

GPT-5.3-Codex: Codex prelazi iz “coding agenta” u punokrvnog suradnika na računalu
OpenAI je 5. veljače 2026. izbacio GPT‑5.3‑Codex – novi model koji bitno širi ono što Codex može odraditi na računalu. Ako si do sada Codex doživljavao primarno kao agenta za pisanje i review koda, ova verzija ga gura prema nečemu što je bliže “kolegi” koji može istraživati, koristiti alate, izvršavati kompleksne korake i raditi dugo bez gubitka konteksta.
Ključna poruka objave: GPT‑5.3‑Codex spaja dvije linije napretka u jedan model – frontier coding performanse iz GPT‑5.2‑Codex te rezoniranje i “professional knowledge” sposobnosti GPT‑5.2 – i uz to radi oko 25% brže. Taj miks je praktično važan kad agent mora odraditi višesatne ili višednevne zadatke koji uključuju iteracije, provjere, prepravke i rad kroz više alata.
Što je zapravo novo: agentičke sposobnosti na razini “frontiera”
OpenAI u tekstu naglašava da GPT‑5.3‑Codex postiže industrijski vrh na SWE-Bench Pro i Terminal-Bench, uz snažne rezultate na OSWorld i GDPval. Ta četiri benchmarka koriste interno kao miks mjerenja: real-world softverski rad, terminal vještine, “computer-use” (rad u vizualnom desktop okruženju) i profesionalni knowledge work.
Coding: SWE-Bench Pro i Terminal-Bench 2.0
Za kontekst, SWE‑Bench Pro je tvrđa varijanta SWE‑Bencha koja je (prema objavi) otpornija na kontaminaciju, raznolikija i bliža industrijskim scenarijima. Bitna razlika u odnosu na SWE‑bench Verified je što Pro pokriva četiri jezika, dok Verified testira samo Python.
Na Terminal‑Bench 2.0 GPT‑5.3‑Codex ide značajno iznad prethodnog state‑of‑the‑arta. Terminal‑Bench mjeri vještine koje su agentu tipa Codex praktično nužne: rad u terminalu, izvođenje naredbi, navigacija, skriptiranje i sličan “hands-on” dio automatizacije.
Zanimljiv detalj: OpenAI navodi da GPT‑5.3‑Codex postiže te rezultate s manje tokena nego raniji modeli – što se u praksi prevodi u manje “potrošnje” na nepotrebno brbljanje i više budžeta za stvarnu izgradnju (više koraka, više iteracija, više outputa unutar istog limita).
Web development: dugotrajna autonomna iteracija kroz milijune tokena
OpenAI je posebno testirao web dev i “long-running agentic” sposobnosti tako da su GPT‑5.3‑Codexu dali zadatak izgradnje dviju web igara: (1) drugu verziju racing igre iz objave o Codex app launchu te (2) diving igru.
Ono što je ovdje bitno nije samo da je model generirao inicijalni prototip, nego da je uz skill “develop web game” i unaprijed odabrane generičke follow-up promptove poput “fix the bug” ili “improve the game” autonomno iterirao kroz milijune tokena. To je dosta dobar signal za scenarije gdje želiš agenta koji sam radi backlog sitnih poboljšanja, polira UI, popravlja rubne bugove i zatvara “production-ready” rupe bez toga da mu svaki korak mikromenadžiraš.
- Racing igra: različiti vozači, osam mapa i čak itemi koji se koriste space barom. Demo je dostupan ovdje: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Diving igra: istraživanje grebena, skupljanje kolekcija za “fish codex”, uz upravljanje kisikom, pritiskom i hazardima. Demo je ovdje: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Još jedna praktična promjena za svakodnevni web: GPT‑5.3‑Codex bolje hvata namjeru kad ga pitaš za “običnu” web stranicu. OpenAI kaže da jednostavni ili nedovoljno specificirani promptovi sada defaultaju na stranice s više funkcionalnosti i razumnim zadanim vrijednostima – što znači bolju početnu bazu za daljnji rad.
Konkretan primjer iz objave je usporedba dviju landing stranica gdje je GPT‑5.3‑Codex automatski prikazao godišnji plan kao sniženu mjesečnu cijenu (umjesto da samo pomnoži godišnji total), te dodao automatski prelazeći testimonial carousel s tri različita citata umjesto jednog. Poanta: output je “puniji” i bliži productionu bez dodatnih upita.
Beyond coding: agent koji pokriva cijeli softverski lifecycle (i šire)
Razvoj softvera u praksi nije samo generiranje koda. U objavi se eksplicitno nabrajaju aktivnosti koje GPT‑5.3‑Codex cilja podržati kroz cijeli lifecycle: debugging, deploying, monitoring, pisanje PRD-ova (Product Requirements Document), uređivanje copyja, user research, testovi, metrike i još dosta toga.
I tu se ne staje na “software”: naglasak je da agentičke sposobnosti idu i prema općem “knowledge worku” – izrada slide deckova, analiza podataka u tablicama (spreadsheets), dokumenti i slični deliverableovi koje rade product, data i biz timovi.
Za mjerenje tog dijela OpenAI se oslanja na GDPval (evaluation objavljen 2025.) koji pokriva dobro specificirane zadatke znanja kroz 44 zanimanja. GPT‑5.3‑Codex tu, prema objavi, matcha GPT‑5.2.
Primjer knowledge-work zadatka (GDPval): financijski savjetnički slide deck
U objavi je dan konkretan primjer prompta koji je vrlo blizu stvarnom korporativnom zadatku. Scenarij: financijski savjetnik u wealth management firmi treba pripremiti internu PowerPoint prezentaciju (10 slajdova) za field advisore, s talking pointovima zašto (kao fiducijari) trebaju snažno preporučiti protiv prebacivanja certificates of deposits (CD) u variable annuities, unatoč privlačnosti “market returna” i doživotne mjesečne isplate.
Prompt dodatno specificira što prezentacija mora pokriti: usporedbu featurea između CD-a i variable annuities uz FINRA izvore i upozorenja investitorima; risk/return i utjecaj na rast; razlike u penalima; risk tolerance i suitability uz NAIC Best Interest Regulations; FINRA concerns/issues; NAIC issues/regulations. Također su navedeni izvori koje treba koristiti: https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf i https://www.finra.org/investors/insights/high-yield-cds
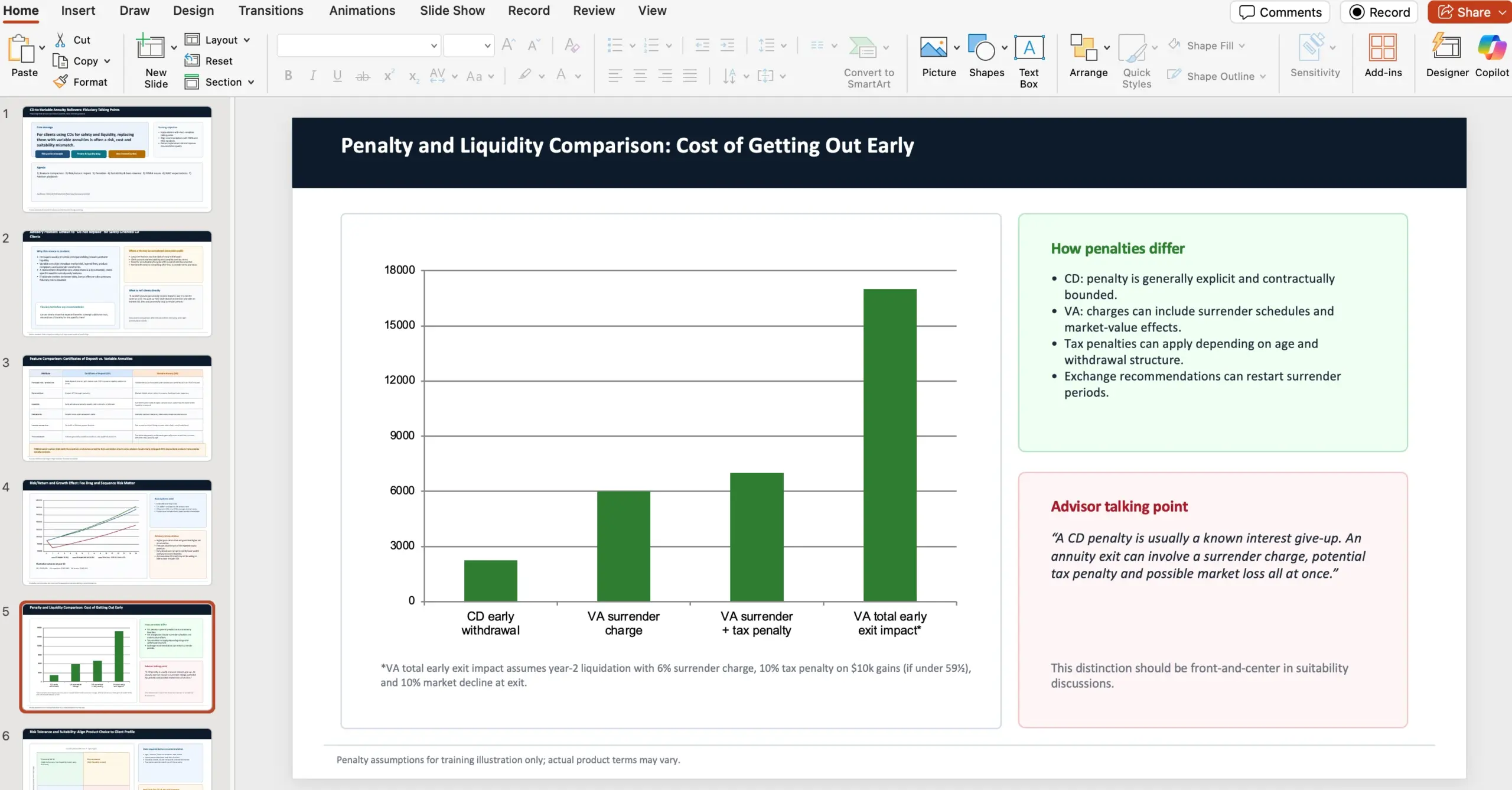
OpenAI napominje da su GDPval zadaci dizajnirani od strane iskusnih profesionalaca i reflektiraju realan posao u tom zanimanju – što je važna distinkcija naspram generičkih “napravi prezentaciju” promptova bez domenskih zahtjeva i izvora.
OSWorld: “computer-use” u vizualnom desktop okruženju
OSWorld je benchmark gdje agent mora odraditi produktivne zadatke u vizualnom desktop okruženju (drugim riječima, nije samo CLI i kod editor, nego klikanje, navigacija i rad kroz UI). OpenAI tvrdi da GPT‑5.3‑Codex pokazuje znatno jače “computer use” sposobnosti od ranijih GPT modela.
U objavi se navodi i referenca da u OSWorld‑Verified modeli koriste vision za razne computer taskove, te da ljudi imaju oko ~72%.
Codex kao interaktivni suradnik: manje čekanja na “final output”, više vođenja u hodu
Kako agenti postaju sposobniji, usko grlo se pomiče s “može li to agent” na “koliko ga lako možeš usmjeravati, nadzirati i paralelno voditi”. U tom kontekstu Codex app dobiva važniju ulogu, a s GPT‑5.3‑Codexom interakcija postaje još aktivnija.
OpenAI opisuje da Codex sada daje češće updateove o ključnim odlukama i napretku, tako da si stalno “u toku” dok agent radi. Umjesto da čekaš gotov rezultat, možeš u realnom vremenu pitati pitanja, raspravljati pristup i usmjeravati prema rješenju. Model prolazi kroz to što radi, reagira na feedback i drži te informiranim od početka do kraja.
Ako želiš da te model možeš usmjeravati dok radi, u Codex appu se to uključuje ovdje: Settings > General > Follow-up behavior.
Meta-moment: GPT‑5.3‑Codex je pomogao izgraditi samog sebe
Jedna od zanimljivijih tvrdnji iz objave je da je GPT‑5.3‑Codex prvi model koji je bio instrumentalno uključen u vlastito nastajanje. Codex tim je koristio rane verzije da: debugira vlastiti training, upravlja vlastitim deploymentom te dijagnosticira test rezultate i evaluacije. U tekstu doslovno kažu da ih je iznenadilo koliko je Codex ubrzao vlastiti razvoj.
Kako su Codex koristili u treningu i deployu (konkretni primjeri iz prakse)
OpenAI opisuje da su brza poboljšanja Codexa rezultat istraživačkih projekata koji traju mjesecima ili godinama, ali i da ih Codex sada ubrzava. Dosta ljudi interno navodno opisuje da im je posao danas fundamentalno drugačiji nego prije dva mjeseca, baš zbog toga koliko agent preuzima operativnih zadataka.
Primjeri koje navode su vrlo “engineering-realni”:
- Research tim je koristio Codex za monitoring i debugging samog training runa, ali i za napredniju analizu: praćenje patterna kroz trening, dubinsku analizu “interaction quality”, prijedloge fixeva te izgradnju aplikacija koje pomažu ljudskim istraživačima precizno razumjeti kako se ponašanje razlikuje od prethodnih modela.
- Engineering tim je koristio Codex da optimizira i prilagodi harness (test/exec okruženje) za GPT‑5.3‑Codex. Kad su se pojavili čudni edge-caseovi kod korisnika, Codex je pomogao identificirati context rendering bugove i detektirati root cause za niske cache hit rateove.
- Tijekom samog launcha GPT‑5.3‑Codex pomaže dinamički skalirati GPU klastere kako bi se odgovorilo na prometne skokove i zadržala stabilna latencija.
- U alpha testiranju jedan istraživač je htio procijeniti koliko dodatnog posla model odradi “per turn” i što to znači za produktivnost. GPT‑5.3‑Codex je predložio nekoliko jednostavnih regex klasifikatora za procjenu frekvencije clarifications, pozitivnih i negativnih user reakcija te napretka po zadatku, zatim je to skalabilno pokrenuo nad session logovima i izradio report.
- Zaključak iz tih logova: ljudi koji rade s Codexom bili su zadovoljniji jer je agent bolje pogađao namjeru i pravio više napretka po turnu, uz manje dodatnih pitanja.
- Zbog toga što je GPT‑5.3‑Codex “drugačiji” od prethodnika, alpha test podaci su imali dosta neobičnih i kontraintuitivnih rezultata. Data scientist je s Codexom izgradio nove data pipelineove i vizualizacije bogatije od standardnih dashboard alata; zatim su rezultate ko-analizirali s Codexom, koji je sažeo ključne insightove kroz tisuće data pointova u manje od tri minute.
Kad se sve zbroji, poruka je da agentičke sposobnosti nisu samo “wow demo”, nego ubrzanje koje se vidi kroz research, engineering i product operacije – od treninga do productiona.
Cybersecurity: “High capability” klasifikacija i pojačani sigurnosni sloj
OpenAI navodi da su u zadnjih nekoliko mjeseci vidjeli značajan rast performansi na cybersecurity zadacima, korisno i developerima i security profesionalcima. Paralelno su (prema vlastitoj objavi) pripremali jače cyber safeguards kako bi podržali defensive use i otpornost ekosustava.
GPT‑5.3‑Codex je prvi model koji klasificiraju kao “High capability” za cybersecurity-related zadatke prema njihovom Preparedness Frameworku, i prvi koji su direktno trenirali da identificira softverske ranjivosti. Iako kažu da nemaju definitivne dokaze da može automatizirati cyber napade end-to-end, pristup je predostrožan: deployaju najkompletniji cybersecurity safety stack do sada.
- safety training
- automatizirani monitoring
- trusted access za napredne capabilityje
- enforcement pipelineovi uključujući threat intelligence
Zbog dual-use prirode cybersecurityja, kažu da idu iterativno i evidence-based: ubrzati defensivne use-caseove (pronalazak i popravljanje ranjivosti), a usporiti zloupotrebu.
U tom kontekstu lansiraju i Trusted Access for Cyber, pilot program za ubrzavanje istraživanja cyber obrane.
Na razini ekosustava spominju i dodatne mjere: širenje private bete Aardvarka (security research agent) kao prve ponude u “Codex Security” suiteu, te partnerstva s open-source maintainerima za besplatno skeniranje codebasea široko korištenih projekata poput Next.js-a. U objavi se navodi primjer gdje je security istraživač koristio Codex za pronalazak ranjivosti koje su objavljene prošlog tjedna: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
Financijski dio: uz $1M Cybersecurity Grant Program pokrenut 2023., OpenAI se obvezuje na dodatnih $10M u API kreditima kako bi ubrzali cyber defense s najjačim modelima, posebno za open source i critical infrastructure sustave. Organizacije koje rade good-faith security research mogu se prijaviti za API kredite i podršku kroz Cybersecurity Grant Program.
Dostupnost, performanse i infrastruktura
GPT‑5.3‑Codex je dostupan uz plaćene ChatGPT planove, svugdje gdje koristiš Codex: u aplikaciji, CLI-u, IDE ekstenziji i na webu. Za API pristup navode da rade na tome da ga sigurno omoguće uskoro (dakle: nije još generalno otvoreno, prema objavi).
OpenAI dodatno naglašava da Codex korisnicima sada pokreću GPT‑5.3‑Codex oko 25% brže zahvaljujući poboljšanjima u infrastrukturi i inference stacku, što se prevodi u brže interakcije i brže rezultate.
Hardverski detalj: GPT‑5.3‑Codex je co-designed za, treniran uz i serviran na NVIDIA GB200 NVL72 sustavima, uz napomenu o partnerstvu s NVIDIA-om.
Što dalje: Codex kao opći agent na računalu
U zaključku objave OpenAI pozicionira GPT‑5.3‑Codex kao korak izvan “pisanja koda” prema korištenju koda kao alata za upravljanje računalom i završavanje posla end-to-end. U isto vrijeme, guranje granica coding agenta otvara i širi spektar knowledge worka: od izgradnje i deploya softvera do istraživanja, analize i izvršavanja kompleksnih zadataka.
Drugim riječima, cilj se pomiče od “najboljeg coding agenta” prema temelju za generalnijeg suradnika na računalu – i to je vjerojatno najvažniji strateški signal cijele objave.
Appendix: brojke s benchmarka (xhigh reasoning effort)
U dodatku objave OpenAI daje tablicu s rezultatima. Navode i fusnotu da su sve evaluacije u blogu rađene na GPT‑5.3‑Codex uz xhigh reasoning effort.
- SWE-Bench Pro (Public): GPT-5.3-Codex (xhigh) 56.8% | GPT-5.2-Codex (xhigh) 56.4% | GPT-5.2 (xhigh) 55.6%
- Terminal-Bench 2.0: GPT-5.3-Codex (xhigh) 77.3% | GPT-5.2-Codex (xhigh) 64.0% | GPT-5.2 (xhigh) 62.2%
- OSWorld-Verified: GPT-5.3-Codex (xhigh) 64.7% | GPT-5.2-Codex (xhigh) 38.2% | GPT-5.2 (xhigh) 37.9%
- GDPval (wins or ties): GPT-5.3-Codex (xhigh) 70.9% | GPT-5.2-Codex (xhigh) – | GPT-5.2 (xhigh) 70.9% (high)
- Cybersecurity Capture The Flag Challenges: GPT-5.3-Codex (xhigh) 77.6% | GPT-5.2-Codex (xhigh) 67.4% | GPT-5.2 (xhigh) 67.7%
- SWE-Lancer IC Diamond: GPT-5.3-Codex (xhigh) 81.4% | GPT-5.2-Codex (xhigh) 76.0% | GPT-5.2 (xhigh) 74.6%



Marko Kovačić
SaaS programer i stručnjak za pretplatničke modele. Zanimaju me Stripe i sustavi za ponavljajuća plaćanja. Održivi poslovni model je ključ.
Svi članciViše od Marko Kovačić
 Europski akt o pristupačnosti je na snazi: što sada moraju napraviti WordPress vlasnici, agencije i developeri
Europski akt o pristupačnosti je na snazi: što sada moraju napraviti WordPress vlasnici, agencije i developeri
 WP-Bench: službeni WordPress AI benchmark koji konačno mjeri “znaš li WordPress?”
WP-Bench: službeni WordPress AI benchmark koji konačno mjeri “znaš li WordPress?”
 Kritična ranjivost u WordPress pluginu Modular DS aktivno se zloupotrebljava za admin pristup (CVE-2026-23550)
Kritična ranjivost u WordPress pluginu Modular DS aktivno se zloupotrebljava za admin pristup (CVE-2026-23550)