygotowanie materiałów (slajdy, arkusze, dokumenty) – z możliwością bieżącego sterowania w trakcie, bez gubienia kontekstu.
W tym wydaniu są trzy rzeczy, które szczególnie warto odnotować z perspektywy devów: (1) skok w benchmarkach „agentowych” i terminalowych, (2) nacisk na interaktywną współpracę w Codex app (częste update’y, możliwość dopytywania i korygowania kursu w locie), oraz (3) mocne postawienie tematu cyberbezpieczeństwa – model jest klasyfikowany jako „High capability” dla zadań security w ramach Preparedness Framework, a wdrożenie ma najpełniejszy dotąd pakiet zabezpieczeń.
Co właściwie wnosi GPT‑5.3‑Codex (w skrócie)
- To najnowszy, „najbardziej agentowy” model kodujący w rodzinie Codex: łączy frontierową skuteczność GPT‑5.2‑Codex w zadaniach stricte inżynierskich z rozumowaniem i wiedzą zawodową GPT‑5.2 – w jednym modelu.
- Według ogłoszenia działa ok. 25% szybciej (lepsza infrastruktura i inference stack), co ma realne znaczenie przy długich sesjach i wielu iteracjach.
- Jest projektowany pod długotrwałe zadania: research + użycie narzędzi + złożona egzekucja (a nie tylko „wygeneruj snippet”).
- Możesz prowadzić model jak współpracownika: w trakcie pracy dostajesz częste aktualizacje i możesz zmieniać kierunek bez zrywania kontekstu.
- To pierwszy model, który był „instrumentalny” w stworzeniu samego siebie: zespół Codex używał wczesnych wersji do debugowania treningu, zarządzania wdrożeniem i diagnozy testów oraz ewaluacji.
Frontier agentic capabilities: benchmarki, które OpenAI podkreśla
OpenAI opisuje GPT‑5.3‑Codex jako nowy „industry high” na SWE‑Bench Pro i Terminal‑Bench oraz mocny wynik na OSWorld i GDPval. Te cztery benchmarki mają mierzyć odpowiednio: realne zadania inżynierskie, umiejętności terminalowe agenta, zdolność pracy w wizualnym środowisku desktopowym oraz wiedzę/pracę zawodową w dobrze zdefiniowanych taskach.
Coding: SWE‑Bench Pro i Terminal‑Bench 2.0
W warstwie stricte programistycznej GPT‑5.3‑Codex ma osiągać state‑of‑the‑art na SWE‑Bench Pro. OpenAI zwraca uwagę na różnicę w stosunku do SWE‑bench Verified: Verified testuje tylko Python, natomiast SWE‑Bench Pro obejmuje cztery języki, ma być bardziej odporne na „contamination” (zanieczyszczenie danymi), a przy tym trudniejsze, bardziej zróżnicowane i bliższe realiom branżowym.
Drugi ważny punkt to Terminal‑Bench 2.0, czyli test praktycznych umiejętności terminalowych (tego, czego realnie potrzebuje agent w stylu Codex: poruszanie się po repo, uruchamianie poleceń, diagnostyka). OpenAI podkreśla też, że GPT‑5.3‑Codex osiąga te wyniki używając mniejszej liczby tokenów niż wcześniejsze modele – co w praktyce ma zostawiać więcej „budżetu” na to, co użytkownik chce zbudować.
Web development: długie, autonomiczne iteracje (gry w przeglądarce)
Ciekawy fragment ogłoszenia dotyczy webdevu i „long‑running agentic capabilities”. Żeby przetestować, czy model potrafi przez dłuższy czas iterować nad projektem, OpenAI zleciło mu zbudowanie dwóch gier od zera: (1) drugiej wersji gry wyścigowej znanej z premiery Codex app oraz (2) gry o nurkowaniu. Model korzystał ze skillu „develop web game” i dostawał proste, generyczne prompty follow‑up w stylu „fix the bug” albo „improve the game”. Następnie iterował autonomicznie przez miliony tokenów.
Efekt ma być na tyle dojrzały, że OpenAI publikuje gry do samodzielnego uruchomienia w przeglądarce:
- Gra wyścigowa: różni zawodnicy, osiem map i przedmioty używane spacją – wersja v2: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Gra o nurkowaniu: eksploracja raf, kolekcjonowanie (fish codex), zarządzanie tlenem, ciśnieniem i zagrożeniami: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
W codziennym budowaniu stron (landing page, prosta strona marketingowa) OpenAI twierdzi też, że GPT‑5.3‑Codex lepiej odczytuje intencję i sensownie uzupełnia braki w promptach: gdy polecenie jest proste albo niedookreślone, model ma domyślnie proponować bardziej funkcjonalną stronę i lepsze „sensible defaults”, żeby startowy „canvas” był bliższy produkcyjnemu.
W przykładzie z dwiema stronami landingowymi (GPT‑5.3‑Codex vs GPT‑5.2‑Codex) zwrócono uwagę na dwa detale UX, które pojawiły się automatycznie w wersji 5.3: pokazywanie planu rocznego jako zdyskontowanej ceny miesięcznej (zamiast mnożenia rocznej sumy) oraz automatycznie przewijany carousel z trzema różnymi opiniami użytkowników (zamiast jednej), co daje wrażenie bardziej kompletnej strony już „z pudełka”.
Beyond coding: PRD, testy, metryki, slajdy, arkusze i „knowledge work”
OpenAI mocno akcentuje, że realna praca wytwórcza nie kończy się na generowaniu kodu. GPT‑5.3‑Codex ma wspierać pełen cykl życia oprogramowania: debugging, deployment, monitoring, pisanie PRD (Product Requirements Document), redakcję copy, user research, testy, metryki i inne elementy, które w praktyce zajmują zespołom równie dużo czasu co same implementacje.
Jednocześnie agent ma wychodzić poza software: może tworzyć prezentacje, analizować dane w arkuszach i generować różne „work products”. OpenAI odnosi to do GDPval – ewaluacji opublikowanej w 2025 roku, mierzącej wykonanie dobrze zdefiniowanych zadań wiedzo‑pracowych w 44 zawodach. W tym ujęciu GPT‑5.3‑Codex ma wypadać mocno i (w wynikach „wins or ties”) dopasowywać się do poziomu GPT‑5.2.
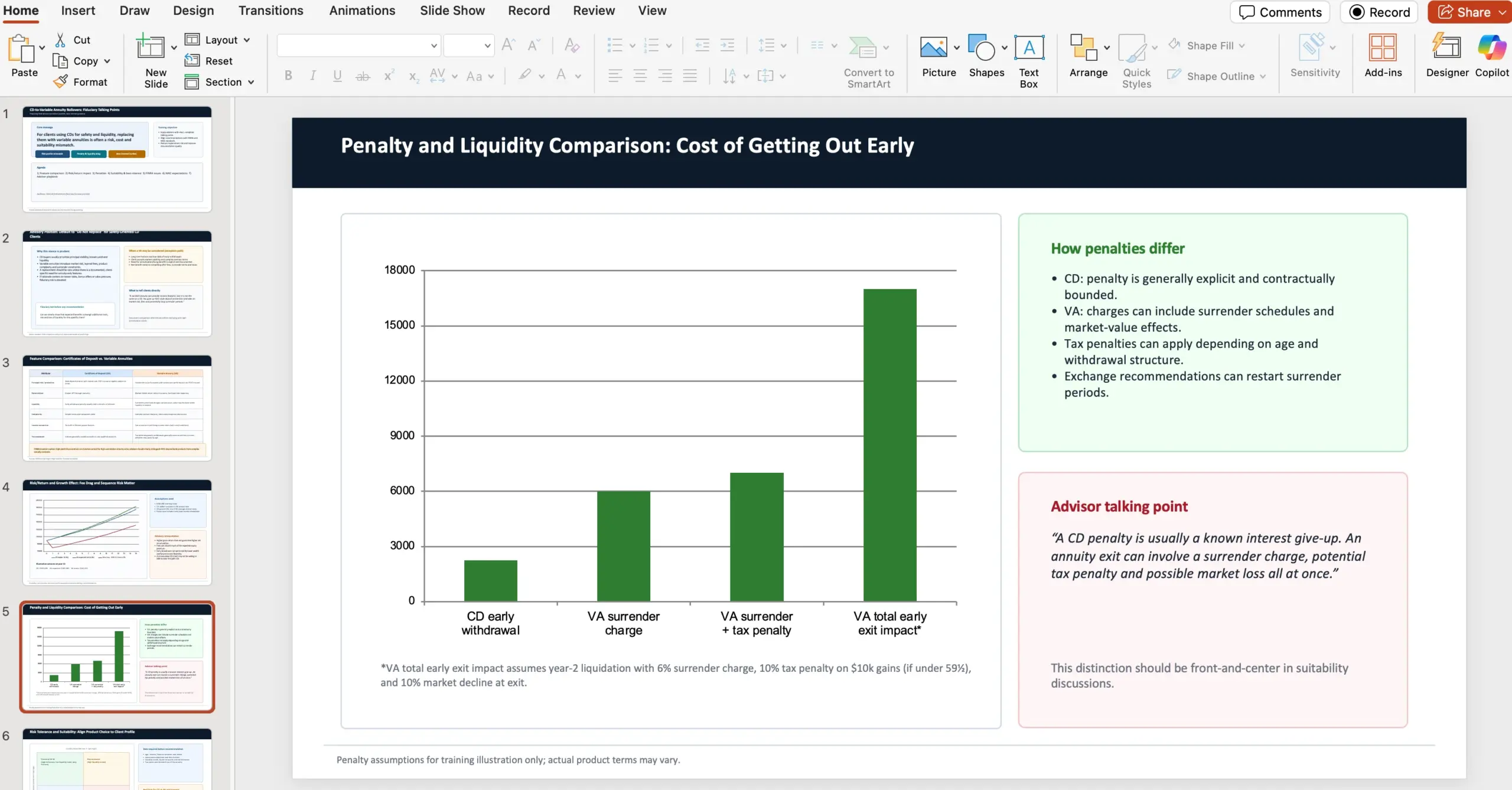
W materiale pokazano przykłady artefaktów, które agent potrafi wygenerować (slajdy doradztwa finansowego, dokument szkoleniowy dla retailu, arkusz analizy NPV, PDF z prezentacją modową). W jednym z opisanych scenariuszy prompt udawał zadanie doradcy finansowego przygotowującego 10‑slajdową prezentację wewnętrzną dla field advisorów: dlaczego – jako fiduciaries – powinni odradzać rolowanie certyfikatów depozytowych (CDs) w variable annuities. Wymagania obejmowały m.in. porównanie cech produktów, analizę ryzyko/zwrot i wpływu na wzrost, różnice w karach/penalties, suitability i risk tolerance z odniesieniem do NAIC Best Interest Regulations oraz wskazanie obaw FINRA i kwestii regulacyjnych NAIC. W treści prompta podano też konkretne źródła webowe (NAIC i FINRA), które należało uwzględnić.
OSWorld: praca w „prawdziwym” desktopie (z vision)
OSWorld to benchmark, w którym agent ma wykonywać zadania produktywności w wizualnym środowisku desktopowym (czyli nie tylko tekst/terminal, ale też interfejsy). OpenAI wskazuje, że GPT‑5.3‑Codex prezentuje „far stronger computer use capabilities” niż poprzednie modele GPT. W wersji OSWorld‑Verified modele korzystają z vision do wykonywania zróżnicowanych zadań komputerowych, a w materiale pojawia się kontekst, że ludzie osiągają ok. 72%.
„Interaktywny współpracownik”: co zmienia Codex app z GPT‑5.3‑Codex
Wraz ze wzrostem możliwości agentów rośnie inny problem: nie „czy agent potrafi”, tylko „czy człowiek potrafi go skutecznie poprowadzić i nadzorować”, zwłaszcza gdy pracuje równolegle wiele agentów. OpenAI opisuje Codex app jako element, który ma upraszczać zarządzanie i kierowanie agentami – a z GPT‑5.3‑Codex aplikacja ma stać się wyraźnie bardziej interaktywna.
Kluczowe zachowanie: zamiast czekać na finalny wynik, dostajesz częste aktualizacje o postępie i decyzjach. Możesz wchodzić w dialog w czasie rzeczywistym – zadawać pytania, dyskutować podejście i korygować kierunek rozwiązania. Model ma „mówić na głos”, co robi, reagować na feedback i trzymać Cię na bieżąco od startu do końca.
Jeśli chcesz, żeby agent reagował na follow‑upy w trakcie pracy, opcję sterowania w locie włącza się w aplikacji: Settings > General > Follow‑up behavior.
Jak OpenAI używało Codex do trenowania i wdrożenia GPT‑5.3‑Codex
W ogłoszeniu jest sporo „kuchni” procesu. OpenAI podkreśla, że szybkie ulepszenia Codex są wynikiem projektów badawczych trwających miesiącami lub latami, ale te projekty są teraz przyspieszane przez Codex. Pojawia się nawet teza, że wielu badaczy i inżynierów odczuwa, iż ich praca dziś wygląda „fundamentally different” niż dwa miesiące temu – właśnie przez to, jak bardzo agent automatyzuje i skraca pętle feedbacku.
Co istotne: nawet wczesne wersje GPT‑5.3‑Codex miały na tyle duże możliwości, że zespół używał ich do usprawniania treningu i wspierania późniejszych etapów wdrożenia. Konkretne przykłady z materiału:
- Zespół badawczy używał Codex do monitorowania i debugowania runu treningowego. Nie ograniczało się to do infrastruktury: Codex miał pomagać śledzić wzorce w trakcie treningu, robić głęboką analizę jakości interakcji, proponować poprawki oraz budować aplikacje ułatwiające ludziom precyzyjne zrozumienie różnic zachowania modelu względem poprzedników.
- Zespół inżynierski używał Codex do optymalizacji i adaptacji harnessu dla GPT‑5.3‑Codex. Gdy zaczęły pojawiać się dziwne edge case’y wpływające na użytkowników, Codex miał pomóc znaleźć błędy renderowania kontekstu oraz zdiagnozować przyczynę niskich cache hit rates.
- Podczas launchu GPT‑5.3‑Codex ma dalej pomagać operacyjnie: dynamicznie skaluje klastry GPU pod skoki ruchu i stabilizuje latency.
- W alpha testach jeden z badaczy chciał oszacować, ile „dodatkowej pracy” model wykonuje per turn i jak zmienia się produktywność. GPT‑5.3‑Codex zaproponował proste klasyfikatory regex do estymowania częstotliwości doprecyzowań, pozytywnych/negatywnych reakcji użytkowników oraz postępu zadania; następnie uruchomił je skalowalnie na logach sesji i przygotował raport z wnioskami. Wniosek w materiale: użytkownicy byli bardziej zadowoleni, bo agent lepiej rozumiał intencję, robił większy postęp na turę i zadawał mniej pytań doprecyzowujących.
- Ponieważ GPT‑5.3‑Codex jest „tak różny” od poprzedników, dane z alfy zawierały wiele nietypowych i kontraintuicyjnych wyników. Data scientist z zespołu miał zbudować z Codex nowe pipeline’y danych i bogatsze wizualizacje niż standardowe narzędzia dashboardowe. Wyniki były współanalizowane z Codex, który streścił kluczowe insighty z tysięcy punktów danych w mniej niż trzy minuty.
Wspólny mianownik: OpenAI przedstawia to nie jako pojedyncze, efektowne demo, tylko jako systematyczne skrócenie czasu od obserwacji problemu → diagnostyka → poprawka → weryfikacja, zarówno w researchu, jak i w inżynierii oraz produkcie.
Cyberbezpieczeństwo: „High capability”, trening pod podatności i nowe programy
W ostatnich miesiącach (wg materiału) OpenAI obserwowało znaczące poprawy modeli w zadaniach cybersecurity – z korzyścią dla developerów i specjalistów security. Równolegle przygotowano wzmocnione zabezpieczenia ekosystemowe (w ogłoszeniu pojawia się odnośnik do inicjatywy „strengthened cyber safeguards”).
Najważniejsze deklaracje wprost:
- GPT‑5.3‑Codex to pierwszy model sklasyfikowany przez OpenAI jako „High capability” dla zadań cybersecurity w ramach Preparedness Framework (z linkiem do system card).
- To również pierwszy model, który został bezpośrednio trenowany do identyfikowania podatności (software vulnerabilities).
- OpenAI zaznacza, że nie ma definitywnego dowodu, iż model potrafi zautomatyzować cyberataki end‑to‑end, ale przyjmuje podejście ostrożnościowe i wdraża najbardziej kompleksowy dotąd cybersecurity safety stack.
- Wymienione elementy mitigacji obejmują: safety training, automated monitoring, trusted access dla zaawansowanych możliwości oraz enforcement pipelines z threat intelligence.
- Ponieważ cybersecurity jest obszarem dual‑use, podejście ma być evidence‑based i iteracyjne: przyspieszać pracę obrońców (znajdowanie i łatanie podatności), a spowalniać nadużycia.
W tym kontekście OpenAI uruchamia Trusted Access for Cyber – pilotaż mający przyspieszać badania w obszarze cyber defense.
Równolegle mają iść inwestycje w zabezpieczenia ekosystemu: rozszerzanie prywatnej bety Aardvark (agent do badań security) jako pierwszej oferty w pakiecie Codex Security produktów i narzędzi. W materiale pojawia się też przykład współpracy z maintainerami open source: darmowe skanowanie codebase’ów dla szeroko używanych projektów, takich jak Next.js – wraz z odnośnikiem do publicznego disclosure podatności (CVE) opublikowanego przez Vercel w zeszłym tygodniu.
Na dokładkę OpenAI zwiększa wsparcie grantowe. Po programie grantowym $1M z 2023 roku, teraz deklaruje $10M w API credits, aby przyspieszyć cyber defense z użyciem najbardziej zaawansowanych modeli, szczególnie dla open source i systemów infrastruktury krytycznej. Organizacje prowadzące badania bezpieczeństwa w dobrej wierze mogą aplikować o kredyty API i wsparcie w ramach Cybersecurity Grant Program.
Dostępność i szczegóły techniczne
GPT‑5.3‑Codex jest dostępny w płatnych planach ChatGPT – wszędzie tam, gdzie można używać Codex: w aplikacji, w CLI, w rozszerzeniu do IDE oraz w webie. Dostęp przez API ma zostać uruchomiony „wkrótce”, z naciskiem na bezpieczne włączenie.
OpenAI podaje też, że dla użytkowników Codex model jest uruchamiany 25% szybciej dzięki usprawnieniom infrastruktury oraz inference stack, co ma przekładać się na szybsze interakcje i szybsze wyniki.
Od strony sprzętowej: GPT‑5.3‑Codex był współprojektowany pod, trenowany z i serwowany na systemach NVIDIA GB200 NVL72. OpenAI dziękuje NVIDIA za partnerstwo.
Co dalej: od „pisania kodu” do „używania kodu do wykonania pracy”
Najbardziej spójna myśl z całego ogłoszenia jest taka: Codex przestaje być narzędziem do wytwarzania kodu, a staje się agentem, który używa kodu jako jednego z narzędzi do tego, by domknąć zadanie end‑to‑end. Pchanie granicy w tym, co potrafi agent kodujący, ma odblokowywać szerszą klasę pracy wiedzo‑technicznej – od budowy i wdrożeń, po research, analizę i realizację złożonych procesów.
W ujęciu OpenAI to, co zaczęło się jako wyścig o „najlepszego agenta do kodu”, staje się fundamentem bardziej ogólnego współpracownika na komputerze: rozszerza zarówno grono osób, które mogą budować, jak i zakres tego, co da się realnie „dowieźć” z pomocą Codex.
Appendix: wyniki benchmarków (xhigh reasoning effort)
W stopce materiału OpenAI zaznacza, że wszystkie ewaluacje w poście uruchomiono na GPT‑5.3‑Codex z ustawieniem xhigh reasoning effort. W tabeli porównawczej podano:
- SWE‑Bench Pro (Public): GPT‑5.3‑Codex (xhigh) 56.8%, GPT‑5.2‑Codex (xhigh) 56.4%, GPT‑5.2 (xhigh) 55.6%
- Terminal‑Bench 2.0: GPT‑5.3‑Codex 77.3%, GPT‑5.2‑Codex 64.0%, GPT‑5.2 62.2%
- OSWorld‑Verified: GPT‑5.3‑Codex 64.7%, GPT‑5.2‑Codex 38.2%, GPT‑5.2 37.9%
- GDPval (wins or ties): GPT‑5.3‑Codex 70.9%, GPT‑5.2‑Codex – , GPT‑5.2 70.9% (high)
- Cybersecurity Capture The Flag Challenges: GPT‑5.3‑Codex 77.6%, GPT‑5.2‑Codex 67.4%, GPT‑5.2 67.7%
- SWE‑Lancer IC Diamond: GPT‑5.3‑Codex 81.4%, GPT‑5.2‑Codex 76.0%, GPT‑5.2 74.6%



Odniesienia / Źródła
- Introducing GPT-5.3-Codex
- Introducing the Codex app
- GDPval
- Strengthening cyber resilience
- GPT-5.3-Codex System Card
- Updating our Preparedness Framework
- Trusted Access for Cyber
- Introducing Aardvark
- Summaries of CVE-2025-59471 and CVE-2025-59472
- OpenAI Cybersecurity Grant Program
- government-affairs-brief-annuity-suitability-best-interest-model.pdf
- High-yield CDs (FINRA)
Magdalena Wiśniewska
Inżynier infrastruktury chmurowej, specjalistka Terraform i Infrastructure as Code. Automatyzacja i skalowalność to moja pasja.
Wszystkie wpisy

