

GPT-5.3-Codex: Codex fa un salto da coding agent a collaboratore completo sul computer
OpenAI ha annunciato GPT‑5.3‑Codex (5 febbraio 2026), un nuovo modello che spinge Codex lungo tutto lo spettro del lavoro professionale su un computer: non solo generazione e review del codice, ma anche ricerca, uso di strumenti, esecuzione di task lunghi e attività “end‑to‑end” tipiche di un team di prodotto.
Il posizionamento è chiaro: è il modello di coding agent più capace finora, unisce i miglioramenti di performance di GPT‑5.2‑Codex con le capacità di ragionamento e conoscenza professionale di GPT‑5.2, in un unico modello. Inoltre, per gli utenti Codex, viene eseguito circa il 25% più velocemente, rendendo più pratiche interazioni ripetute e iterazioni su attività che durano ore o giorni.
C’è un dettaglio interessante per chi segue da vicino come questi sistemi vengono costruiti: GPT‑5.3‑Codex è il primo modello che è stato “strumentale” nel creare sé stesso. Il team Codex ha usato versioni iniziali del modello per fare debugging del training, gestire la parte di deployment e diagnosticare risultati di test e valutazioni, accelerando lo sviluppo in modo inatteso.
Frontier agentic capabilities: perché è un salto di categoria
OpenAI inquadra GPT‑5.3‑Codex come un passo verso un agent general‑purpose: un sistema capace di ragionare, costruire ed eseguire su task reali. A supporto, riporta risultati su quattro benchmark che usa per misurare capacità di coding, agentic behavior e abilità “nel mondo reale”: SWE‑Bench Pro, Terminal‑Bench, OSWorld e GDPval.
Coding: stato dell’arte su SWE‑Bench Pro e Terminal‑Bench 2.0
Sul fronte puramente ingegneristico, GPT‑5.3‑Codex raggiunge prestazioni state‑of‑the‑art su SWE‑Bench Pro, una valutazione focalizzata su task reali di software engineering. OpenAI sottolinea due aspetti di SWE‑Bench Pro rispetto a SWE‑bench Verified: (1) Verified testa solo Python, mentre Pro copre quattro linguaggi; (2) Pro è progettato per essere più resistente alla contaminazione, oltre che più difficile, più vario e più aderente a esigenze industriali.
In parallelo, il modello supera ampiamente la precedente migliore prestazione su Terminal‑Bench 2.0, che misura competenze operative in terminale (fondamentali per un agente come Codex: comandi, toolchain, gestione di ambienti, debug via CLI). Un punto non secondario: OpenAI nota che GPT‑5.3‑Codex ottiene questi risultati usando meno token rispetto ai modelli precedenti, con l’effetto pratico di lasciare più margine agli utenti per “costruire di più” dentro una sessione.
Web development: iterazioni autonome su giochi e app, per giorni
Per testare capacità agentiche di lungo periodo nel web development, OpenAI racconta un esperimento molto concreto: chiedere a GPT‑5.3‑Codex di costruire due giochi da zero e iterarli autonomamente.
- Una versione 2 del racing game già usato nel lancio della Codex app: include diversi piloti, otto mappe e perfino oggetti attivabili con la barra spaziatrice. Link per giocare: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Un diving game ambientato su vari reef: esplori, collezioni elementi per completare un “fish codex”, e nel frattempo gestisci ossigeno, pressione e hazard. Link per giocare: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Il setup descritto è interessante per chi costruisce agent: OpenAI parla di una skill di tipo “develop web game” e di prompt di follow‑up preselezionati e generici (esempi: “fix the bug”, “improve the game”). Da lì, GPT‑5.3‑Codex ha iterato autonomamente sui progetti per milioni di token, accumulando miglioramenti progressivi e mantenendo il contesto della direzione di prodotto.
Sempre lato web, viene evidenziato un miglioramento “quotidiano”: quando chiedi a Codex di creare siti semplici o con prompt poco specifici, GPT‑5.3‑Codex tende a partire da default più sensati, con più funzionalità, offrendo un canvas iniziale più vicino a qualcosa di “production‑ready”.
Un esempio riportato riguarda la generazione di una landing page: rispetto a GPT‑5.2‑Codex, GPT‑5.3‑Codex avrebbe reso più chiara la logica di pricing (piano annuale mostrato come prezzo mensile scontato) e avrebbe inserito un testimonial carousel con più citazioni distinte, rendendo la pagina complessivamente più completa già al primo output.
Beyond coding: supporto all’intero ciclo di vita del software (e non solo)
Il messaggio qui è che un team tecnico non vive di solo codice: GPT‑5.3‑Codex è pensato per supportare tutto il lavoro nel ciclo di vita del software, includendo debugging, deployment, monitoring, scrittura di PRD, editing di copy, user research, test, metriche e altro.
E va anche oltre il software in senso stretto: l’agent può aiutare a produrre deliverable come slide deck o fare analisi su fogli di calcolo.
Per misurare il “knowledge work”, OpenAI richiama GDPval (pubblicato nel 2025), una valutazione su task ben specificati distribuiti su 44 occupazioni. In GDPval, GPT‑5.3‑Codex mostra performance forti e allinea GPT‑5.2 su questo asse, mentre mantiene il vantaggio sulle capacità più agentiche e operative.
Tra gli esempi di output prodotti dall’agent vengono citati: slide di consulenza finanziaria, un documento di training retail, un foglio di calcolo per analisi NPV e una presentazione PDF in ambito fashion.
Esempio (GDPval): contesto del task riportato da OpenAI
Nel post viene incluso un prompt completo: l’agent deve agire come consulente finanziario in una wealth management firm e preparare una presentazione PowerPoint da 10 slide per advisor interni, spiegando perché (in ottica fiduciaria) sconsigliare il passaggio da certificate of deposits a variable annuities proposto da banker locali. La consegna richiede confronti su caratteristiche, risk/return e crescita, differenze di penali, suitability e risk tolerance con riferimento a NAIC Best Interest Regulations, e menzione di concern FINRA e regolazioni NAIC. Il prompt include anche due fonti web: https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf e https://www.finra.org/investors/insights/high-yield-cds.
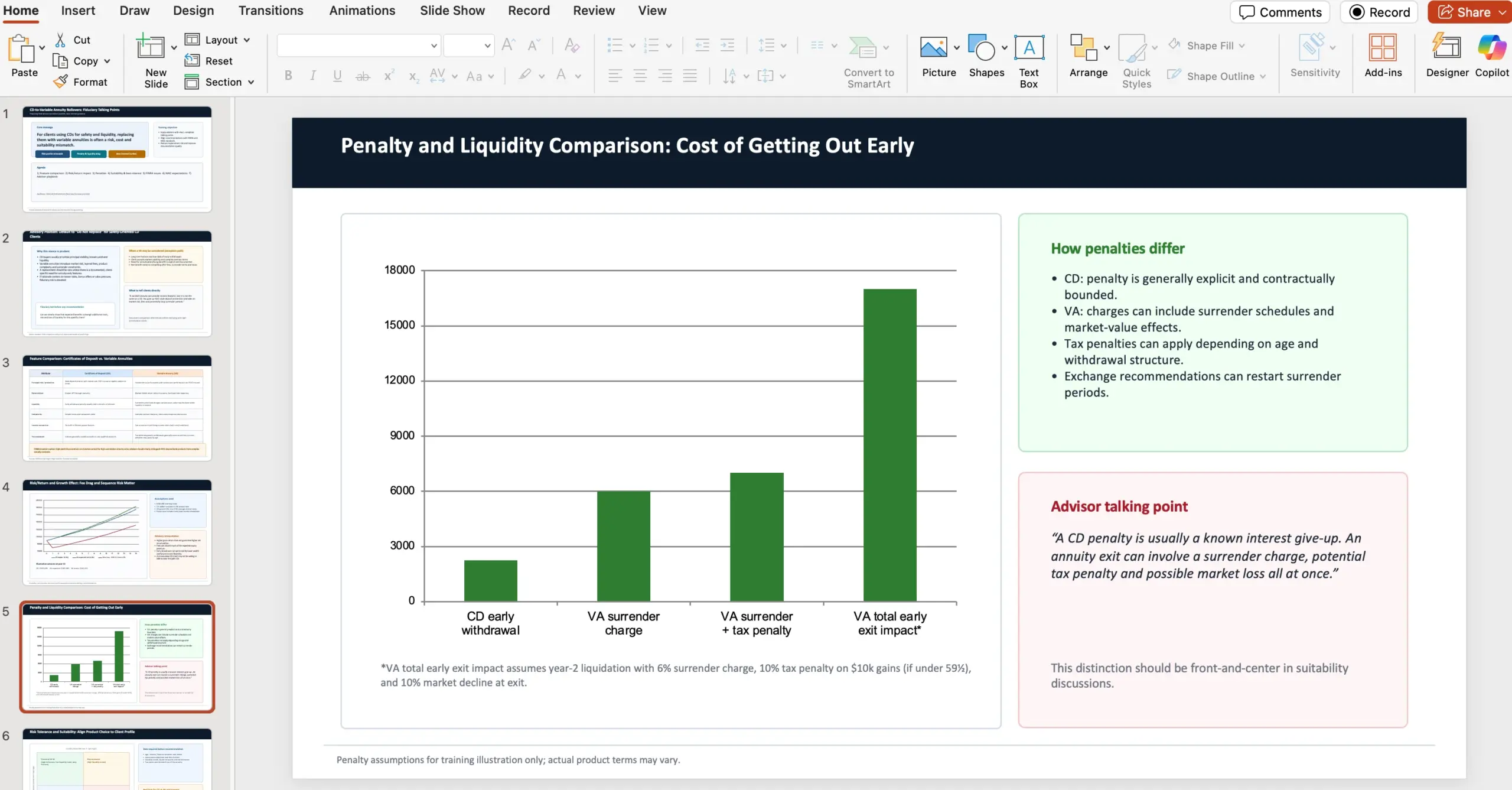
OpenAI sottolinea anche la natura della suite di benchmark: ogni task in GDPval è disegnato da un professionista esperto e riflette lavoro reale della specifica occupazione.
Sul fronte “computer use”, viene citato OSWorld, un benchmark agentico dove l’agent completa task di produttività in un ambiente desktop visuale (quindi con visione). GPT‑5.3‑Codex mostrerebbe capacità di uso del computer molto più forti dei precedenti GPT. Nel post si riporta anche un riferimento per OSWorld‑Verified: gli umani segnano circa ~72%.
Un collaboratore interattivo: supervisionare e guidare l’agent mentre lavora
Un punto spesso sottovalutato negli agent è l’interazione: quando gli agent diventano più potenti, il collo di bottiglia si sposta su quanto è facile per gli umani dirigerli e supervisionarli, magari in parallelo. OpenAI posiziona la Codex app come lo strumento per gestire e indirizzare agent in modo più semplice, e con GPT‑5.3‑Codex la collaborazione diventa più “in tempo reale”.
Con il nuovo modello, Codex fornisce aggiornamenti frequenti su decisioni chiave e progressi. Invece di aspettare l’output finale, puoi intervenire mentre lavora: fare domande, discutere approcci, reindirizzare la soluzione. Il modello esplicita cosa sta facendo, risponde al feedback e mantiene l’utente “nel loop” dall’inizio alla fine.
Dove si abilita lo steering nell’app
Nella Codex app: Settings > General > Follow-up behavior. L’obiettivo è permettere di guidare l’agent mentre sta eseguendo il task, senza perdere contesto.
Come OpenAI ha usato Codex per addestrare e distribuire GPT‑5.3‑Codex
OpenAI racconta che i miglioramenti recenti di Codex derivano da progetti di ricerca portati avanti per mesi o anni, ma che proprio Codex sta accelerando questi cicli: diversi ricercatori e ingegneri descrivono il loro lavoro “oggi” come radicalmente diverso rispetto a due mesi prima, grazie all’apporto dell’agent.
Già le versioni iniziali di GPT‑5.3‑Codex erano sufficientemente forti da essere usate per migliorare il training e supportare il deployment di versioni successive. Nel post vengono dati esempi specifici (e utili per farsi un’idea pratica di dove un agent fa davvero risparmiare tempo).
- Il team di ricerca ha usato Codex per monitorare e fare debug del training run per questa release.
- Non solo debug infrastrutturale: Codex ha aiutato a tracciare pattern durante il training, ha prodotto analisi profonde sulla qualità delle interazioni, ha proposto fix e ha costruito applicazioni ricche per permettere ai ricercatori di capire con precisione come il comportamento del modello differisse rispetto ai modelli precedenti.
- Il team engineering ha usato Codex per ottimizzare e adattare l’harness (l’infrastruttura/impalcatura di test ed esecuzione) per GPT‑5.3‑Codex.
- Quando sono emersi edge case anomali per utenti, Codex è stato usato per identificare bug di context rendering e per risalire alla root cause di basse cache hit rates.
- Durante il lancio, GPT‑5.3‑Codex continua ad aiutare a scalare dinamicamente cluster GPU in risposta a picchi di traffico e a mantenere la latenza stabile.
- In alpha testing, un ricercatore ha voluto stimare quanta “produttività per turn” aggiuntiva offrisse il modello: GPT‑5.3‑Codex ha proposto semplici classifier regex per stimare frequenza di chiarimenti, risposte utente positive/negative e avanzamento del task; poi li ha eseguiti in modo scalabile sui log di sessione e ha prodotto un report conclusivo.
- OpenAI riporta che, con l’agent che capiva meglio l’intento e avanzava di più per turn, le persone che costruivano con Codex erano più soddisfatte e servivano meno domande di chiarimento.
- Dato che GPT‑5.3‑Codex è molto diverso dai predecessori, dai test alpha sono usciti risultati insoliti e controintuitivi: un data scientist ha lavorato con Codex per costruire nuove pipeline dati e visualizzazioni più ricche rispetto ai tool standard di dashboarding; i risultati sono stati co‑analizzati con Codex, che ha sintetizzato insight chiave su migliaia di data point in meno di tre minuti.
Presi singolarmente, questi esempi mostrano l’ampiezza d’uso di un agente in un’organizzazione che costruisce modelli; presi insieme, OpenAI li presenta come prova di una accelerazione tangibile per ricerca, ingegneria e product.
Sicurezza: “cyber frontier” e approccio precauzionale
Negli ultimi mesi, OpenAI dice di aver visto miglioramenti significativi nelle capacità su task di cybersecurity, con beneficio sia per developer sia per professionisti della sicurezza. In parallelo, l’azienda dichiara di aver lavorato a misure di difesa più robuste (rimandando a un post specifico su “strengthening cyber resilience”).
Un passaggio importante: GPT‑5.3‑Codex è il primo modello classificato come “High capability” per task di cybersecurity sotto il Preparedness Framework di OpenAI, ed è anche il primo direttamente addestrato per identificare vulnerabilità software.
OpenAI chiarisce che non ha evidenza definitiva che il modello possa automatizzare attacchi end‑to‑end, ma adotta comunque una postura prudente: deploy della cybersecurity safety stack più completa finora, includendo:
- safety training
- monitoraggio automatizzato
- trusted access per capacità avanzate
- pipeline di enforcement, inclusa threat intelligence
Dato che la cybersecurity è intrinsecamente dual‑use, l’approccio dichiarato è evidence‑based e iterativo: accelerare chi difende (trovare e correggere vulnerabilità) e rallentare l’abuso.
In questo contesto, OpenAI lancia Trusted Access for Cyber, un programma pilota per accelerare la ricerca difensiva.
Sul fronte ecosistema, vengono citate due iniziative:
- Espansione della private beta di Aardvark, un security research agent, come prima offerta della suite di prodotti e tool Codex Security.
- Partnership con maintainer open source per offrire scanning gratuito di codebase molto usate, includendo Next.js. Nel post viene richiamato un caso in cui un security researcher ha usato Codex per trovare vulnerabilità poi divulgate (link Vercel): https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
Infine, OpenAI amplia l’impegno economico: oltre al $1M Cybersecurity Grant Program lanciato nel 2023, dichiara $10M in API credits per accelerare la cyber defense con i modelli più capaci, con un focus particolare su open source e infrastrutture critiche. Le organizzazioni coinvolte in ricerca di sicurezza in good faith possono fare richiesta tramite il Cybersecurity Grant Program: https://openai.com/index/openai-cybersecurity-grant-program/.
Disponibilità, performance e infrastruttura
Sul piano pratico: GPT‑5.3‑Codex è disponibile nei piani ChatGPT a pagamento, ovunque si possa usare Codex: app, CLI, estensione IDE e web. OpenAI aggiunge che sta lavorando per abilitare accesso via API in modo sicuro “a breve” (senza indicare una data precisa).
OpenAI ribadisce anche il miglioramento di velocità per gli utenti Codex: con questa release, GPT‑5.3‑Codex viene eseguito circa il 25% più velocemente, grazie a miglioramenti di infrastruttura e inference stack, quindi con interazioni e risultati più rapidi.
Nota hardware: GPT‑5.3‑Codex è stato co‑progettato per, addestrato con e servito su sistemi NVIDIA GB200 NVL72, con ringraziamento esplicito a NVIDIA per la partnership.
Cosa cambia davvero per noi sviluppatori (e per i team di prodotto)
La lettura più utile, al di là dei numeri, è che Codex viene spinto oltre il paradigma “scrive codice” verso “usa il codice come strumento per operare al computer”: ricerca, implementazione, debug, test, deploy, monitoraggio e produzione di artefatti (documenti, report, slide, sheet) dentro un flusso unico e supervisionabile.
OpenAI lo descrive come un passaggio da “best coding agent” a collaboratore più generale sul computer: si allarga sia la platea di chi può costruire, sia il tipo di lavoro che può essere portato a termine con Codex.
Appendice: numeri dichiarati nei benchmark
Nel post viene riportata una tabella riepilogativa (tutte le valutazioni indicate sono state eseguite su GPT‑5.3‑Codex con xhigh reasoning effort). Ecco i valori comunicati:
- SWE‑Bench Pro (Public) – GPT‑5.3‑Codex (xhigh): 56.8% | GPT‑5.2‑Codex (xhigh): 56.4% | GPT‑5.2 (xhigh): 55.6%
- Terminal‑Bench 2.0 – GPT‑5.3‑Codex (xhigh): 77.3% | GPT‑5.2‑Codex (xhigh): 64.0% | GPT‑5.2 (xhigh): 62.2%
- OSWorld‑Verified – GPT‑5.3‑Codex (xhigh): 64.7% | GPT‑5.2‑Codex (xhigh): 38.2% | GPT‑5.2 (xhigh): 37.9%
- GDPval (wins or ties) – GPT‑5.3‑Codex (xhigh): 70.9% | GPT‑5.2‑Codex: – | GPT‑5.2 (xhigh): 70.9% (high)
- Cybersecurity Capture The Flag Challenges – GPT‑5.3‑Codex (xhigh): 77.6% | GPT‑5.2‑Codex (xhigh): 67.4% | GPT‑5.2 (xhigh): 67.7%
- SWE‑Lancer IC Diamond – GPT‑5.3‑Codex (xhigh): 81.4% | GPT‑5.2‑Codex (xhigh): 76.0% | GPT‑5.2 (xhigh): 74.6%
Link utili citati nell’annuncio
- Download Codex app (macOS .dmg): https://persistent.oaistatic.com/codex-app-prod/Codex.dmg
- Racing game v2 demo: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Diving game demo: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
- GDPval: https://openai.com/index/gdpval/
- Strengthening cyber resilience: https://openai.com/index/strengthening-cyber-resilience/
- GPT-5.3-Codex System Card (high capability): https://openai.com/index/gpt-5-3-codex-system-card/
- Preparedness Framework: https://openai.com/index/updating-our-preparedness-framework/
- Trusted Access for Cyber: https://openai.com/index/trusted-access-for-cyber/
- Aardvark: https://openai.com/index/introducing-aardvark/
- Disclosure CVE Next.js (Vercel): https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
- Cybersecurity Grant Program: https://openai.com/index/openai-cybersecurity-grant-program/


Francesca Rossi
Caporedattrice del team italiano, specialista in design system e librerie di componenti. Non posso vivere senza Figma e Storybook. Il mio obiettivo è un'interfaccia utente coerente.
Tutti gli articoli

