

GPT-5.3-Codex : Codex passe du « code assistant » à l’agent qui sait (presque) tout faire sur un ordinateur
Avec GPT‑5.3‑Codex, OpenAI ne se contente pas d’améliorer un modèle « meilleur en code ». L’ambition affichée est plus large : étendre Codex à l’ensemble du travail professionnel sur un ordinateur – écrire, tester, déployer, diagnostiquer, produire des livrables (docs, slides, tableurs), et piloter des tâches longues où l’agent doit raisonner, utiliser des outils, puis exécuter en boucle.
Dans l’annonce, OpenAI positionne GPT‑5.3‑Codex comme le modèle de codage agentique (agentic) le plus capable à ce jour. “Agentique”, ici, veut dire qu’il ne s’arrête pas à générer du code : il planifie, agit via des outils (terminal, éditeur, navigateur, etc.), observe les résultats et itère jusqu’à la fin d’un objectif.
Le modèle combine les progrès de GPT‑5.2‑Codex en performance de programmation avec les capacités de raisonnement et de connaissances professionnelles de GPT‑5.2 – le tout en un seul modèle, annoncé comme 25% plus rapide. Conséquence directe : il devient plus crédible sur des tâches longues (plusieurs heures/jours), où la latence, le coût en tokens et la continuité de contexte sont déterminants.
Un point marquant : un modèle qui a aidé à se construire lui‑même
OpenAI insiste sur un détail assez rare dans les annonces produit : GPT‑5.3‑Codex est présenté comme leur premier modèle ayant été instrumental dans sa propre création. L’équipe Codex aurait utilisé des versions précoces pour : déboguer son propre entraînement, gérer son déploiement, et diagnostiquer les résultats de tests/évaluations. Leur retour est explicite : Codex aurait sensiblement accéléré son propre cycle de développement.
Capacités « frontier » : ce que disent les benchmarks (et pourquoi ça compte)
Pour objectiver le saut de capacités, OpenAI s’appuie sur quatre évaluations récurrentes dans leur communication : SWE‑Bench Pro, Terminal‑Bench, OSWorld et GDPval. L’idée : couvrir à la fois le génie logiciel en conditions réalistes, les compétences terminal, l’usage d’un ordinateur via interface visuelle, et le “knowledge work” professionnel.
Programmation : SWE‑Bench Pro et Terminal‑Bench 2.0
Côté engineering pur, GPT‑5.3‑Codex est annoncé state-of-the-art sur SWE‑Bench Pro, une évaluation orientée « vrais tickets de génie logiciel ». OpenAI rappelle au passage un point important : là où SWE‑bench Verified se limite à Python, SWE‑Bench Pro s’étend à quatre langages, vise une meilleure résistance à la contamination, et se veut plus difficile, plus divers et plus “industry‑relevant”.
Sur Terminal‑Bench 2.0, qui mesure les compétences en ligne de commande nécessaires à un agent type Codex, le modèle dépasse largement l’état de l’art précédent. Détail intéressant pour les personnes qui utilisent Codex au quotidien : GPT‑5.3‑Codex atteindrait ces résultats avec moins de tokens que les modèles précédents, ce qui, en pratique, laisse plus de marge pour « construire » (et itérer) avant d’atteindre des limites.
Développement web : itérations autonomes sur des jeux complets
OpenAI met aussi l’accent sur un mélange de capacités qui, en front, fait une grosse différence : compétences de code “frontier” + amélioration esthétique + compaction (autrement dit : mieux condenser/structurer le résultat). Résultat revendiqué : un modèle capable de produire des applications et des jeux complexes depuis zéro, sur plusieurs jours, en itérant de façon autonome.
Pour tester ces capacités agentiques longues en web, l’équipe a demandé à GPT‑5.3‑Codex de construire deux jeux : (1) une version 2 du jeu de course déjà montré lors du lancement de l’app Codex, et (2) un jeu de plongée. L’expérimentation est structurée autour de la compétence “develop web game” et de relances génériques pré‑sélectionnées (du type « corrige le bug » ou « améliore le jeu »). Le modèle aurait ainsi itéré sur des millions de tokens.
- Jeu de course : plusieurs pilotes, huit cartes, et même des items utilisables avec la barre espace. Démo jouable : https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Jeu de plongée : exploration de récifs, collecte pour compléter un “fish codex”, gestion de l’oxygène, de la pression et des dangers. Démo jouable : https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Au-delà des démos « waouh », OpenAI affirme que GPT‑5.3‑Codex comprend mieux l’intention sur des demandes plus quotidiennes (ex. construire un site simple) que GPT‑5.2‑Codex. Quand le prompt est simple ou un peu flou, le modèle tendrait à sortir par défaut une base plus fonctionnelle, avec des choix raisonnables, offrant un “canvas” plus solide pour la suite.
Exemple concret donné : sur deux landing pages générées à partir du même brief, GPT‑5.3‑Codex a, sans demande explicite, présenté le plan annuel comme un prix mensuel remisé, plutôt que de se contenter de multiplier le total annuel – rendant la réduction plus lisible. Il a aussi généré un carrousel de témoignages avec trois citations distinctes et une transition automatique, là où une version moins aboutie donne souvent une section plus “placeholder”. Le ressenti global annoncé : une page plus complète et plus proche d’un rendu “production-ready” par défaut.
Au-delà du code : cycle de vie logiciel et « knowledge work »
OpenAI insiste sur une réalité du métier : un·e dev, un·e designer, un·e PM ou un·e data scientist ne fait pas que produire du code. GPT‑5.3‑Codex est présenté comme construit pour accompagner tout le cycle logiciel : débogage, déploiement, monitoring, rédaction de PRD, édition de contenu, user research, tests, métriques, etc. Et, plus largement, pour produire des livrables comme des slides ou analyser des données dans des tableurs.
Sur ce volet, OpenAI relie GPT‑5.3‑Codex à GDPval (évaluation publiée en 2025), qui mesure la performance sur des tâches de travail de connaissance bien spécifiées à travers 44 métiers (présentations, spreadsheets, et autres livrables). L’annonce indique que GPT‑5.3‑Codex y montre une performance forte, au niveau de GPT‑5.2.
Exemple de tâche GDPval : présentation de conseil financier
OpenAI partage un exemple de contexte/prompt : un conseiller financier en gestion de patrimoine doit produire une présentation PowerPoint de 10 slides pour expliquer pourquoi, en tant que fiduciaire, il faut déconseiller le fait de convertir des certificats de dépôt (CD) en rentes variables (variable annuities). La présentation doit notamment comparer caractéristiques, risques/rendements, pénalités, tolérance au risque et adéquation (suitability), en s’appuyant sur des sources FINRA et NAIC, avec deux URLs fournies (document NAIC et article FINRA).
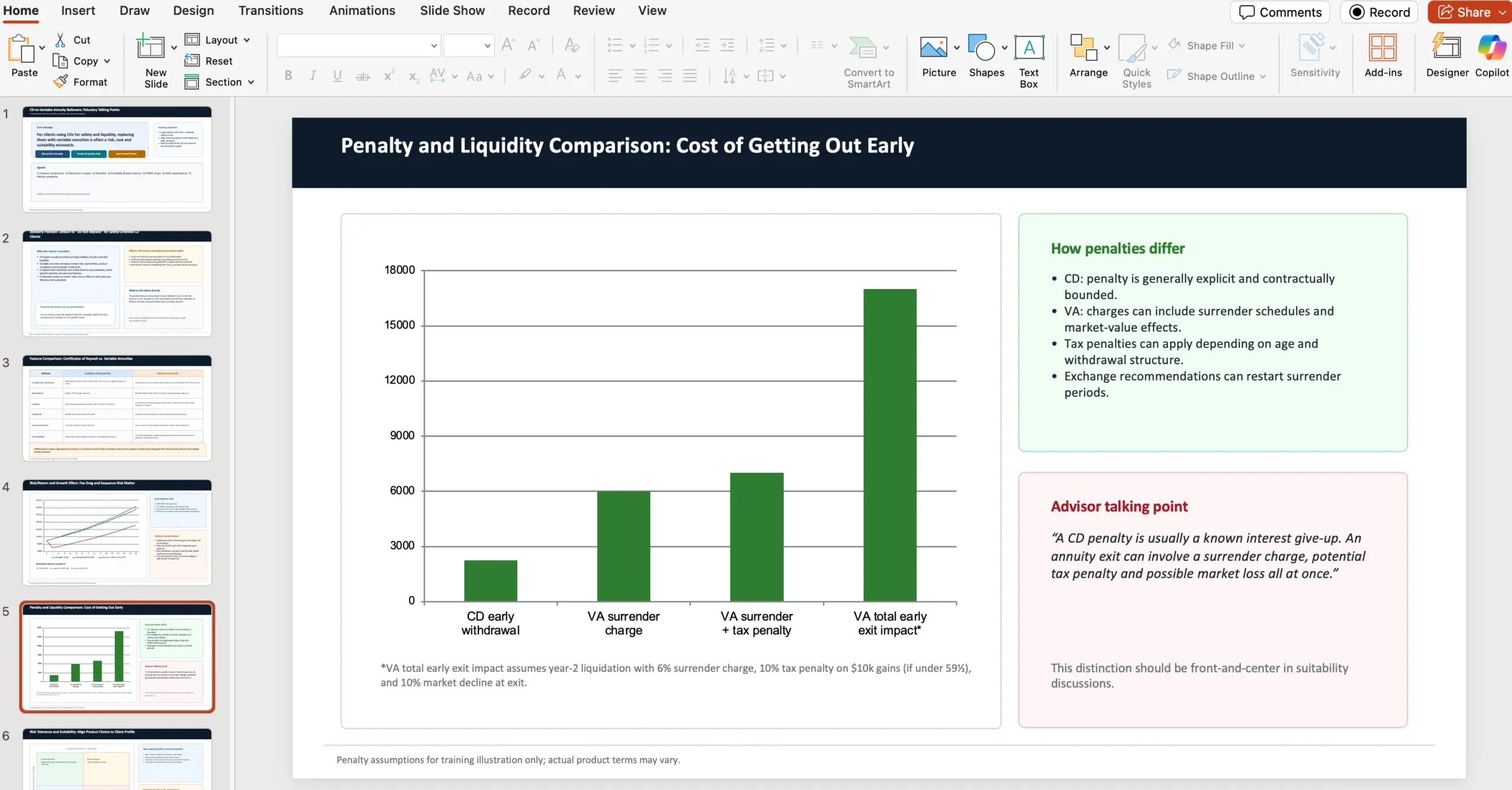
Point méthodologique précisé : chaque tâche GDPval est conçue par un professionnel expérimenté et reflète du travail réel associé au métier.
Enfin, OSWorld est présenté comme un benchmark d’usage agentique d’un ordinateur dans un environnement desktop visuel, avec des tâches de productivité à accomplir. GPT‑5.3‑Codex y afficherait des capacités d’utilisation d’ordinateur nettement supérieures aux précédents modèles GPT. OpenAI rappelle un repère : sur OSWorld‑Verified, les humains atteignent environ 72%.
Codex comme collaborateur interactif : piloter pendant que l’agent travaille
Quand les agents deviennent plus puissants, le problème se déplace : ce n’est plus seulement “ce qu’ils savent faire”, mais “comment on les supervise, on les dirige et on collabore” – surtout quand tu en as plusieurs en parallèle. L’app Codex est présentée comme la réponse UI/UX à ce besoin, et GPT‑5.3‑Codex renforce l’aspect interactif.
Concrètement, OpenAI annonce que Codex fournit des mises à jour fréquentes sur les décisions clés et l’avancement. L’objectif : ne pas attendre un résultat final opaque. Tu peux interagir en temps réel, poser des questions, débattre des approches, corriger la trajectoire. Le modèle “parle” de ce qu’il fait, intègre le feedback, et garde l’utilisateur dans la boucle du début à la fin.
Réglage à connaître
Dans l’app Codex, le pilotage pendant l’exécution se configure via : Settings > General > Follow-up behavior.
Comment OpenAI a utilisé Codex pour entraîner et déployer GPT‑5.3‑Codex
L’annonce est assez riche sur les usages internes. OpenAI explique que les améliorations rapides de Codex reposent sur des chantiers de recherche étalés sur des mois/années, mais que ces projets sont eux-mêmes accélérés par Codex. Plusieurs chercheurs/ingénieurs décriraient leur travail comme “fondamentalement différent” de ce qu’il était deux mois plus tôt.
Même des versions précoces de GPT‑5.3‑Codex auraient été suffisamment bonnes pour être utilisées afin d’améliorer l’entraînement et soutenir le déploiement des versions suivantes.
Côté recherche : monitoring, debug et compréhension fine du comportement
Leur équipe de recherche a utilisé Codex pour monitorer et déboguer le run d’entraînement. Mais l’usage dépasse les problèmes d’infra : Codex a aidé à repérer des patterns durant l’entraînement, fourni des analyses profondes de la qualité d’interaction, proposé des correctifs, et construit des applications internes permettant aux chercheurs de comprendre précisément en quoi le comportement différait des modèles précédents.
Côté engineering : harness, bugs de rendu de contexte, cache et scalabilité GPU
Côté engineering, Codex a été utilisé pour optimiser et adapter le harness (l’outillage/pipeline d’évaluation et d’exécution) pour GPT‑5.3‑Codex. Lors de l’apparition d’edge cases impactant les utilisateurs, des membres de l’équipe ont utilisé Codex pour identifier des bugs de rendu de contexte et remonter aux causes racines de faibles taux de cache hit.
Pendant le lancement, GPT‑5.3‑Codex continuerait d’aider en ajustant dynamiquement l’échelle de clusters GPU afin d’absorber des pics de trafic tout en maintenant la latence stable.
Alpha testing : mesurer la productivité “par tour” via des classifieurs regex
Un exemple assez parlant : pendant l’alpha, un chercheur voulait estimer combien de travail additionnel GPT‑5.3‑Codex accomplissait par tour (turn) et l’impact sur la productivité. GPT‑5.3‑Codex a proposé plusieurs classifieurs simples basés sur des regex pour estimer : la fréquence des demandes de clarification, les retours positifs/négatifs utilisateurs, et la progression sur la tâche.
Ces classifieurs ont ensuite été exécutés à grande échelle sur les logs de sessions, et un rapport a été produit. Conclusion rapportée : les personnes qui construisent avec Codex étaient plus satisfaites car l’agent comprenait mieux l’intention et avançait davantage par tour, avec moins de questions de clarification.
Analyse de données : nouveaux pipelines et visualisations plus riches
OpenAI note aussi que, parce que GPT‑5.3‑Codex diffère fortement de ses prédécesseurs, les données de l’alpha présentaient des résultats étranges et contre‑intuitifs. Un data scientist a travaillé avec GPT‑5.3‑Codex pour bâtir de nouveaux pipelines data et visualiser les résultats plus finement que les outils de dashboarding standards. L’analyse a été co‑réalisée avec Codex, qui a résumé des insights clés sur des milliers de points en moins de trois minutes.
Pris ensemble, ces exemples servent un message clair : au-delà d’un “agent qui code”, Codex devient un multiplicateur de capacité pour des équipes R&D, produit et infra.
Cybersécurité : un modèle « High capability » et une approche précautionneuse
Sur les derniers mois, OpenAI dit observer des gains significatifs sur les tâches de cybersécurité, utiles autant aux développeurs qu’aux professionnels de la sécurité. En parallèle, l’entreprise annonce avoir préparé des garde‑fous renforcés pour soutenir l’usage défensif et la résilience de l’écosystème (référence : “strengthened cyber safeguards”).
GPT‑5.3‑Codex est présenté comme le premier modèle classé “High capability” pour les tâches liées à la cybersécurité dans leur Preparedness Framework, et comme le premier entraîné directement à identifier des vulnérabilités logicielles. OpenAI précise ne pas avoir de preuve définitive qu’il puisse automatiser des attaques de bout en bout, mais adopte une posture de précaution en déployant leur pile de sécurité cyber la plus complète à date.
- Safety training (entraînement orienté sécurité)
- Automated monitoring (monitoring automatisé)
- Trusted access pour les capacités avancées (accès de confiance)
- Enforcement pipelines incluant de la threat intelligence (chaînes d’application/contrôle avec renseignement sur les menaces)
Comme la cybersécurité est par nature dual‑use, OpenAI décrit une approche itérative et basée sur l’évidence : accélérer la capacité des défenseurs à trouver/corriger des failles, tout en ralentissant les usages malveillants.
Dans ce cadre, OpenAI lance Trusted Access for Cyber, un programme pilote visant à accélérer la recherche en cyberdéfense.
Côté “écosystème”, OpenAI annonce aussi : (1) l’extension de la private beta de Aardvark, leur agent de recherche en sécurité, présenté comme la première offre d’une suite de produits/outils Codex Security ; (2) des partenariats avec des mainteneurs open source pour fournir des scans gratuits de codebases largement utilisées (exemple cité : Next.js), dans un contexte où un chercheur sécurité a utilisé Codex pour trouver des vulnérabilités divulguées publiquement.
Enfin, au-delà du programme de subventions cyber de 1M$ lancé en 2023, OpenAI s’engage à 10M$ de crédits API pour accélérer la cyberdéfense avec leurs modèles les plus capables, en particulier pour l’open source et les systèmes d’infrastructure critique. Les organisations menant de la recherche sécurité de bonne foi peuvent candidater pour obtenir des crédits et du support via le Cybersecurity Grant Program.
Disponibilité, vitesse et infra : où utiliser GPT‑5.3‑Codex
GPT‑5.3‑Codex est disponible avec les abonnements payants ChatGPT, partout où Codex est utilisable : app, CLI, extension IDE et web. OpenAI indique travailler à activer l’accès API “soon”, avec une approche prudente (sous-entendu : activation progressive et sécurisée).
OpenAI annonce aussi une amélioration de performance côté produit : pour les utilisateurs Codex, GPT‑5.3‑Codex est exécuté 25% plus rapidement, grâce à des améliorations d’infrastructure et de la stack d’inférence – ce qui vise à accélérer autant l’interaction que la production de résultats.
Au niveau matériel, GPT‑5.3‑Codex a été co‑designé pour, entraîné avec et servi sur des systèmes NVIDIA GB200 NVL72. OpenAI remercie NVIDIA pour le partenariat.
Ce qui change (vraiment) : du “coding agent” au collaborateur généraliste sur ordinateur
La conclusion d’OpenAI est cohérente avec l’ensemble de l’annonce : GPT‑5.3‑Codex pousse Codex au-delà de l’écriture de code pour utiliser le code comme un outil permettant d’opérer un ordinateur et de compléter du travail end‑to‑end. En repoussant les limites d’un agent de code, ils disent débloquer une classe plus large de tâches de knowledge work : construire et déployer du logiciel, mais aussi rechercher, analyser et exécuter des tâches complexes.
Ce qui a commencé comme une course au “meilleur agent de code” devient, dans leur narration, la base d’un collaborateur plus généraliste sur ordinateur – ce qui élargit à la fois le nombre de personnes capables de construire et l’éventail des choses possibles avec Codex.
Appendice : chiffres des évaluations partagées par OpenAI
Toutes les évaluations mentionnées dans l’annonce ont été exécutées sur GPT‑5.3‑Codex avec un effort de raisonnement xhigh (précision donnée en note). Voici le tableau récapitulatif fourni :
- SWE‑Bench Pro (Public) : GPT‑5.3‑Codex (xhigh) 56.8% ; GPT‑5.2‑Codex (xhigh) 56.4% ; GPT‑5.2 (xhigh) 55.6%
- Terminal‑Bench 2.0 : GPT‑5.3‑Codex 77.3% ; GPT‑5.2‑Codex 64.0% ; GPT‑5.2 62.2%
- OSWorld‑Verified : GPT‑5.3‑Codex 64.7% ; GPT‑5.2‑Codex 38.2% ; GPT‑5.2 37.9%
- GDPval (wins or ties) : GPT‑5.3‑Codex 70.9% ; GPT‑5.2 (xhigh) 70.9% (high)
- Cybersecurity Capture The Flag Challenges : GPT‑5.3‑Codex 77.6% ; GPT‑5.2‑Codex 67.4% ; GPT‑5.2 67.7%
- SWE‑Lancer IC Diamond : GPT‑5.3‑Codex 81.4% ; GPT‑5.2‑Codex 76.0% ; GPT‑5.2 74.6%



Antoine Martin
Ingénieur DevSecOps, spécialiste des pratiques de développement sécurisé et des pipelines CI/CD. Docker et GitHub Actions font partie de mon quotidien.
Tous les articlesPlus d’articles de Antoine Martin
 Ports SMTP en 2026 : choisir 587, 465… et éviter les pièges qui ruinent la délivrabilité
Ports SMTP en 2026 : choisir 587, 465… et éviter les pièges qui ruinent la délivrabilité
 Checklist RGPD complète pour propriétaires de sites : données, consentement, WordPress et gestion des incidents
Checklist RGPD complète pour propriétaires de sites : données, consentement, WordPress et gestion des incidents
 Faille critique dans Modular DS : une escalade de privilèges WordPress exploitée pour obtenir un accès admin
Faille critique dans Modular DS : une escalade de privilèges WordPress exploitée pour obtenir un accès admin