

GPT-5.3-Codex: el salto de Codex de “agente de código” a colaborador general en el ordenador
OpenAI ha presentado GPT‑5.3‑Codex, un nuevo modelo que amplía Codex a prácticamente todo el espectro del trabajo profesional “en un ordenador”. La idea ya no es solo generar o revisar código: es investigar, usar herramientas, ejecutar tareas largas, y hacerlo de forma interactiva, manteniendo el contexto mientras tú lo diriges como si fuera un compañero de equipo.
Según el anuncio, GPT‑5.3‑Codex combina lo mejor de dos líneas: mejora el rendimiento de programación “frontier” de GPT‑5.2‑Codex y a la vez incorpora razonamiento y conocimientos profesionales al nivel de GPT‑5.2, todo en un único modelo. Además, se ejecuta un 25% más rápido, lo que en la práctica reduce esperas y hace más viable delegar tareas que se alargan durante horas o días.
Un detalle curioso (y relevante si te interesa cómo evolucionan estas herramientas): OpenAI indica que GPT‑5.3‑Codex es el primer modelo que fue instrumental en su propia creación. El equipo de Codex usó versiones tempranas para depurar el entrenamiento, gestionar el despliegue y diagnosticar resultados de pruebas y evaluaciones, acelerando el desarrollo del propio modelo.
Capacidades agentic “frontier”: dónde mejora y cómo lo miden
Para situarlo, OpenAI apoya el lanzamiento con resultados en cuatro benchmarks orientados a medir habilidades de programación, agencia (capacidad de actuar con herramientas) y desempeño “del mundo real”: SWE‑Bench Pro, Terminal‑Bench, OSWorld y GDPval. La conclusión general del anuncio es que el modelo marca un cambio de escala hacia un agente más generalista, capaz de razonar, construir y ejecutar tareas técnicas de principio a fin.
Programación: SWE‑Bench Pro y Terminal‑Bench 2.0
En programación pura, GPT‑5.3‑Codex logra estado del arte en SWE‑Bench Pro, una evaluación centrada en ingeniería de software real. OpenAI remarca varios matices importantes:
- Mientras SWE‑bench Verified solo prueba Python, SWE‑Bench Pro abarca cuatro lenguajes.
- SWE‑Bench Pro está diseñado para ser más resistente a contaminación (contamination‑resistant).
- Se plantea como un benchmark más desafiante, diverso y relevante para industria.
Además, supera ampliamente el rendimiento previo en Terminal‑Bench 2.0, que mide algo muy “del día a día” para un agente como Codex: competencias en terminal (comandos, navegación, ejecución, diagnóstico). Un punto técnico que tiene impacto práctico: OpenAI destaca que GPT‑5.3‑Codex consigue estos resultados usando menos tokens que modelos anteriores, lo que en productos con límites o costes por tokens suele traducirse en más margen para construir antes de topar con techos.
Desarrollo web: iteración autónoma durante “días” y millones de tokens
Donde el anuncio se pone especialmente tangible es en desarrollo web. OpenAI habla de una combinación de capacidad de código frontier, mejoras de estética y compaction (compactación) que permite producir trabajo visualmente más sólido y funcional, incluso en proyectos complejos como juegos y apps construidos desde cero a lo largo de varios días.
Para probar capacidades de “web dev” y agencia sostenida (long‑running agentic capabilities), pidieron a GPT‑5.3‑Codex que creara dos juegos:
- Una versión 2 del juego de carreras del lanzamiento de la app de Codex.
- Un juego de buceo.
La prueba tiene un giro interesante: en lugar de guiarlo con prompts hiperconcretos, usaron una habilidad (skill) de “develop web game” y prompts genéricos preseleccionados tipo “fix the bug” o “improve the game”. Con ese esquema, GPT‑5.3‑Codex fue iterando de forma autónoma durante millones de tokens.
Los resultados están publicados como demos jugables:
- Juego de carreras con distintos corredores, ocho mapas e incluso objetos que se usan con la barra espaciadora: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Juego de buceo donde exploras arrecifes, coleccionas elementos para completar tu “fish codex” y gestionas oxígeno, presión y peligros: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
También se comenta una mejora que, para quienes hacemos front o montamos webs pequeñas/medianas, es clave: GPT‑5.3‑Codex entiende mejor la intención cuando le pides páginas “de todos los días”, y ante prompts simples o poco especificados tiende a proponer más funcionalidad y mejores valores por defecto (sensible defaults). Eso se traduce en un lienzo inicial más completo.
En el ejemplo comparativo de una landing page, OpenAI menciona dos decisiones por defecto que marcan diferencia en sensación de “producción”:
- Al mostrar un plan anual, GPT‑5.3‑Codex lo presentó como precio mensual con descuento, haciendo el descuento más claro e intencional, en vez de multiplicar el total anual.
- Generó un carrusel de testimonios que transiciona automáticamente y con tres citas distintas, en vez de un único testimonio, haciendo la página más redonda por defecto.
Más allá del código: soporte para todo el ciclo de vida del software (y trabajo de conocimiento)
OpenAI insiste en un punto: el día a día de perfiles como ingeniería, diseño, PM o data no es solo escribir código. GPT‑5.3‑Codex está planteado para apoyar trabajo a lo largo de todo el ciclo:
- Debugging
- Deploying
- Monitoring
- Redacción de PRDs
- Edición de copy
- User research
- Tests
- Métricas y análisis
- Y más allá del software: por ejemplo, crear presentaciones o analizar datos en hojas de cálculo
Para medir ese “trabajo profesional” más general, mencionan GDPval, una evaluación publicada por OpenAI en 2025 que mide desempeño en tareas de trabajo de conocimiento bien especificadas a lo largo de 44 ocupaciones (presentaciones, spreadsheets y otros entregables). Con habilidades personalizadas similares a las usadas en resultados anteriores de GDPval, GPT‑5.3‑Codex muestra un rendimiento fuerte y igualaría a GPT‑5.2 en esa evaluación, según el anuncio.
Como muestra, incluyen ejemplos de entregables generados por el agente, entre ellos: Financial advice slides, Retail training doc, NPV analysis spreadsheet y Fashion presentation PDF. Uno de los prompts de ejemplo describe un encargo realista: preparar una presentación de 10 diapositivas para asesores financieros, comparando CDs y variable annuities, y citando fuentes concretas de FINRA y NAIC.
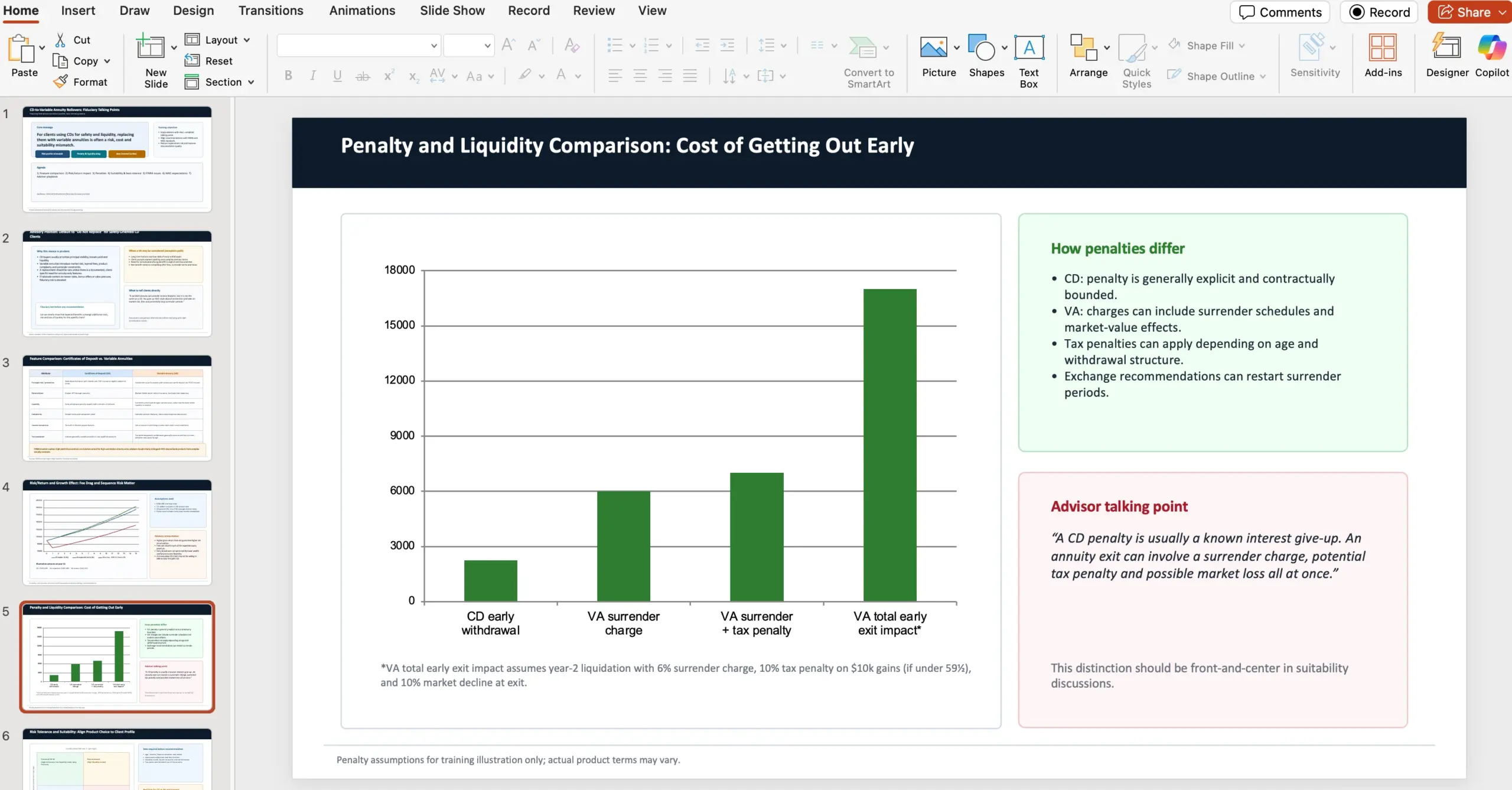
En paralelo, aparece OSWorld, un benchmark agentic de “uso de ordenador” donde el agente debe completar tareas de productividad en un entorno de escritorio visual, usando visión. OpenAI afirma que GPT‑5.3‑Codex demuestra capacidades de uso de ordenador mucho más fuertes que modelos GPT anteriores; además, se menciona que en OSWorld‑Verified los humanos puntúan ~72%.
Codex como colaborador interactivo: dirigir al agente mientras trabaja
A medida que los agentes se vuelven más capaces, el cuello de botella pasa a ser la interacción humana: cómo dirigir, supervisar y coordinar agentes en paralelo sin perder control. En ese contexto, la app de Codex se posiciona como la capa de orquestación, y con GPT‑5.3‑Codex el modo de trabajo se vuelve más interactivo.
La promesa aquí no es “esperar un resultado final”, sino conversar en tiempo real: el modelo da actualizaciones frecuentes de decisiones y progreso, puedes hacer preguntas, discutir enfoques y corregir el rumbo. Según el anuncio, GPT‑5.3‑Codex va explicando qué está haciendo, responde al feedback y te mantiene al tanto de principio a fin.
Ajuste en la app
Para habilitar el “steering” mientras el modelo trabaja, ve a Settings > General > Follow-up behavior en la app de Codex.
Cómo usaron Codex para entrenar y desplegar GPT‑5.3‑Codex (automejora en la práctica)
OpenAI atribuye las mejoras rápidas de Codex a proyectos de investigación de meses (o años) dentro de la compañía, y añade un matiz: esos proyectos se están acelerando con Codex, hasta el punto de que muchas personas describen su trabajo actual como “fundamentalmente distinto” al de hace dos meses.
Incluso las versiones tempranas de GPT‑5.3‑Codex ya permitían al equipo usarlas para mejorar el propio entrenamiento y soportar el despliegue de versiones posteriores. En el anuncio se enumeran ejemplos concretos, separados por áreas:
En investigación (monitorización y depuración del entrenamiento)
- Monitorizar y depurar el entrenamiento (training run) de esta release.
- Acelerar investigación más allá de arreglar infraestructura: detectar patrones a lo largo del entrenamiento.
- Hacer análisis profundo de la calidad de interacción (interaction quality).
- Proponer correcciones, y construir aplicaciones ricas para que investigadores humanos entiendan con precisión cómo cambiaba el comportamiento frente a modelos previos.
En ingeniería (harness, edge cases, caché y escalado de GPU)
- Optimizar y adaptar el harness (banco/arnés de evaluación y ejecución) para GPT‑5.3‑Codex.
- Investigar edge cases extraños que afectaban a usuarios: identificar bugs de renderizado de contexto y encontrar la causa raíz de bajas tasas de acierto de caché (low cache hit rates).
- Durante el lanzamiento, ayudar a escalar dinámicamente clusters de GPU para ajustarse a picos de tráfico y mantener la latencia estable.
En análisis durante alpha (clasificadores con regex y lectura de logs)
Durante pruebas alpha, un investigador quiso medir cuánta carga de trabajo adicional se completaba “por turno” y cómo cambiaba la productividad. GPT‑5.3‑Codex propuso varios clasificadores simples con regex para estimar métricas en logs de sesión:
- Frecuencia de aclaraciones (clarifications).
- Respuestas positivas y negativas de usuarios.
- Progreso en la tarea.
Luego ejecutó ese análisis a escala sobre todos los logs y generó un informe con conclusiones. En el resumen del anuncio, la gente que construía con Codex estaba más satisfecha porque el agente entendía mejor la intención y avanzaba más por turno, con menos preguntas de aclaración.
En data science (pipelines nuevos y visualización más rica)
OpenAI también menciona que, por ser tan distinto a predecesores, los datos del alpha mostraban resultados inusuales y contraintuitivos. Una persona de data science trabajó con GPT‑5.3‑Codex para:
- Construir nuevos pipelines de datos.
- Visualizar resultados de forma más rica de lo que permitían los dashboards estándar.
- Co-analizar resultados con Codex, que resumió insights clave sobre miles de puntos de datos en menos de tres minutos.
En conjunto, el mensaje es claro: más allá del “qué puede hacer”, el valor está en acelerar equipos enteros en investigación, ingeniería y producto.
Ciberseguridad: más capacidad, más salvaguardas
En los últimos meses, OpenAI afirma haber visto mejoras significativas en tareas de ciberseguridad, útiles tanto para developers como para profesionales de seguridad. En paralelo, indican que han estado preparando salvaguardas reforzadas para apoyar usos defensivos y resiliencia del ecosistema.
GPT‑5.3‑Codex es el primer modelo que OpenAI clasifica como “High capability” para tareas relacionadas con ciberseguridad bajo su Preparedness Framework, y el primero que entrenan directamente para identificar vulnerabilidades de software. Aun diciendo que no tienen evidencia definitiva de que automatice ataques end‑to‑end, adoptan un enfoque precautorio y despliegan lo que describen como su stack de seguridad de ciberseguridad más completo hasta la fecha.
Las mitigaciones que enumeran incluyen:
- Safety training (entrenamiento de seguridad).
- Automated monitoring (monitorización automatizada).
- Trusted access para capacidades avanzadas.
- Pipelines de enforcement (aplicación de políticas) incluyendo threat intelligence.
Como la ciberseguridad es un dominio de doble uso, el planteamiento declarado es iterativo y basado en evidencia: acelerar a defensores para encontrar y corregir vulnerabilidades, y a la vez ralentizar el abuso. En ese marco, lanzan Trusted Access for Cyber, un programa piloto para acelerar investigación defensiva.
A nivel de salvaguardas del ecosistema, mencionan:
- Ampliación de la beta privada de Aardvark, un agente de investigación de seguridad, como primera oferta de una suite de productos y herramientas de Codex Security.
- Colaboración con maintainers open source para ofrecer escaneo gratuito de codebases en proyectos ampliamente usados como Next.js; se cita un caso donde un investigador de seguridad usó Codex para encontrar vulnerabilidades, divulgadas la semana pasada: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
Y en la parte de apoyo económico, además del $1M Cybersecurity Grant Program lanzado en 2023, OpenAI se compromete ahora a $10M en créditos de API para acelerar la defensa con sus modelos más capaces, especialmente en open source e infraestructura crítica. Las organizaciones involucradas en investigación de seguridad de buena fe pueden solicitar créditos y soporte a través de: https://openai.com/index/openai-cybersecurity-grant-program/.
Disponibilidad, rendimiento e infraestructura
Según el anuncio, GPT‑5.3‑Codex está disponible en planes de pago de ChatGPT, en todos los entornos donde se puede usar Codex: app, CLI, extensión para IDE y web. También indican que están trabajando para habilitar acceso por API “pronto”, con medidas de seguridad.
Además de la mejora del modelo, OpenAI afirma que ahora ejecutan GPT‑5.3‑Codex un 25% más rápido para usuarios de Codex, gracias a mejoras de infraestructura e inferencia, lo que debería traducirse en interacciones y resultados más ágiles.
En cuanto al hardware, GPT‑5.3‑Codex fue co-diseñado, entrenado y servido en NVIDIA GB200 NVL72, y OpenAI agradece la colaboración de NVIDIA.
Descargar la app de Codex (macOS)Qué cambia de fondo: del “mejor agente de código” a un agente generalista
La lectura estratégica del anuncio es que Codex está dejando de ser “solo” un generador/revisor de código para convertirse en un sistema que usa el código como herramienta para operar el ordenador y completar trabajo end‑to‑end. Empujar el límite en agentes de programación abre la puerta a una clase más amplia de trabajo: construir y desplegar software, pero también investigar, analizar y ejecutar tareas complejas que mezclan herramientas, documentos, datos y UI.
Apéndice: resultados de benchmarks (xhigh)
OpenAI publica una tabla de resultados comparando GPT‑5.3‑Codex con GPT‑5.2‑Codex y GPT‑5.2. Los valores que figuran en el anuncio son:
- SWE‑Bench Pro (Public): GPT‑5.3‑Codex 56.8% · GPT‑5.2‑Codex 56.4% · GPT‑5.2 55.6%
- Terminal‑Bench 2.0: GPT‑5.3‑Codex 77.3% · GPT‑5.2‑Codex 64.0% · GPT‑5.2 62.2%
- OSWorld‑Verified: GPT‑5.3‑Codex 64.7% · GPT‑5.2‑Codex 38.2% · GPT‑5.2 37.9%
- GDPval (wins or ties): GPT‑5.3‑Codex 70.9% · GPT‑5.2‑Codex – · GPT‑5.2 70.9% (high)
- Cybersecurity Capture The Flag Challenges: GPT‑5.3‑Codex 77.6% · GPT‑5.2‑Codex 67.4% · GPT‑5.2 67.7%
- SWE‑Lancer IC Diamond: GPT‑5.3‑Codex 81.4% · GPT‑5.2‑Codex 76.0% · GPT‑5.2 74.6%
Nota sobre las evaluaciones
El anuncio indica que todas las evaluaciones del blog se ejecutaron en GPT‑5.3‑Codex con xhigh reasoning effort.

María García
Editora del equipo español, especialista en e-commerce y WooCommerce. Construir y optimizar tiendas online es mi perfil principal. Disfruto de las soluciones creativas.
Todas las publicacionesMás de María García
 WP Composer: el reemplazo abierto e independiente de WPackagist para gestionar plugins y temas con Composer
WP Composer: el reemplazo abierto e independiente de WPackagist para gestionar plugins y temas con Composer
 WordPress 7.0 Beta 2 ya está lista: cómo probarla y qué cambia (incluye nueva página de Connectors)
WordPress 7.0 Beta 2 ya está lista: cómo probarla y qué cambia (incluye nueva página de Connectors)
 Vulnerabilidad crítica en WPvivid Backup: subida arbitraria de archivos (CVE-2026-1357) y riesgo de RCE en sitios WordPress
Vulnerabilidad crítica en WPvivid Backup: subida arbitraria de archivos (CVE-2026-1357) y riesgo de RCE en sitios WordPress