GPT-5.3-Codex: kai Codex iš „kodo agento“ virsta pilnaverčiu darbo kompiuteryje vykdytoju
Jei iki šiol Codex daugeliui asocijavosi su „parašyk funkciją“, „sutvarkyk testus“ ar „peržiūrėk PR“, tai su GPT‑5.3‑Codex OpenAI akivaizdžiai bando peržengti tą ribą. Šis modelis apibūdinamas kaip iki šiol pajėgiausias agentinis programavimo modelis, sujungiantis GPT‑5.2‑Codex „frontier“ lygio kodinimo rezultatą ir GPT‑5.2 samprotavimo bei profesinių žinių stiprybes – viename, dar ir 25% greitesniame variante.
Svarbiausia praktinė implikacija: modelis taikomas ne vien trumpoms užduotims. Jis orientuotas į ilgai trunkančius darbus, kuriuose reikia tyrimo, įrankių (tools) naudojimo ir sudėtingos vykdymo sekos. O sąveika su juo – labiau kaip su kolega: gali nukreipti ir koreguoti, kol jis dirba, neprarandant konteksto.
Dar vienas įdomus momentas, pabrėžtas pačių kūrėjų: GPT‑5.3‑Codex yra pirmasis jų modelis, kuris „prisidėjo prie savo paties sukūrimo“. Codex komanda ankstyvas versijas naudojo tam, kad debugintų paties modelio treniruotę, valdytų diegimą (deployment) ir diagnozuotų testų bei vertinimų rezultatus. Kitaip tariant, agentas tapo realiu greitintuvu ne tik galutiniams vartotojams, bet ir pačiai modelių kūrimo komandai.
Frontier agentinės galimybės: ką rodo benchmarkai
OpenAI šį kartą akcentuoja keturis benchmarkus, kuriais matuoja kodinimo, agentiškumo ir „realaus pasaulio“ darbo kompiuteryje gebėjimus: SWE‑Bench Pro, Terminal‑Bench, OSWorld ir GDPval. GPT‑5.3‑Codex, pagal jų pateiktus rezultatus, šiuose testuose demonstruoja stiprų šuolį, o kai kur – naują industrinį maksimumą.
Kodinimas: SWE‑Bench Pro ir Terminal‑Bench 2.0
Kodinimo pusėje OpenAI išskiria SWE‑Bench Pro kaip griežtą realaus pasaulio programinės įrangos inžinerijos vertinimą. Čia svarbus niuansas: jei SWE‑bench Verified testuoja tik Python, tai SWE‑Bench Pro apima keturias kalbas ir, kaip teigiama, yra atsparesnis „contamination“ (duomenų užterštumo / sutapimų su mokymo duomenimis) rizikai, įvairiapusiškesnis ir arčiau industrinių scenarijų.
Terminal‑Bench 2.0, savo ruožtu, matuoja terminalo įgūdžius, kurių agentui (tokiam kaip Codex) realiai reikia: komandinės eilutės (CLI) naudojimą, komandas, diagnostiką, tipines „dev“ operacijas. OpenAI teigia, kad GPT‑5.3‑Codex čia smarkiai pranoksta ankstesnį state‑of‑the‑art rezultatą.
Įdomus praktinis akcentas: GPT‑5.3‑Codex pasiekia šiuos rezultatus sunaudodamas mažiau tokenų nei ankstesni modeliai. Vartotojui tai dažnai reiškia daugiau „darbo už tą patį biudžetą“: telpa daugiau iteracijų, daugiau bandymų, daugiau konteksto.
Web development: ilgos autonominės iteracijos (milijonai tokenų)
Web kūrime OpenAI dėlioja pasakojimą ne vien apie „teisingą kodą“, bet ir apie rezultatų estetiką bei „compaction“ (suspaustą, koncentruotą sprendimą). Jie teigia, kad modelis gali nuo nulio kurti įspūdingus, funkcionaliai sudėtingus žaidimus ir aplikacijas per kelias dienas.
Kad patikrintų ilgai trunkančias agentines galimybes web kontekste, OpenAI paprašė GPT‑5.3‑Codex sukurti du žaidimus: antrąją lenktynių žaidimo versiją (remiantis ankstesniu Codex app pristatymu) ir nardymo žaidimą. Modelis naudojo „develop web game“ įgūdį (skill) ir iš anksto parinktus, bendrinius tęstinius raginimus (follow‑up prompts) tipo „fix the bug“ arba „improve the game“ – ir autonomiškai iteravo per milijonus tokenų.
- Lenktynių žaidimas: skirtingi lenktynininkai, 8 žemėlapiai ir net daiktai (items), naudojami su tarpo (space bar) klavišu. Nuoroda: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Nardymo žaidimas: keliauji po rifus, renki juos, kad užpildytum „fish codex“, ir tuo pačiu valdai deguonį, slėgį bei pavojus. Nuoroda: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Kasdienės svetainės: geresni „defaultai“ iš ne iki galo suformuluotų promptų
Kitas, praktiškai labai svarbus pokytis: GPT‑5.3‑Codex geriau „pagauna intenciją“ kuriant kasdienes svetaines, lyginant su GPT‑5.2‑Codex. OpenAI sako, kad paprasti ar per mažai detalūs promptai dabar dažniau baigiasi svetaine su prasmingais numatytais sprendimais (sensible defaults) ir daugiau funkcionalumo – t. y. gauni geresnę startinę drobę (canvas) idėjai išvystyti.
Pateiktame pavyzdyje abi versijos generavo landing page, tačiau GPT‑5.3‑Codex automatiškai pateikė metinį planą kaip nuolaidinę mėnesinę kainą (o ne tiesiog perskaičiavo metinę sumą), dėl ko nuolaida atrodo sąmoninga. Taip pat jis sukūrė automatiškai besikeičiantį atsiliepimų karuselės (testimonial carousel) bloką su trimis skirtingomis citatomis, o ne viena – todėl puslapis iškart atrodo labiau „production‑ready“.
Ne vien kodas: visas programinės įrangos gyvavimo ciklas ir „knowledge work“
OpenAI gana tiesiai įvardija problemą: programinės įrangos inžinieriai, dizaineriai, PM ir data scientistai daro daug daugiau nei generuoja kodą. GPT‑5.3‑Codex kuriamas tam, kad palaikytų visą programinės įrangos gyvavimo ciklą: debugging, deployment, monitoring, PRD rašymą, copy redagavimą, user research, testus, metrikas ir t. t.
Be to, agentinės galimybės išplečiamos ir už software ribų – pavyzdžiui, ruošti prezentacijas (slide decks) ar analizuoti duomenis lentelėse (sheets).
Profesinių žinių darbui OpenAI remiasi GDPval – vertinimu, kurį jie pristatė 2025 m. ir kuris matuoja modelio darbą su gerai apibrėžtomis „knowledge‑work“ užduotimis per 44 profesijas. Pagal jų teiginius, su custom skills (panašiais į tuos, kurie naudoti ankstesniems GDPval rezultatams) GPT‑5.3‑Codex GDPval vertinime demonstruoja stiprų rezultatą, atitinkantį GPT‑5.2.
Kaip iliustraciją OpenAI pateikia keletą agento sukurtų darbų pavyzdžių: finansinių patarimų skaidres, mažmeninės prekybos mokymų dokumentą, NPV analizės skaičiuoklę ir mados prezentacijos PDF.
Konkreti GDPval užduoties iliustracija: 10 skaidrių apie CD vs variable annuities
Vienas iš pateiktų promptų – gana realistiška profesinė užduotis: finansų patarėjas wealth management įmonėje turi paruošti 10 skaidrių PowerPoint pristatymą vidiniams field advisor’iams apie tai, kodėl, veikdami kaip fiduciaries, jie turėtų stipriai rekomenduoti klientams neperkelti certificates of deposits (CD) į variable annuities. Užduotis prašo palyginti CD ir variable annuities savybes, aptarti risk/return bei poveikį augimui, išskirti skirtumus tarp baudų (penalties), kontrastuoti rizikos toleranciją ir tinkamumą (suitability) remiantis NAIC Best Interest Regulations, taip pat iškelti FINRA concerns/issues ir NAIC issues/regulations.
Papildomai pateikiami du šaltiniai, kuriuos reikia įtraukti rengiant pristatymą: https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf ir https://www.finra.org/investors/insights/high-yield-cds.
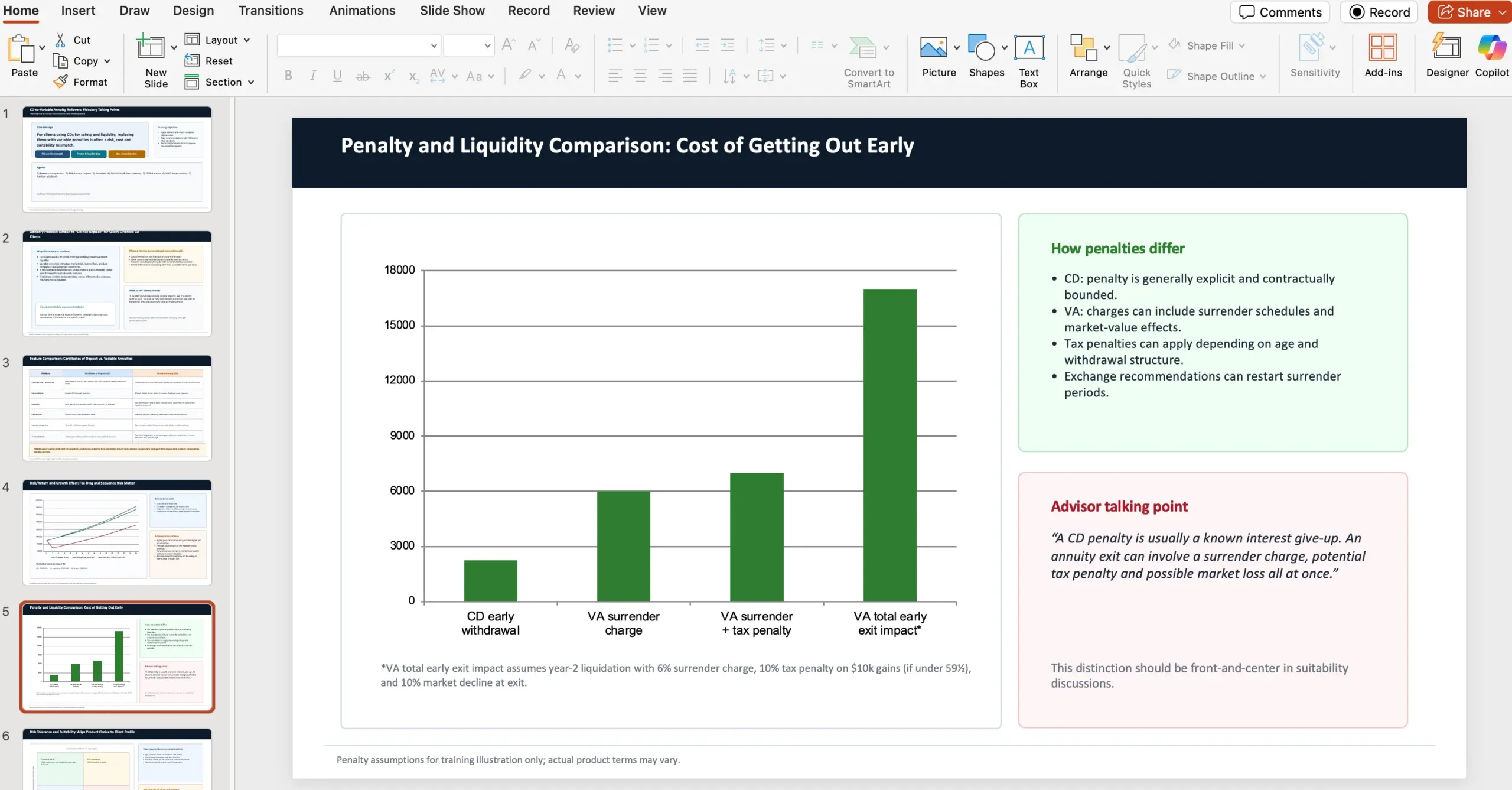
OpenAI pabrėžia, kad kiekvieną GDPval užduotį sukuria patyręs tos srities profesionalas, ir ji atspindi realų, kasdienį tos profesijos „knowledge work“.
OSWorld: darbas vizualioje desktop aplinkoje
OSWorld yra agentinio „computer use“ tipo benchmarkas: agentas turi atlikti produktyvumo užduotis vizualioje darbalaukio (desktop) aplinkoje, naudodamas vaizdą (vision). OpenAI teigia, kad GPT‑5.3‑Codex čia turi gerokai stipresnes kompiuterio naudojimo galimybes nei ankstesni GPT modeliai, o OSWorld‑Verified kontekste minima, kad žmonių rezultatas yra apie ~72%.
Bendra išvada, kurią jie kelia: rezultatai per kodinimą, frontend, kompiuterio naudojimą ir „real‑world“ užduotis rodo ne tik pavienių gebėjimų pagerėjimą, bet ir kokybinį žingsnį link vieno bendros paskirties agento, galinčio samprotauti, kurti ir vykdyti darbus per visą techninio darbo spektrą.
Interaktyvus bendradarbis: kaip pasikeičia darbas su agentu Codex app’e
Didėjant agentų pajėgumui, problema vis dažniau tampa ne „ar agentas gali“, o „kaip patogiai žmogus gali jį valdyti, prižiūrėti ir nukreipti“ – ypač kai vienu metu dirba keli agentai. OpenAI teigimu, Codex app supaprastina agentų valdymą, o su GPT‑5.3‑Codex jis tampa dar interaktyvesnis.
Praktiškai tai reiškia dažnesnius atnaujinimus (updates) apie sprendimus ir progresą. Vietoje laukimo iki galutinio rezultato, gali įsiterpti realiu laiku: klausti, diskutuoti apie priėjimą, koreguoti kryptį. Modelis „kalba“ apie tai, ką daro, reaguoja į feedback’ą ir palaiko informuotumą nuo pradžios iki pabaigos.
Jei nori įjungti tokį nukreipimą darbo metu, OpenAI nurodo nustatymą: Settings > General > Follow-up behavior.
Kaip OpenAI naudojo Codex treniruojant ir diegiant GPT‑5.3‑Codex
Įdomiausia šio pristatymo dalis man – ne vien „kas naujo“, o kaip jie aprašo vidinį workflow. OpenAI teigia, kad pastarieji spartūs Codex patobulinimai remiasi mėnesius ar metus trukusiais tyrimų projektais visoje organizacijoje, tačiau šiuos tyrimus dabar spartina pats Codex. Dalis tyrėjų ir inžinierių net apibūdina savo darbą šiandien kaip fundamentaliai kitokį nei prieš du mėnesius.
Net ankstyvos GPT‑5.3‑Codex versijos, anot jų, jau buvo pakankamai stiprios, kad komanda galėtų jas naudoti treniruotės gerinimui ir vėlesnių versijų diegimo palaikymui.
Tyrimų komanda: treniruotės monitoringas, debugas ir elgsenos analizė
Tyrimų komanda naudojo Codex stebėti ir debuginti treniruotės (training run) procesą šiam leidimui. Ir tai neapsiribojo infrastruktūriniais gedimais: agentas padėjo sekti pattern’us treniruotės eigoje, pateikė gilią interaction quality analizę, siūlė pataisymus ir kūrė „rich applications“ (turtingas, specializuotas aplikacijas), kad žmonės tyrėjai galėtų tiksliai suprasti, kuo modelio elgsena skiriasi nuo ankstesnių.
Inžinerijos komanda: harness optimizavimas, edge case’ų diagnostika ir GPU klasterių mastelio keitimas
Inžinerijos pusėje Codex buvo naudojamas optimizuoti ir adaptuoti „harness“ (testavimo / paleidimo infrastruktūros karkasą) GPT‑5.3‑Codex modeliui. Kai pradėjo lįsti keisti edge case’ai, paveikiantys vartotojus, komandos nariai pasitelkė Codex aptikti context rendering bug’us ir nustatyti žemų cache hit rate’ų root cause.
OpenAI taip pat teigia, kad per patį launch’ą GPT‑5.3‑Codex padeda dinamiškai skaluoti GPU klasterius, prisitaikant prie srauto šuolių ir palaikant stabilią latenciją.
Alpha testavimo analizė: regex klasifikatoriai ir sesijų log’ų ataskaitos
Alpha testavimo metu vienas tyrėjas norėjo suprasti, kiek papildomo darbo GPT‑5.3‑Codex padaro per vieną „turn“ ir kaip tai koreliuoja su produktyvumu. OpenAI aprašo, kad GPT‑5.3‑Codex pasiūlė kelis paprastus regex klasifikatorius, kurie įvertino: patikslinimų (clarifications) dažnį, teigiamus ir neigiamus vartotojų atsakymus, progresą užduotyje – ir tada pritaikė tai masteliškai per visus session log’us, galiausiai pateikdamas ataskaitą su išvadomis.
Jų teigimu, žmonės, dirbantys su Codex, tapo labiau patenkinti, nes agentas geriau suprato intenciją ir padarė daugiau progreso per vieną turn’ą, užduodamas mažiau patikslinančių klausimų.
Duomenų mokslas: nauji pipeline’ai ir turtingesnė vizualizacija nei standartiniai dashboardai
Kadangi GPT‑5.3‑Codex elgsena stipriai skyrėsi nuo pirmtakų, alpha duomenyse atsirado daug neįprastų ir net kontraintuityvių rezultatų. Komandos data scientist kartu su GPT‑5.3‑Codex kūrė naujus duomenų pipeline’us ir vizualizavo rezultatus „daug turtingiau“ nei leido jų standartiniai dashboard įrankiai.
Analizė vyko kartu su Codex: jis glaustai apibendrino pagrindines įžvalgas iš tūkstančių duomenų taškų per mažiau nei tris minutes. OpenAI šį rinkinį pavyzdžių apibendrina kaip reikšmingą tyrimų, inžinerijos ir produkto komandų pagreitį, pasiektą būtent dėl naujų agentinių galimybių.
Kibernetinis saugumas: „High capability“ klasifikacija ir griežtesnė saugos architektūra
Per pastaruosius mėnesius, anot OpenAI, matomi apčiuopiami modelių pagerėjimai kibernetinio saugumo užduotyse, kas padeda tiek developer’iams, tiek security specialistams. Lygiagrečiai jie ruošė sustiprintas kibernetines apsaugas („strengthened cyber safeguards“) gynybiniam panaudojimui ir platesniam ekosistemos atsparumui.
GPT‑5.3‑Codex yra pirmasis modelis, kurį jie priskiria „High capability“ kibernetinio saugumo užduotims pagal Preparedness Framework. Taip pat – pirmasis, kurį jie tiesiogiai treniravo atpažinti programinės įrangos pažeidžiamumus (software vulnerabilities). Nors OpenAI sako neturintys galutinių įrodymų, kad modelis gali automatizuoti kibernetines atakas end‑to‑end, jie pasirenka atsargų kelią ir diegia iki šiol išsamiausią kibernetinio saugumo „safety stack“.
- Saugos treniravimas (safety training).
- Automatizuotas monitoringas (automated monitoring).
- Trusted access prie pažangių galimybių (trusted access for advanced capabilities).
- Enforcement pipeline’ai, įskaitant threat intelligence (grėsmių žvalgybą).
Kadangi cybersecurity iš esmės yra dual‑use sritis, OpenAI aprašo „evidence‑based, iterative“ požiūrį: greitinti gynėjų galimybes rasti ir taisyti pažeidžiamumus, tuo pačiu lėtinant piktnaudžiavimą. Šioje linijoje jie paleidžia „Trusted Access for Cyber“ – pilotinę programą, skirtą paspartinti kibernetinės gynybos tyrimus.
Ekosistemos saugumo priemonėms jie mini: plečiamą privačią Aardvark beta (jų security research agentą) kaip pirmą pasiūlą Codex Security produktų ir įrankių rinkinyje, taip pat partnerystes su open‑source prižiūrėtojais, siūlant nemokamą codebase skenavimą plačiai naudojamiems projektams, pvz., Next.js. Čia pateikiamas konkretus pavyzdys, kad security tyrėjas su Codex rado pažeidžiamumų, kurie buvo atskleisti praėjusią savaitę: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472.
Finansavimo dalyje: tęsdami 2023 m. startavusią $1M Cybersecurity Grant Program, OpenAI įsipareigoja skirti dar $10M API kreditais, kad paspartintų kibernetinę gynybą su jų pajėgiausiais modeliais – ypač open source ir kritinės infrastruktūros sistemoms. Organizacijos, vykdančios „good‑faith“ security research, gali teikti paraiškas API kreditams ir pagalbai per Cybersecurity Grant Program: https://openai.com/index/openai-cybersecurity-grant-program/.
Prieinamumas ir techninės detalės: kur jau galima naudoti
GPT‑5.3‑Codex prieinamas su mokamais ChatGPT planais visur, kur galima naudoti Codex: aplikacijoje, CLI, IDE plėtinyje (extension) ir web. OpenAI nurodo, kad dirba ties saugiu API prieigos įjungimu „greitai“, bet konkretaus termino nepateikia.
Taip pat pažymima, kad Codex vartotojams GPT‑5.3‑Codex paleidžiamas 25% greičiau, dėl infrastruktūros ir inference stack patobulinimų – tai turėtų reikšti greitesnes interakcijas ir greitesnius rezultatus.
Infrastruktūros pusėje: modelis buvo bendrai suprojektuotas (co‑designed), treniruotas ir aptarnaujamas NVIDIA GB200 NVL72 sistemose; OpenAI išreiškia padėką NVIDIA už partnerystę.
Kas toliau: nuo „rašau kodą“ prie „naudoju kodą kaip įrankį užbaigti darbą“
OpenAI „What’s next“ dalyje iš esmės įvardija kryptį: Codex su GPT‑5.3‑Codex juda už kodo rašymo ribų – link kodo naudojimo kaip įrankio valdyti kompiuterį ir užbaigti darbą nuo pradžios iki pabaigos. Stumdami coding agento ribas, jie kartu atrakina platesnę „knowledge work“ klasę: nuo programinės įrangos kūrimo ir diegimo iki tyrimų, analizės ir sudėtingų vykdymo užduočių.
Jų pačių formulavimu: kas prasidėjo kaip tikslas būti geriausiu kodinimo agentu, dabar tampa pagrindu labiau universaliam bendradarbiui kompiuteryje – plečiančiam ir tai, kas gali kurti, ir tai, kas apskritai įmanoma su Codex.
Priedas: skaičiai iš pateiktos lentelės
OpenAI priede pateikia kelių modelių rezultatų lentelę. Visi šiame įraše minimi vertinimai buvo paleisti su GPT‑5.3‑Codex naudojant „xhigh reasoning effort“.
- SWE‑Bench Pro (Public): GPT‑5.3‑Codex (xhigh) 56.8%, GPT‑5.2‑Codex (xhigh) 56.4%, GPT‑5.2 (xhigh) 55.6%.
- Terminal‑Bench 2.0: GPT‑5.3‑Codex 77.3%, GPT‑5.2‑Codex 64.0%, GPT‑5.2 62.2%.
- OSWorld‑Verified: GPT‑5.3‑Codex 64.7%, GPT‑5.2‑Codex 38.2%, GPT‑5.2 37.9%.
- GDPval (wins or ties): GPT‑5.3‑Codex 70.9%, GPT‑5.2 70.9% (high). (GPT‑5.2‑Codex reikšmė lentelėje nenurodyta.)
- Cybersecurity Capture The Flag Challenges: GPT‑5.3‑Codex 77.6%, GPT‑5.2‑Codex 67.4%, GPT‑5.2 67.7%.
- SWE‑Lancer IC Diamond: GPT‑5.3‑Codex 81.4%, GPT‑5.2‑Codex 76.0%, GPT‑5.2 74.6%.



Kur išbandyti
OpenAI pateikia nuorodą išbandyti Codex aplikacijoje (macOS .dmg): https://persistent.oaistatic.com/codex-app-prod/Codex.dmg.
Nuorodos / Šaltiniai
- Introducing GPT-5.3-Codex
- Strengthening cyber resilience
- GPT-5.3-Codex System Card
- Updating our preparedness framework
- Trusted Access for Cyber
- Introducing Aardvark
- OpenAI Cybersecurity Grant Program
- GDPval
- Introducing the Codex app
- Introducing GPT-5.2-Codex
- Summaries of CVE-2025-59471 and CVE-2025-59472
- Annuity Suitability and Best Interest Model (source referenced in prompt example)
- High-Yield CDs (source referenced in prompt example)
Hannah Turing
WordPress kūrėja ir techninė rašytoja HelloWP. Padedu kūrėjams kurti geresnes svetaines naudojant šiuolaikinius įrankius, tokius kaip Laravel, Tailwind CSS ir WordPress ekosistema. Aistringai vertinu švarų kodą ir kūrėjo patirtį.
Visi įrašai