

GPT-5.3-Codex: Codex wordt een echte computer-collega (sneller, agentischer en met stevige cyber safeguards)
OpenAI heeft GPT‑5.3‑Codex aangekondigd als de nieuwste (en volgens hen meest capabele) agentic coding model tot nu toe. In de praktijk betekent dat: Codex schuift op van “schrijf en review code” naar “doe bijna alles wat een developer of professional op een computer doet”-inclusief onderzoek doen, tools gebruiken, deployments managen en langere workflows autonoom uitvoeren, zonder dat jij de context kwijtraakt zodra je tussendoor bijstuurt.
Wat mij in deze release vooral opvalt: OpenAI positioneert GPT‑5.3‑Codex nadrukkelijk als een interactieve samenwerker. Dus niet: wachten op één eindantwoord. Wel: een agent die onderweg statusupdates geeft, keuzes uitlegt en real-time bijgestuurd kan worden-meer zoals je dat met een collega zou doen tijdens pair programming of een incident-bridge.
Wat is GPT-5.3-Codex precies (en waarom is dit anders dan GPT-5.2-Codex)?
GPT‑5.3‑Codex combineert twee lijnen die eerder losser naast elkaar stonden: (1) frontier coding performance van GPT‑5.2‑Codex en (2) reasoning en professionele kennisvaardigheden van GPT‑5.2-samengebracht in één model. OpenAI zegt daarnaast dat GPT‑5.3‑Codex 25% sneller draait, wat vooral relevant is als je het model langere taken laat uitvoeren met veel iteraties en tool calls.
Een opvallend detail: OpenAI noemt GPT‑5.3‑Codex hun eerste model dat instrumenteel was in het creëren van zichzelf. Het Codex-team gebruikte vroege versies om het eigen trainingsproces te debuggen, deployments te managen en test-/evaluatieresultaten te diagnosticeren. Dat is interessant omdat het laat zien waar de productiviteitswinst zit: niet alleen in code genereren, maar in het versnellen van engineering- en research-cycli.
Frontier agentic capabilities: hoe meten ze dit?
OpenAI onderbouwt de claims met resultaten op vier benchmarks die ze gebruiken voor coding, agentic en real-world capabilities: SWE‑Bench Pro, Terminal‑Bench (2.0), OSWorld en GDPval. Daarnaast noemen ze prestaties op cybersecurity capture-the-flag uitdagingen en SWE-Lancer.
Coding: SWE-Bench Pro en Terminal-Bench 2.0
Voor pure software engineering claimt GPT‑5.3‑Codex state-of-the-art op SWE‑Bench Pro. Die benchmark is nadrukkelijk breder dan SWE‑bench Verified: waar Verified alleen Python test, bestrijkt SWE‑Bench Pro vier talen en is het ontworpen om beter bestand te zijn tegen contaminatie. OpenAI omschrijft SWE‑Bench Pro als strenger, diverser en relevanter voor de industrie.
Daarnaast zegt OpenAI dat GPT‑5.3‑Codex de eerdere state-of-the-art op Terminal‑Bench 2.0 ruim voorbijgaat. Terminal‑Bench meet specifiek de terminal-vaardigheden die een coding agent nodig heeft (denk aan CLI-workflows, command execution, iteratieve debugging in een shell-achtige omgeving). Een extra punt dat ze benadrukken: GPT‑5.3‑Codex haalt dit met minder tokens dan eerdere modellen-wat in de praktijk betekent dat je meer “werk” binnen je budget/context kunt proppen.
Webdevelopment: lange, autonome iteratie op games en apps
Voor webdevelopment legt OpenAI de nadruk op een combinatie van frontier coding, esthetiek en “compaction” (minder tokens voor hetzelfde resultaat). Het gevolg: het model kan volgens OpenAI dagenlang werken aan complexere projecten-zoals games en apps-from scratch.
Om die langlopende agentic capabilities te testen lieten ze GPT‑5.3‑Codex twee webgames bouwen:
- Een tweede versie van de racing game die eerder bij de Codex app launch is gebruikt.
- Een diving game met riffen verkennen, verzamelen (voor een fish codex), én mechanics zoals zuurstof, druk en hazards.
Ze gebruikten daarvoor de develop web game skill (een vooraf gedefinieerde vaardigheid/skill in Codex) en generieke follow-up prompts zoals “fix the bug” of “improve the game”. GPT‑5.3‑Codex iterereerde vervolgens autonoom over miljoenen tokens om de games stap voor stap verder te verbeteren.
- Racing game v2 (met meerdere racers, acht maps en items via de spatiebalk): https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Diving game: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
OpenAI claimt ook dat GPT‑5.3‑Codex je intentie beter begrijpt bij ‘day-to-day’ websites dan GPT‑5.2‑Codex. Bij simpele of ondergespecificeerde prompts zou het model nu vaker uitkomen op sites met meer functionaliteit en zinvollere defaults-als een sterker startcanvas.
Hun concrete voorbeeld: twee landing pages op basis van dezelfde prompt. GPT‑5.3‑Codex presenteerde een jaarplan automatisch als een afgeprijsde maandprijs (waardoor de korting logischer voelt dan het simpelweg delen van het jaarbedrag) en bouwde een automatisch wisselende testimonial carousel met drie verschillende quotes (in plaats van één). Het resultaat: “production-ready by default” is hier duidelijk het doel.
Beyond coding: support voor de hele software lifecycle (en kenniswerk daarbuiten)
Een punt dat OpenAI expliciet maakt: engineers (en teams eromheen) doen veel meer dan code genereren. GPT‑5.3‑Codex is bedoeld om werk door de hele software lifecycle te ondersteunen: debugging, deployen, monitoren, PRDs schrijven, copy bewerken, user research, tests, metrics, enzovoort.
En het gaat nog breder: met ‘custom skills’ (vergelijkbaar met wat OpenAI eerder gebruikte rond GDPval) laat GPT‑5.3‑Codex volgens hen ook sterke prestaties zien op professioneel kenniswerk, gemeten via GDPval.
Belangrijk detail: GDPval is een evaluatie die OpenAI in 2025 heeft uitgebracht. Die meet modelprestaties op goed-gespecificeerde knowledge-work taken over 44 beroepen. Denk aan het maken van presentaties, spreadsheets en andere concrete deliverables. OpenAI schrijft dat GPT‑5.3‑Codex op GDPval “matches” met GPT‑5.2 (dus: geen drop terwijl het model tegelijk agentischer en beter in code wordt).
Voorbeeldprompt (GDPval): 10-slide PowerPoint voor financial advisors
In de bron staat een volledige prompt + context voor een knowledge-work taak (financial advice). De rol: je bent financial advisor bij een wealth management firm. Veel klanten overwegen CD’s (certificates of deposits) door te rollen naar variable annuities, aangejaagd door lokale bankers. Het doel van de presentatie: field advisors intern talking points geven waarom je als fiduciary dit juist sterk moet afraden.
De gevraagde inhoud bevatte expliciet (alle punten):
- Vergelijk features van certificates of deposits vs. variable annuities, met waarschuwingen voor investeerders, gesourced via FINRA.
- Vergelijk risk/return-analyse en het effect op growth.
- Maak onderscheid in penalties tussen beide producten/vehikels.
- Contrast risk tolerance en suitability, gesourced via NAIC Best Interest Regulations.
- Highlight FINRA concerns/issues.
- Highlight NAIC issues/regulations.
- Neem mee dat NAIC en FINRA best interest- en suitability-richtlijnen hebben voor aanbevelingen rond variable annuities vanwege de complexiteit van het product.
- Gebruik deze webbronnen bij het opstellen: https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf en https://www.finra.org/investors/insights/high-yield-cds
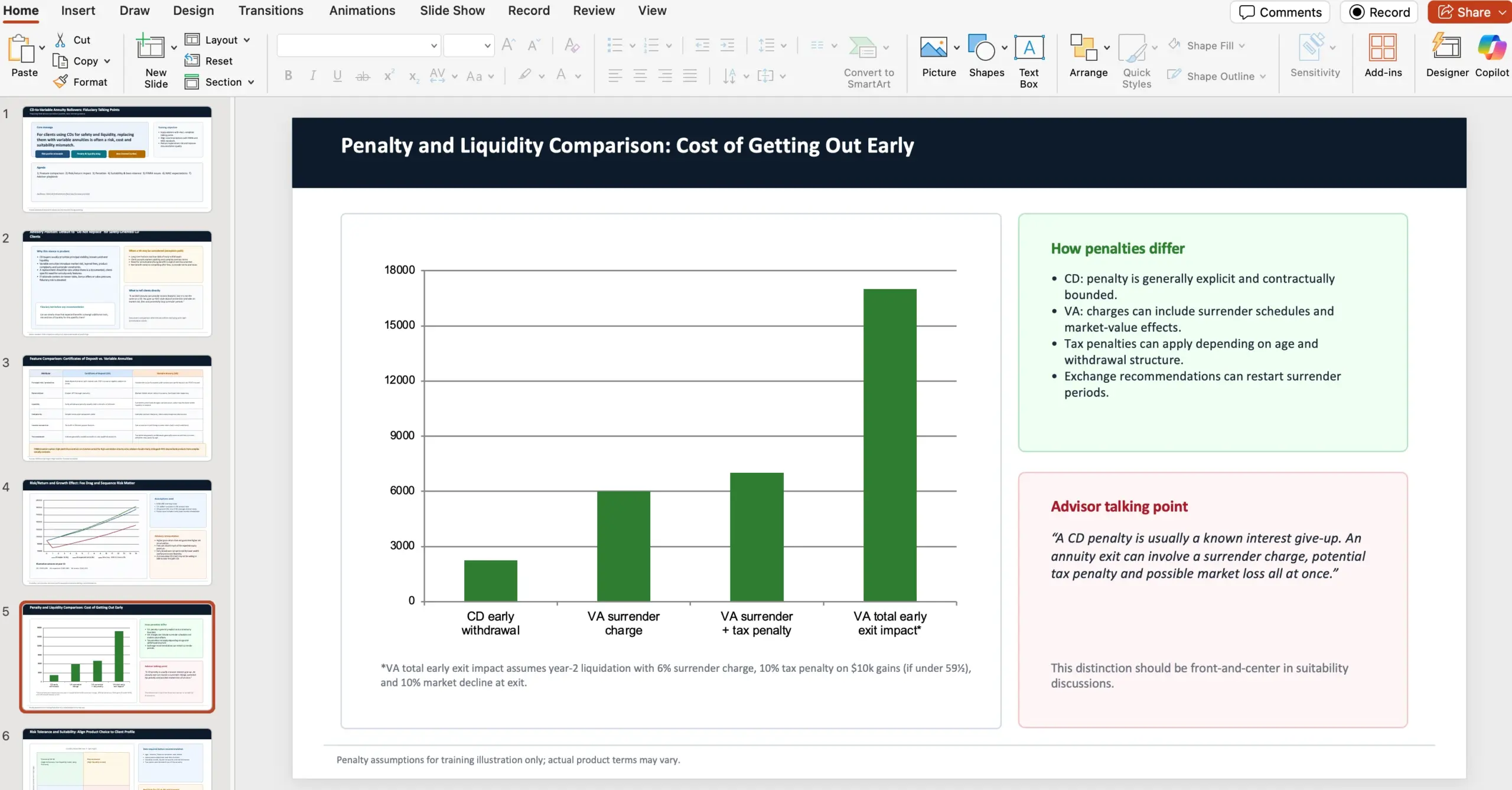
OpenAI benadrukt dat elke GDPval-taak ontworpen is door een ervaren professional en echt werk uit die beroepspraktijk representeert.
Daarnaast komt OSWorld terug als benchmark voor ‘computer use’: een agent moet productiviteitstaken uitvoeren in een visuele desktopomgeving (met vision). OpenAI zegt dat GPT‑5.3‑Codex daar veel sterker scoort dan eerdere GPT-modellen. In OSWorld‑Verified wordt ook een menselijke referentie genoemd: mensen scoren ongeveer 72%.
De kernboodschap van deze sectie: GPT‑5.3‑Codex is niet alleen beter in losse subskills, maar schuift op richting één general-purpose agent die kan redeneren, bouwen én uitvoeren over een brede set real-world technische taken.
Codex als interactieve collaborator: aansturen terwijl de agent werkt
OpenAI stelt dat de bottleneck verschuift: niet zozeer wat agents kúnnen, maar hoe goed je ze kunt aansturen, supervisen en parallel laten werken. In dat verhaal past de Codex app, die volgens OpenAI het managen en dirigeren van agents makkelijker maakt-en met GPT‑5.3‑Codex ook interactiever wordt.
Concreet: in plaats van te wachten op een eindresultaat, krijg je frequente updates over voortgang en belangrijke beslissingen. Je kunt tijdens het uitvoeren vragen stellen, aanpakken bespreken en bijsturen. OpenAI zegt dat GPT‑5.3‑Codex ook ‘hardop’ meeneemt wat het doet, op feedback reageert en je van start tot finish op de hoogte houdt.
Instelling in de Codex app
OpenAI noemt expliciet dat je ‘steering’ tijdens het werken inschakelt via: Settings > General > Follow-up behavior.
Hoe OpenAI Codex gebruikte om GPT-5.3-Codex te trainen en te deployen
Een van de interessantere delen (zeker als je zelf tools bouwt): OpenAI beschrijft hoe Codex intern gebruikt is om de ontwikkeling te versnellen. Ze plaatsen dit in een bredere context: Codex-verbeteringen komen voort uit onderzoeksprojecten die maanden of jaren lopen, maar Codex versnelt nu diezelfde projecten. OpenAI stelt zelfs dat veel researchers/engineers hun werk “fundamenteel anders” zien dan twee maanden geleden.
Ze geven meerdere concrete voorbeelden, opgesplitst over research, engineering, alpha testing en data science:
Research: training run monitoren en debuggen (en verder dan infra)
- Codex werd gebruikt om de training run voor deze release te monitoren en te debuggen.
- Niet alleen infrastructuurproblemen: Codex hielp patronen door de training heen te volgen.
- Het leverde diepgaande analyse over interaction quality.
- Het stelde fixes voor én bouwde rijke applicaties zodat human researchers precies konden zien hoe gedrag verschilde t.o.v. eerdere modellen.
Engineering: harness optimaliseren, edge cases analyseren, GPU-scaling tijdens launch
- Codex hielp de harness voor GPT‑5.3‑Codex te optimaliseren en aan te passen.
- Bij vreemde edge cases die users raakten: teamleden gebruikten Codex om context rendering bugs te vinden.
- Codex hielp root cause analysis doen op lage cache hit rates.
- Tijdens de launch helpt GPT‑5.3‑Codex dynamisch GPU clusters te schalen om traffic surges op te vangen en latency stabiel te houden.
Alpha testing: productiviteitsmeting met regex-classifiers over sessielogs
Tijdens alpha testing wilde een researcher kwantificeren hoeveel extra werk GPT‑5.3‑Codex per ‘turn’ verzet en wat dat aan productiviteit scheelt. OpenAI beschrijft dat GPT‑5.3‑Codex daarop meerdere simpele regex-classifiers bedacht om o.a. dit te schatten:
- Frequentie van clarifications (verduidelijkingsvragen).
- Positieve en negatieve user responses.
- Voortgang op de taak.
Vervolgens draaide het model dit schaalbaar over alle session logs en produceerde een report met conclusies. OpenAI’s samenvatting: builders waren gelukkiger omdat de agent intent beter snapte en per turn meer voortgang maakte, met minder clarifications.
Data science: nieuwe pipelines en rijkere visualisaties voor ‘rare’ alpha-resultaten
OpenAI noemt dat de alpha-data door het andere gedrag van GPT‑5.3‑Codex allerlei ongebruikelijke en contra-intuïtieve resultaten liet zien. Een data scientist werkte met GPT‑5.3‑Codex om nieuwe data pipelines te bouwen en resultaten rijker te visualiseren dan hun standaard dashboarding tools toelieten.
De analyse gebeurde ‘cooperatief’ met Codex: het model vatte key insights over duizenden datapunten samen in minder dan drie minuten.
Opgeteld ziet OpenAI deze voorbeelden als bewijs dat de nieuwe capabilities een versnelling geven aan research, engineering en productteams-niet alleen aan individuele contributors.
Securing the cyber frontier: High capability, dual-use en een zwaardere safety stack
OpenAI besteedt opvallend veel aandacht aan cybersecurity, en dat is logisch: een agent die terminals bedient en end-to-end workflows kan uitvoeren, raakt meteen aan dual-use risico’s. OpenAI meldt dat ze de afgelopen maanden betekenisvolle gains zagen op cybersecurity-taken, en dat ze parallel hebben gewerkt aan ‘strengthened cyber safeguards’.
Twee classificaties/labels die ze expliciet noemen:
- GPT‑5.3‑Codex is het eerste model dat ze onder hun Preparedness Framework classificeren als High capability voor cybersecurity-gerelateerde taken.
- Het is ook het eerste model dat ze direct hebben getraind om software vulnerabilities te identificeren.
OpenAI zegt erbij dat ze geen definitief bewijs hebben dat het end-to-end cyber attacks kan automatiseren. Toch nemen ze een precautionary approach en deployen ze hun meest uitgebreide cybersecurity safety stack tot nu toe.
De genoemde mitigations (allemaal):
- Safety training.
- Automated monitoring.
- Trusted access voor advanced capabilities.
- Enforcement pipelines inclusief threat intelligence.
Omdat cybersecurity inherent dual-use is, beschrijven ze hun aanpak als evidence-based en iteratief: defenders sneller laten vinden en fixen, en misbruik afremmen.
Trusted Access for Cyber (pilot)
Als onderdeel hiervan lanceren ze Trusted Access for Cyber, een pilotprogramma bedoeld om cyber defense research te versnellen. Bron: https://openai.com/index/trusted-access-for-cyber/
Ecosystem safeguards: Aardvark en samenwerking met open-source maintainers
OpenAI investeert ook in ecosystem safeguards. Ze noemen specifiek:
- Het uitbreiden van de private beta van Aardvark, hun security research agent, als eerste offering in een suite van Codex Security products en tools. Bron: https://openai.com/index/introducing-aardvark/
- Samenwerking met open-source maintainers om gratis codebase scanning aan te bieden voor veelgebruikte projecten zoals Next.js. Ze verwijzen naar een disclosure van vulnerabilities die een security researcher met Codex vond: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
$10M aan API credits + het bestaande Cybersecurity Grant Program
Bovenop hun $1M Cybersecurity Grant Program uit 2023 committen ze nu $10M in API credits om cyber defense te versnellen met hun meest capabele modellen-met nadruk op open source software en critical infrastructure systems.
Organisaties die in good-faith security research zitten kunnen API credits en support aanvragen via het Cybersecurity Grant Program: https://openai.com/index/openai-cybersecurity-grant-program/
Beschikbaarheid, tooling en infra-details
GPT‑5.3‑Codex is beschikbaar op betaalde ChatGPT-plannen, overal waar je Codex kunt gebruiken: de app, CLI, IDE extension en web. OpenAI zegt dat ze eraan werken om API access ‘soon’ veilig aan te zetten.
Codex app (macOS) downloadenOpenAI herhaalt ook de performanceclaim aan de productkant: met deze update draaien ze GPT‑5.3‑Codex 25% sneller voor Codex users, dankzij verbeteringen in hun infrastructuur en inference stack (snellere interacties en snellere resultaten).
Op hardware-niveau: GPT‑5.3‑Codex is volgens OpenAI co-designed voor, getraind met en geserveerd op NVIDIA GB200 NVL72 systemen. Ze bedanken NVIDIA expliciet voor de samenwerking.
Wat zegt de benchmark-tabel (Appendix) concreet?
In de appendix staat een tabel met scores (OpenAI vermeldt erbij dat alle evaluaties draaiden op GPT‑5.3‑Codex met xhigh reasoning effort). De belangrijkste cijfers uit die tabel:
- SWE‑Bench Pro (Public): GPT‑5.3‑Codex 56.8% vs GPT‑5.2‑Codex 56.4% vs GPT‑5.2 55.6%.
- Terminal‑Bench 2.0: 77.3% vs 64.0% vs 62.2%.
- OSWorld‑Verified: 64.7% vs 38.2% vs 37.9%.
- GDPval (wins or ties): GPT‑5.3‑Codex 70.9%; GPT‑5.2‑Codex staat als ‘-’; GPT‑5.2 70.9% (high).
- Cybersecurity Capture The Flag Challenges: 77.6% vs 67.4% vs 67.7%.
- SWE‑Lancer IC Diamond: 81.4% vs 76.0% vs 74.6%.
Wat betekent dit voor ons als webdevelopers (incl. WordPress/WooCommerce)?
Ook al gaan OpenAI’s voorbeelden vaak richting benchmark-suites en game demos, is de verschuiving relevant voor het dagelijkse werk: een agent die beter in terminals is, beter intent begrijpt bij ondergespecificeerde prompts, en die je onderweg kunt bijsturen, past precies bij hoe we echte projecten draaien. Denk aan iteratieve debugging, regressies fixen, performance-issues opsporen, build tooling aanpassen, CI/CD bijwerken, security checks draaien en release notes/PRD’s uitwerken.
Tegelijk: de security-sectie maakt duidelijk dat OpenAI dit model dichter bij een ‘high capability’ grens zet voor cyber. In teamcontext betekent dat je scherper moet blijven op toegangsbeheer, audit trails en wat je wel/niet door een agent laat uitvoeren-zeker als je Codex richting productie-omgevingen, secrets of kritieke infrastructuur duwt.
Samenvatting
- GPT‑5.3‑Codex positioneert Codex als brede computer-agent: niet alleen code, maar end-to-end werk op een computer.
- OpenAI claimt 25% snellere runtime voor Codex users en betere prestaties op o.a. Terminal‑Bench 2.0 en OSWorld‑Verified.
- De Codex app wordt interactiever: frequente updates en live bijsturen via Settings > General > Follow-up behavior.
- OpenAI gebruikte vroege versies intern om training/debugging/deployment/analyse te versnellen-met concrete voorbeelden (regex-classifiers, pipelines, GPU scaling).
- Cybersecurity krijgt een zwaardere safety stack: High capability classificatie, vulnerability identification training, Trusted Access for Cyber, Aardvark en $10M API credits voor defense.



Referenties / Bronnen
- Introducing GPT-5.3-Codex
- Introducing the Codex app
- Introducing GPT-5.2-Codex
- GPT-5.3-Codex System Card
- Strengthening cyber resilience
- Trusted Access for Cyber
- Updating our Preparedness Framework
- Introducing Aardvark
- Summaries of CVE-2025-59471 and CVE-2025-59472
- OpenAI Cybersecurity Grant Program
- GDPval
- Annuity Suitability & Best Interest Model (NAIC PDF)
- High yield CDs (FINRA)
Naomi Wijngaard
Frontend-ontwikkelaar en CSS-kunstenaar. Het maken van animaties en interactieve websites is mijn passie. Fan van Svelte en SvelteKit.
Alle berichten

