
GPT-5.3-Codex: Codex laajenee koodista koko tietokoneen ammattilaisagentiksi
OpenAI julkaisi 5.2-sukupolven Codex-parannusten perään uuden mallin nimeltä GPT-5.3-Codex. Olennaisin muutos ei ole pelkkä parempi koodin laatu, vaan se, että Codexia asemoidaan nyt agentiksi, joka voi tehdä käytännössä “koko työpäivän” mittaisia tehtäviä tietokoneella: tutkia, käyttää työkaluja, suorittaa monivaiheisia operaatioita ja tuottaa lopputuloksia – samalla kun sinä voit keskeyttää, kysyä, tarkentaa ja ohjata ilman että konteksti hajoaa.
Julkaisun mukaan GPT-5.3-Codex yhdistää kaksi aiempaa vahvuuslinjaa yhteen: GPT‑5.2‑Codexin frontier-tason koodauskyvykkyyden ja GPT‑5.2:n päättelyn sekä ammatillisen tietotyöosaamisen. Lisäksi malli ajetaan Codex-käyttäjille 25% nopeammin, mikä on merkittävä käytännön parannus etenkin pitkissä agenttisessioissa.
Mitä GPT-5.3-Codex käytännössä tarkoittaa: “koodia kirjoittavasta agentista” tietokoneella toimivaksi kollegaksi
Aiemmin Codexista puhuttiin ensisijaisesti koodin kirjoittajana ja koodikatselmoijana. GPT‑5.3‑Codexin kohdalla OpenAI:n viesti on selvä: Codex pyrkii tekemään lähes mitä tahansa, mitä kehittäjät ja muut ammattilaiset tekevät tietokoneella. Tämä kattaa ohjelmistokehityksen koko elinkaaren (debuggaus, deploy, monitorointi, testit, metriikat, dokumentit) mutta myös laajemman tietotyön kuten esitykset, taulukkolaskenta-analyysit ja muun “valmiin tuotoksen” rakentamisen.
Frontier agentic capabilities: mihin benchmarkit viittaavat
OpenAI nostaa esiin neljä benchmarkia, joilla se mittaa koodausta, agenttikäyttöä ja “oikean maailman” kyvykkyyttä: SWE-Bench Pro, Terminal-Bench, OSWorld ja GDPval. GPT‑5.3‑Codexin kerrotaan asettavan uuden “industry high” -tason SWE‑Bench Prossa ja Terminal‑Benchissä, ja lisäksi sillä on vahvat tulokset OSWorldissa ja GDPvalissa.
Koodaus: SWE-Bench Pro ja Terminal-Bench 2.0
SWE‑Bench Pro kuvataan tiukaksi, oikeaa ohjelmistotyötä muistuttavaksi evaluaatioksi. Julkaisussa korostetaan kahta asiaa: (1) SWE‑bench Verified testaa vain Pythonia, kun taas SWE‑Bench Pro kattaa neljä ohjelmointikieltä ja on “contamination-resistant” (eli vähemmän altis datavuodoille ja evaluaation “saastumiselle”), sekä (2) se on monipuolisempi, haastavampi ja lähempänä teollisuuden käytäntöjä.
Terminal‑Bench 2.0 puolestaan mittaa nimenomaan komentoriviosaamista, jota Codexin kaltaiselta agentilta vaaditaan. Huomionarvoinen yksityiskohta: GPT‑5.3‑Codex yltää tuloksiin vähemmillä tokeneilla kuin mikään aiempi malli, mikä käytännössä tarkoittaa tehokkaampaa “budjetin käyttöä” ja mahdollisuutta rakentaa pidemmälle ennen kuin konteksti tai kustannukset tulevat vastaan.
Web-kehitys ja pitkät agenttiajot: kahden pelin testi miljoonilla tokeneilla
Web-kehityksen kohdalla OpenAI korostaa yhdistelmää: frontier-koodaus + esteettiset parannukset + “compaction”. Tällä viitataan siihen, että malli kykenee tuottamaan näyttävää, toimivaa lopputulosta ja iteromaan sitä pitkään.
Pitkäkestoisen agenttikyvykkyyden testaamiseksi GPT‑5.3‑Codexia pyydettiin rakentamaan kaksi peliä: (1) toinen versio Codex app -julkaisun yhteydessä nähdystä ajopelistä ja (2) sukelluspeli. Testissä käytettiin develop web game -taitoa ja ennalta valittuja, geneerisiä jatkoprompteja kuten “fix the bug” ja “improve the game”. Malli iteroinnin kerrotaan tapahtuneen autonomisesti miljoonien tokenien yli.
- Ajopeli: useita kuskeja, kahdeksan karttaa ja jopa esineitä, joita käytetään välilyönnillä. Pelaa: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Sukelluspeli: tutki riuttoja, kerää ne kaikki “fish codexiin”, hallitse happea, painetta ja vaaroja. Pelaa: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Julkaisun mukaan GPT‑5.3‑Codex ymmärtää paremmin myös arjen web-toiveita (esim. “tee laskeutumissivu”) verrattuna GPT‑5.2‑Codexiin: yksinkertaisista tai osittain määrittelemättömistä prompteista syntyy useammin järkevillä oletuksilla varustettu ja toiminnallisempi sivu, joka toimii parempana lähtökankaana.
Esimerkkinä OpenAI vertaa kahta landing page -generointia. GPT‑5.3‑Codex esitti vuosihinnoittelun automaattisesti alennettuna kuukausihintana (eikä vain kertonut vuosisummaa), jolloin alennus tuntui tarkoitukselliselta. Lisäksi se rakensi automaattisesti vaihtuvan testimonial-karusellin, jossa oli kolme erillistä käyttäjälausetta yhden sijaan. Tulos oli “valmiimpi” ja lähempänä tuotantokelpoista oletuksena.
Koodin ulkopuolella: ohjelmistotyön koko elinkaari ja yleinen tietotyö
OpenAI painottaa, että ohjelmistotiimien työ on muutakin kuin koodin generointia. GPT‑5.3‑Codex on rakennettu tukemaan koko ohjelmistokehityksen elinkaarta: debuggaus, deploy, monitorointi, PRD:t (Product Requirements Document), copy-editointi, käyttäjätutkimus, testit, metriikat ja muuta vastaavaa.
Lisäksi agenttikyvykkyys ulottuu ohjelmiston ulkopuolelle: voit rakentaa esimerkiksi slide deckeja tai analysoida dataa taulukoissa. OpenAI kytkee tämän erityisesti GDPval-evaluaatioon, joka julkaistiin 2025 ja mittaa mallin suoriutumista hyvin määritellyissä tietotyötehtävissä 44 ammattialan yli. GPT‑5.3‑Codexin kerrotaan yltävän GDPvalissa GPT‑5.2:n tasolle.
Esimerkkitehtävä GDPvalista: 10 dian PowerPoint talousneuvonnasta
Julkaisussa annetaan konkreettinen esimerkki: agenttia pyydettiin toimimaan varainhoitofirmassa talousneuvojana ja laatimaan 10 dian PowerPoint-esitys keskustelupohjiksi tilanteeseen, jossa asiakkaat harkitsevat talletustodistusten (certificates of deposits) siirtämistä vaihtuvakorkoisiin annuiteetteihin (variable annuities). Tehtävässä painotettiin, että päätös ei ole prudentti ja että neuvojien tulisi fiduciary-roolissa suositella sitä vastaan.
- Vertaa certificates of deposits vs variable annuities -ominaisuuksia FINRA-lähteisiin perustuen ja tuo esiin sijoittajavarovaisuus
- Vertaa risk/return-analyysiä ja vaikutusta kasvuun
- Erittele rangaistusmaksujen (penalties) erot
- Kontrastoi riskinsietoa ja soveltuvuutta (suitability) NAIC Best Interest Regulations -lähteisiin perustuen
- Nosta esiin FINRA:n huolia/ongelmia
- Nosta esiin NAIC:n kysymyksiä/sääntelyä
- Huomio: NAIC ja FINRA ovat luoneet best interest- ja suitability-ohjeistuksia variable annuities -tuotteiden suositteluun niiden monimutkaisuuden vuoksi
- Käytettävät web-lähteet: https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf ja https://www.finra.org/investors/insights/high-yield-cds
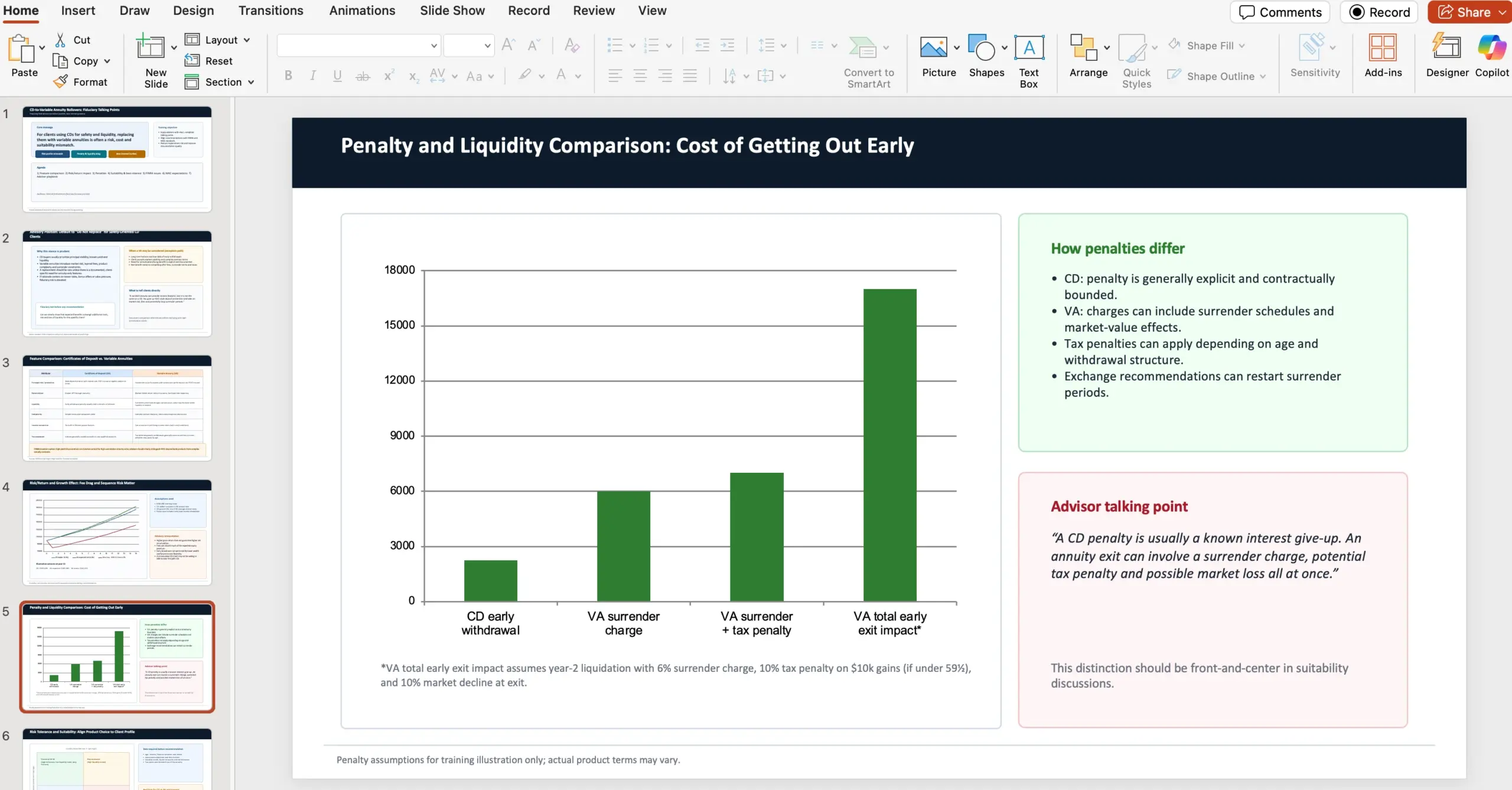
OpenAI huomauttaa myös, että GDPval-tehtävät suunnittelee kokenut ammattilainen ja ne heijastavat kunkin ammatin “aitoa” tietotyötä, eivät pelkkiä trivia-kysymyksiä.
OSWorld: visuaalinen “käytä tietokonetta” -benchmark
OSWorld kuvataan agenttiseksi computer-use-benchmarkiksi, jossa agentin pitää suorittaa tuottavuustehtäviä visuaalisessa desktop-ympäristössä. GPT‑5.3‑Codexin kerrotaan näyttävän selvästi aiempia GPT-malleja vahvempaa kykyä käyttää tietokonetta. Julkaisussa mainitaan OSWorld-Verifiedistä myös vertailukohta: ihmiset saavuttavat noin 72% tuloksen.
Kokonaisviesti näiden tulosten yli on kiinnostava: GPT‑5.3‑Codex ei ole vain parempi yksittäisissä mikrotaidoissa, vaan se näyttäisi olevan askel kohti yleisagenttia, joka pystyy päättelyyn, rakentamiseen ja suoritukseen koko teknisen työn spektrissä.
Interaktiivinen yhteistyökumppani: ohjaus kesken työn, ei vasta lopussa
Kun agentit muuttuvat kykenevämmiksi, pullonkaula siirtyy helposti siihen, miten hyvin ihminen pystyy ohjaamaan ja valvomaan useita rinnakkaisia agentteja. OpenAI väittää Codex appin madaltavan tätä kynnystä ja että GPT‑5.3‑Codex tekee käyttökokemuksesta vielä interaktiivisemman.
Käytännössä tämä tarkoittaa: Codex antaa työn edetessä useammin tilapäivityksiä tärkeistä päätöksistä ja etenemisestä. Sen sijaan, että odottaisit yhtä lopullista vastausta, voit keskustella ratkaisulinjasta, kysyä tarkennuksia ja ohjata suuntaa reaaliajassa. Mallin kerrotaan “puhuvan läpi” mitä se tekee, reagoivan palautteeseen ja pitävän sinut kartalla alusta loppuun.
Ohjauksen voi ottaa käyttöön Codex appissa asetuksesta: Settings > General > Follow-up behavior (julkaisussa kuvataan tämä nimenomaan “Enable steering while the model works”).
Mielenkiintoinen meta-juonne: Codex auttoi GPT-5.3-Codexin rakentamisessa
Ehkä koko julkaisun erikoisin kohta on väite, että GPT‑5.3‑Codex on heidän ensimmäinen mallinsa, joka oli olennaisesti mukana luomassa itseään. Codex-tiimi käytti varhaisia versioita oman koulutuksen debuggaamiseen, deploymentin hallintaan sekä testitulosten ja evaluaatioiden diagnosointiin. OpenAI kuvaa tiimin olleen yllättynyt siitä, kuinka paljon Codex nopeutti omaa kehitystään.
Tutkimustiimin esimerkit: training-runin valvonta ja vuorovaikutuksen analyysi
OpenAI kertoo, että viime kuukausien Codex-parannukset nojaavat laajoihin tutkimusprojekteihin (kuukausien tai vuosien mittaisiin), mutta että Codex samalla kiihdyttää näitä projekteja. Useat tutkijat ja insinöörit kuvaavat työnkuvan muuttuneen perustavanlaatuisesti jo kahdessa kuukaudessa.
Tutkimuspuolella Codexia käytettiin tämän julkaisun training-runin monitorointiin ja debuggaamiseen. Mutta mukana oli muutakin kuin infraongelmien ratkomista: Codex auttoi seuraamaan koulutuksen aikana näkyviä toistuvia kuvioita, analysoi vuorovaikutuksen laatua syvällisesti, ehdotti korjauksia ja rakensi “rich applications” -tyyppisiä työkaluja, joiden avulla tutkijat pystyivät tarkasti ymmärtämään, miten mallin käyttäytyminen erosi aiemmista.
Insinööritiimin esimerkit: harnessin optimointi, renderöintibugit ja GPU-klusterin skaalaus
Engineering-puolella Codex auttoi optimoimaan ja sovittamaan GPT‑5.3‑Codexin “harnessin” (käytännössä testaus-/ajo- ja integrointikehikon). Kun käyttäjiin vaikuttaneita outoja edge caseja alkoi ilmaantua, tiimi käytti Codexia kontekstin renderöintiin liittyvien bugien löytämiseen sekä matalien cache hit rate -lukemien juurisyiden selvittämiseen.
Julkaisun mukaan GPT‑5.3‑Codex auttaa myös itse launchin aikana: se pystyy dynaamisesti skaalaamaan GPU-klustereita liikennepiikkien mukaan ja pitämään latenssin vakaana.
Alphadata-analyysi: regex-luokittimet, uudet dataputket ja tiivistelmät tuhansista datapisteistä
Alphatestauksessa yksi tutkija halusi mitata, kuinka paljon “lisätyötä per vuoro” (per turn) GPT‑5.3‑Codex sai aikaan ja miten se korreloi tuottavuuden kanssa. GPT‑5.3‑Codex ehdotti useita yksinkertaisia regex-luokittimia arvioimaan esimerkiksi tarkentavien kysymysten frekvenssiä, positiivisia ja negatiivisia käyttäjäreaktioita sekä edistymistä tehtävässä. Nämä ajettiin skaalautuvasti kaikista sessiolokeista, ja lopuksi malli tuotti raportin päätelmineen.
Havainto: ihmiset, jotka rakensivat Codexin kanssa, olivat tyytyväisempiä, kun agentti ymmärsi intentiota paremmin ja eteni enemmän per vuoro, esittäen vähemmän tarkentavia kysymyksiä.
Koska GPT‑5.3‑Codex poikkeaa edeltäjistä merkittävästi, alpha-aineistossa näkyi “epätavallisia ja intuitiivisesti yllättäviä” tuloksia. Yksi tiimin data scientist rakensi GPT‑5.3‑Codexin kanssa uusia dataputkia ja visualisointeja, jotka olivat rikkaampia kuin standardit dashboard-työkalut. Tuloksia myös yhteisanalysoitiin Codexin kanssa: malli tiivisti keskeiset löydökset tuhansista datapisteistä alle kolmessa minuutissa.
Kyberturvan “cyber frontier”: High capability -luokitus ja uudet suojaukset
OpenAI kertoo nähneensä viime kuukausina merkittäviä parannuksia kyberturvatehtävissä, joista hyötyvät sekä kehittäjät että tietoturva-ammattilaiset. Samalla se kertoo valmistelleensa vahvistettuja suojamekanismeja (viitaten julkaisuun “strengthening cyber safeguards”) tukemaan puolustavaa käyttöä ja ekosysteemin resilienssiä.
GPT‑5.3‑Codex on heidän ensimmäinen mallinsa, jonka he luokittelevat “High capability” -tasolle kyberturvaan liittyvissä tehtävissä heidän Preparedness Framework -viitekehyksensä alla, ja ensimmäinen, jonka kerrotaan olevan suoraan koulutettu tunnistamaan ohjelmistojen haavoittuvuuksia.
OpenAI painottaa, ettei heillä ole varmaa näyttöä siitä, että malli pystyisi automatisoimaan kyberhyökkäyksiä end-to-end, mutta he ottavat varovaisen lähestymistavan ja ottavat käyttöön “kaikkein kattavimman kyberturvan safety stackin tähän mennessä”. Mainitut mitigoinnit sisältävät:
- safety training
- automated monitoring
- trusted access for advanced capabilities
- enforcement pipelines, mukaan lukien threat intelligence
Koska kyberturva on luonteeltaan dual-use, OpenAI kuvaa lähestymistapaa evidence-based ja iteratiiviseksi: tavoitteena on nopeuttaa puolustajien kykyä löytää ja korjata haavoittuvuuksia samalla kun väärinkäyttöä hidastetaan.
Osana tätä he käynnistävät Trusted Access for Cyber -pilotoinnin, jonka tarkoitus on kiihdyttää kyberpuolustuksen tutkimusta.
Ekosysteemisuojaukset: Aardvark, avoimen lähdekoodin skannaus ja Next.js-esimerkki
OpenAI kertoo myös investoivansa ekosysteemitason suojauksiin. Konkreettisesti: he laajentavat Aardvark-nimisen security research agentin private beta -vaihetta. Se on heidän mukaansa ensimmäinen tarjoama Codex Security -tuote- ja työkalusuiteen sisällä.
Lisäksi he kertovat tekevänsä yhteistyötä open source -ylläpitäjien kanssa tarjotakseen ilmaisia codebase-skannauksia laajasti käytetyille projekteille kuten Next.js. Julkaisussa viitataan tapaukseen, jossa tietoturvatutkija käytti Codexia haavoittuvuuksien löytämiseen, jotka Vercel julkaisi viime viikolla.
Vercelin julkaisuviite: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
Rahoitus: $10M API credit -sitoumus ja Cybersecurity Grant Program
OpenAI kertoo rakentavansa aiemman, vuonna 2023 käynnistetyn $1M Cybersecurity Grant Program -ohjelman päälle ja sitoutuvansa nyt $10M edestä API-krediittejä kyberpuolustuksen nopeuttamiseen heidän kyvykkäimmillä malleillaan. Painopisteenä mainitaan erityisesti open source -ohjelmistot ja kriittisen infrastruktuurin järjestelmät.
Hyvässä uskossa tehtävää tietoturvatutkimusta tekevät organisaatiot voivat hakea API-krediittejä ja tukea OpenAI:n Cybersecurity Grant Program -ohjelman kautta: https://openai.com/index/openai-cybersecurity-grant-program/
Saatavuus ja käytännön yksityiskohdat
GPT‑5.3‑Codex on saatavilla maksullisilla ChatGPT-paketeilla kaikkialla, missä Codexia voi käyttää: appissa, CLI:ssä, IDE-laajennuksessa ja webissä. API-saatavuuden osalta OpenAI sanoo työskentelevänsä sen turvallisen käyttöönoton parissa ja tavoitteena on mahdollistaa API access “soon” (ei tarkkaa aikataulua).
Samassa päivityksessä OpenAI kertoo ajavansa GPT‑5.3‑Codexia Codex-käyttäjille 25% nopeammin infrastruktuuri- ja inference stack -parannusten ansiosta, mikä näkyy sekä nopeampina vuorovaikutuksina että nopeampina lopputuloksina.
Laitetasolla GPT‑5.3‑Codexin kerrotaan olleen co-designed for, trained with ja served on NVIDIA GB200 NVL72 -järjestelmillä, ja OpenAI kiittää NVIDIAa kumppanuudesta.
Mitä seuraavaksi: koodi työkaluna, ei lopputuotteena
OpenAI:n “What’s next” -osio tiivistää suunnan: Codex siirtyy koodin kirjoittamisesta siihen, että koodi on väline, jolla agentti operoi tietokonetta ja vie työn maaliin end-to-end. Samalla kun coding agent -frontieria viedään eteenpäin, avautuu laajempi luokka tietotyötä: rakentaminen, deploy, tutkiminen, analysointi ja monimutkaisten tehtävien toimeenpano.
Se, mikä alkoi tavoitteena olla paras koodausagentti, esitetään nyt perustana yleisemmälle “collaborator on the computer” -mallille: laajenee sekä se, kuka pystyy rakentamaan, että se, mitä Codexilla on mahdollista tehdä.
Appendix: julkaistut numerot (xhigh reasoning effort)
OpenAI julkaisi liitteessä taulukon keskeisistä evaluaatioista. Mukana ovat GPT‑5.3‑Codex (xhigh), GPT‑5.2‑Codex (xhigh) ja GPT‑5.2 (xhigh).
- SWE-Bench Pro (Public): GPT-5.3-Codex 56.8%, GPT-5.2-Codex 56.4%, GPT-5.2 55.6%
- Terminal-Bench 2.0: GPT-5.3-Codex 77.3%, GPT-5.2-Codex 64.0%, GPT-5.2 62.2%
- OSWorld-Verified: GPT-5.3-Codex 64.7%, GPT-5.2-Codex 38.2%, GPT-5.2 37.9%
- GDPval (wins or ties): GPT-5.3-Codex 70.9%, GPT-5.2-Codex – , GPT-5.2 70.9% (high)
- Cybersecurity Capture The Flag Challenges: GPT-5.3-Codex 77.6%, GPT-5.2-Codex 67.4%, GPT-5.2 67.7%
- SWE-Lancer IC Diamond: GPT-5.3-Codex 81.4%, GPT-5.2-Codex 76.0%, GPT-5.2 74.6%
Footnote: OpenAI mainitsee, että kaikki blogissa raportoidut evaluaatiot ajettiin GPT‑5.3‑Codexilla xhigh reasoning effort -asetuksella.



Codex app: ladattava asiakasohjelma
Jos haluat kokeilla Codexia natiivissa sovelluksessa, OpenAI linkittää suoraan Codex appin asennuspakettiin (macOS): https://persistent.oaistatic.com/codex-app-prod/Codex.dmg
Viitteet / Lähteet
Hannah Turing
WordPress-kehittäjä ja tekninen kirjoittaja HelloWP:llä. Autan kehittäjiä rakentamaan parempia verkkosivustoja moderneilla työkaluilla kuten Laravel, Tailwind CSS ja WordPress-ekosysteemi. Intohimona puhdas koodi ja kehittäjäkokemus.
Kaikki julkaisutLisää käyttäjältä Hannah Turing
 Joost de Valk vetäytyy FAIR-hankkeesta – mitä se kertoo WordPressin riippuvuuksista ja ohjelmistoketjun turvallisuudesta
Joost de Valk vetäytyy FAIR-hankkeesta – mitä se kertoo WordPressin riippuvuuksista ja ohjelmistoketjun turvallisuudesta
 WPvivid Backup & Migration -lisäosasta löytyi kriittinen tiedostonlataushaavoittuvuus (CVE-2026-1357): näin tarkistat riskin ja paikkaat oikein
WPvivid Backup & Migration -lisäosasta löytyi kriittinen tiedostonlataushaavoittuvuus (CVE-2026-1357): näin tarkistat riskin ja paikkaat oikein
 WordPress Studio 1.7.0 toi Studio CLI:n: paikalliset sivustot, previewt ja WP-CLI samasta komentorivistä
WordPress Studio 1.7.0 toi Studio CLI:n: paikalliset sivustot, previewt ja WP-CLI samasta komentorivistä