

GPT-5.3-Codex: ο Codex περνά από «coding agent» σε γενικό συνεργάτη στον υπολογιστή
Ο Codex ξεκίνησε ως ένας agent που γράφει και κάνει review κώδικα. Με το GPT‑5.3‑Codex, η OpenAI ουσιαστικά τον απλώνει σε όλο το φάσμα της επαγγελματικής εργασίας σε έναν υπολογιστή: από terminal workflows και web development μέχρι tasks που μοιάζουν περισσότερο με «γραφείο» (presentations, spreadsheets, κείμενα προϊόντος), αλλά και πιο απαιτητικές ροές όπως debugging, deployment και monitoring.
Το βασικό μήνυμα της ανακοίνωσης είναι διπλό: (α) το μοντέλο ανεβάζει την κορυφή της απόδοσης του GPT‑5.2‑Codex στο coding/agentic κομμάτι και συνδυάζει παράλληλα τις δυνατότητες reasoning και επαγγελματικής γνώσης του GPT‑5.2 σε ένα ενιαίο μοντέλο, και (β) τρέχει 25% πιο γρήγορα, κάτι που μετράει πολύ όταν μιλάμε για εργασίες που «κρατάνε ώρα» και τρώνε πολλά tokens.
Τι σημαίνει «agentic» εδώ (και γιατί έχει σημασία)
Όταν λέμε agentic, δεν μιλάμε απλώς για ένα LLM που δίνει απαντήσεις ή παράγει snippets. Μιλάμε για ένα σύστημα που μπορεί να αναλάβει σύνθετες εργασίες με διάρκεια, να κάνει έρευνα, να χρησιμοποιήσει tools (π.χ. τερματικό, IDE extension, web περιβάλλον), να εκτελέσει βήματα, να ελέγξει αποτελέσματα και να επαναλάβει. Στόχος είναι να δουλεύει σαν συνεργάτης που προχωράει το task end‑to‑end, με εσένα να επιβλέπεις και να κατευθύνεις.
Frontier agentic capabilities: τι δείχνουν τα benchmarks
Η OpenAI αναφέρει ότι το GPT‑5.3‑Codex πιάνει νέα «industry high» σε SWE‑Bench Pro και Terminal‑Bench, ενώ δείχνει ισχυρή απόδοση και στα OSWorld και GDPval. Αυτά τα τέσσερα benchmarks χρησιμοποιούνται (σύμφωνα με την ίδια) για να μετρήσουν coding ικανότητες, agentic συμπεριφορά και real‑world computer‑use.
Coding: SWE‑Bench Pro και Terminal‑Bench 2.0
Στο κομμάτι του καθαρά software engineering, το GPT‑5.3‑Codex φτάνει state‑of‑the‑art αποτελέσματα στο SWE‑Bench Pro, που η OpenAI το περιγράφει ως πιο αυστηρή αξιολόγηση «real‑world software engineering». Ένα κρίσιμο σημείο: ενώ το SWE‑bench Verified (το γνωστότερο στον χώρο) είναι μόνο Python, το SWE‑Bench Pro καλύπτει τέσσερις γλώσσες, είναι πιο ανθεκτικό σε contamination και θεωρείται πιο challenging/industry‑relevant.
Παράλληλα, στο Terminal‑Bench 2.0 (που μετρά πρακτικά «terminal skills» που χρειάζεται ένας coding agent) το μοντέλο ξεπερνά κατά πολύ το προηγούμενο state‑of‑the‑art. Ένα ενδιαφέρον τεχνικό detail: η OpenAI σημειώνει ότι το GPT‑5.3‑Codex το πετυχαίνει αυτό με λιγότερα tokens από κάθε προηγούμενο μοντέλο, κάτι που μεταφράζεται σε περισσότερη «δουλειά» που μπορείς να πάρεις από ένα fixed budget/κοντέξτ.
Web development: μεγάλα projects, αισθητική και «compaction»
Στο web development, η ανακοίνωση τονίζει έναν συνδυασμό από frontier coding δυνατότητες, βελτιώσεις στην αισθητική (aesthetics) και καλύτερο compaction (πιο «σφιχτή»/οικονομική αναπαράσταση και εξέλιξη της δουλειάς), που επιτρέπει στο μοντέλο να χτίζει απαιτητικά παιχνίδια και apps από το μηδέν μέσα σε ημέρες.
Για να τεστάρουν ειδικά την ικανότητα για long‑running agentic web dev, ζήτησαν από το GPT‑5.3‑Codex να φτιάξει δύο web παιχνίδια: (1) τη δεύτερη έκδοση του racing game που είχε παρουσιαστεί στο launch του Codex app, και (2) ένα diving game. Χρησιμοποίησαν skill τύπου develop web game και στη συνέχεια γενικά, προεπιλεγμένα follow‑up prompts (π.χ. «fix the bug», «improve the game»). Το μοντέλο έκανε αυτόνομα iterations πάνω στα παιχνίδια για εκατομμύρια tokens.
Τα demos είναι διαθέσιμα για να τα δοκιμάσεις:
- Racing game v2 (διαφορετικοί racers, 8 χάρτες, items με space bar): https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Diving game (εξερεύνηση reefs, συλλογή για fish codex, διαχείριση oxygen/pressure/hazards): https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Η OpenAI λέει επίσης ότι το GPT‑5.3‑Codex καταλαβαίνει καλύτερα την πρόθεση του χρήστη σε καθημερινά site builds, σε σχέση με το GPT‑5.2‑Codex. Σε απλά ή υπο‑προσδιορισμένα prompts, «πέφτει» σε πιο λειτουργικά sites με sensible defaults – δηλαδή σου δίνει πιο δυνατό starting point.
Χαρακτηριστικό παράδειγμα που δίνεται στην ανακοίνωση: σε prompt για landing page, το GPT‑5.3‑Codex έδειξε αυτόματα το yearly plan ως discounted monthly price (ώστε η έκπτωση να είναι ξεκάθαρη/σκόπιμη, αντί να παρουσιάζει το ετήσιο σύνολο ως πολλαπλασιασμό). Επίσης έφτιαξε ένα testimonial carousel που αλλάζει αυτόματα με τρεις διαφορετικές μαρτυρίες χρήστη αντί για μία, με αποτέλεσμα μια σελίδα που μοιάζει πιο «production‑ready» by default.
Beyond coding: υποστήριξη σε όλο το software lifecycle (και όχι μόνο)
Για πολλούς από εμάς, η καθημερινότητα δεν είναι μόνο κώδικας. Η ανακοίνωση βάζει το GPT‑5.3‑Codex ως εργαλείο για όλο το software lifecycle: debugging, deployment, monitoring, συγγραφή PRDs (Product Requirements Documents), editing κειμένων, user research, tests, metrics και άλλα. Και πέρα από το software: δημιουργία slide decks ή ανάλυση δεδομένων σε sheets.
Στο σκέλος «knowledge work», η OpenAI αναφέρει ότι με custom skills (παρόμοια με αυτά που χρησιμοποιήθηκαν σε προηγούμενα GDPval αποτελέσματα) το GPT‑5.3‑Codex δείχνει ισχυρή απόδοση στο GDPval, «ταιριάζοντας» το GPT‑5.2. Το GDPval είναι αξιολόγηση που δημοσιεύτηκε το 2025 και μετρά performance σε καλά ορισμένες knowledge‑work εργασίες σε 44 επαγγέλματα, όπως δημιουργία παρουσιάσεων, spreadsheets και άλλα work products.
Στα παραδείγματα outputs που αναφέρονται περιλαμβάνονται: Financial advice slides, Retail training doc, NPV analysis spreadsheet και Fashion presentation PDF.
Παράδειγμα task context (GDPval): 10-slide παρουσίαση για variable annuities vs CDs
Ένα από τα task contexts που παρατίθενται είναι αρκετά ενδεικτικό του «επαγγελματικού» χαρακτήρα: το μοντέλο παίρνει ρόλο financial advisor σε wealth management firm και πρέπει να ετοιμάσει 10‑slide PowerPoint με talking points για το γιατί (ως fiduciaries) οι advisors πρέπει να αποθαρρύνουν πελάτες από το να μετατρέπουν certificates of deposits σε variable annuities. Η παρουσίαση πρέπει να καλύψει συγκρίσεις χαρακτηριστικών (με προσοχή σε επενδυτές από FINRA), risk/return και επίδραση στην ανάπτυξη, διαφορές σε penalties, καταλληλότητα και risk tolerance με αναφορά σε NAIC Best Interest Regulations, καθώς και concerns/issues από FINRA και θέματα/ρυθμίσεις από NAIC. Δίνονται και συγκεκριμένες πηγές για χρήση:
- https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf
- https://www.finra.org/investors/insights/high-yield-cds
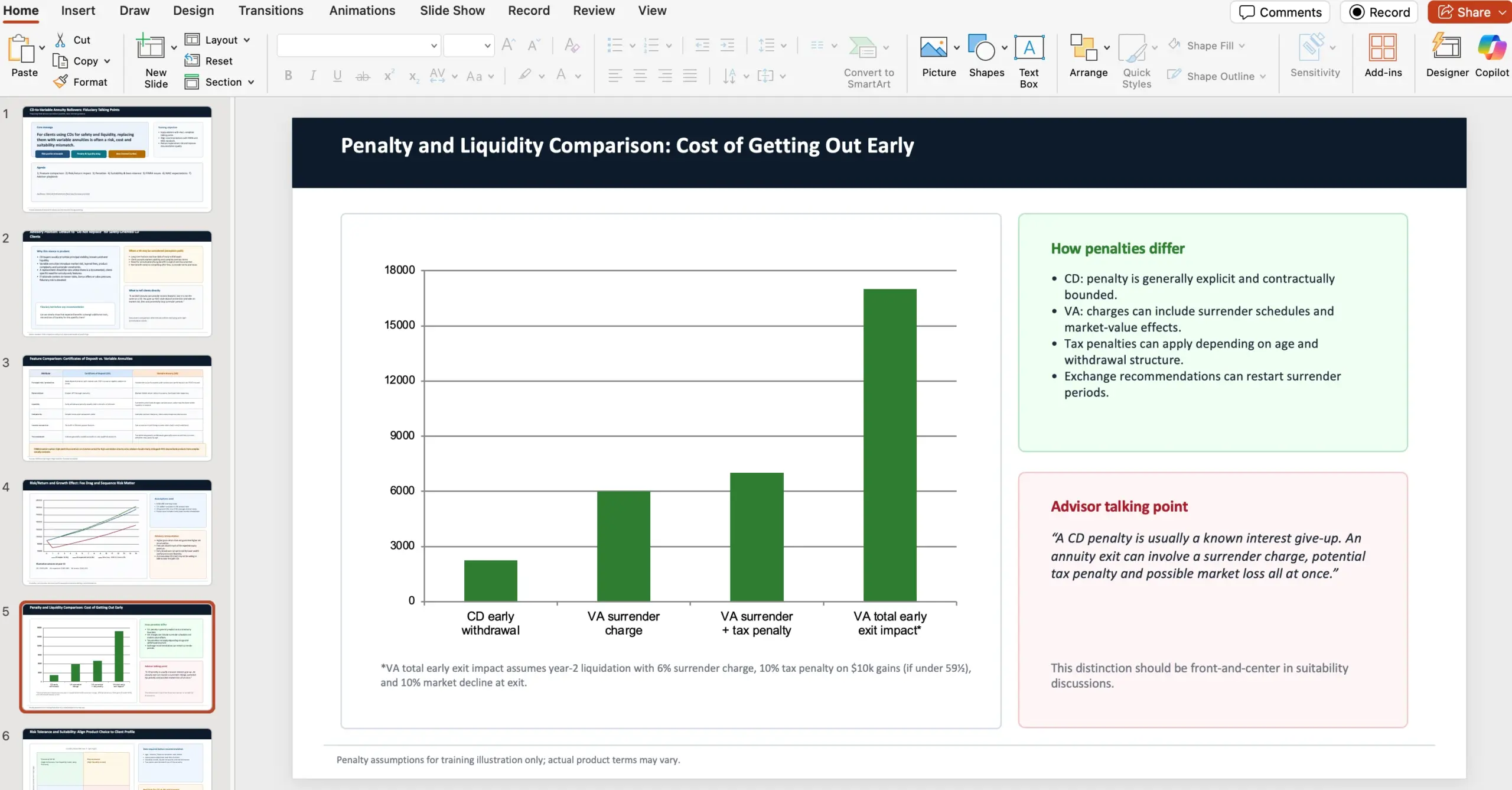
Εδώ η OpenAI σημειώνει και κάτι που έχει αξία όταν κοιτάμε benchmarks: κάθε task του GDPval σχεδιάζεται από έμπειρο επαγγελματία και αντικατοπτρίζει πραγματική δουλειά από το αντίστοιχο επάγγελμα.
OSWorld: computer-use σε οπτικό desktop περιβάλλον
Το OSWorld είναι benchmark όπου ο agent πρέπει να ολοκληρώσει productivity tasks σε ένα οπτικό desktop περιβάλλον (δηλαδή με vision πάνω σε πραγματικό UI). Η OpenAI αναφέρει ότι το GPT‑5.3‑Codex δείχνει πολύ ισχυρότερες δυνατότητες computer use από προηγούμενα GPT μοντέλα, και παραθέτει ότι στο OSWorld‑Verified οι άνθρωποι σκοράρουν περίπου ~72%.
«Interactive collaborator»: πιο πολλή καθοδήγηση, λιγότερη αναμονή
Καθώς οι agents γίνονται πιο δυνατοί, το bottleneck μετατοπίζεται: όχι στο αν μπορούν να κάνουν κάτι, αλλά στο πόσο εύκολα μπορεί ένας άνθρωπος να κατευθύνει, επιβλέψει και συντονίσει πολλούς agents που δουλεύουν παράλληλα. Εδώ μπαίνει το Codex app ως layer διαχείρισης, και με το GPT‑5.3‑Codex γίνεται πιο «interactive».
Σύμφωνα με την ανακοίνωση, το Codex τώρα δίνει πιο συχνά updates ώστε να έχεις εικόνα για βασικές αποφάσεις και πρόοδο όσο εκτελείται η εργασία. Αντί να περιμένεις τελικό output, μπορείς να αλληλεπιδράς σε πραγματικό χρόνο: να ρωτήσεις, να συζητήσεις approaches και να το στρίψεις προς τη λύση. Το μοντέλο εξηγεί τι κάνει, ανταποκρίνεται σε feedback και σε κρατά μέσα στο loop από την αρχή ως το τέλος.
Για να ενεργοποιήσεις το steering όσο δουλεύει (όπως αναφέρεται στην ανακοίνωση): Settings > General > Follow-up behavior.
Το «meta» στοιχείο: το GPT‑5.3‑Codex βοήθησε να δημιουργηθεί το ίδιο
Από τα πιο εντυπωσιακά σημεία της ανακοίνωσης: το GPT‑5.3‑Codex περιγράφεται ως το πρώτο μοντέλο της OpenAI που ήταν «instrumental in creating itself». Η ομάδα του Codex χρησιμοποίησε πρώιμες εκδόσεις του για να κάνει debug την εκπαίδευσή του, να διαχειριστεί το deployment του, και να διαγνώσει test results/evaluations. Η ίδια η ομάδα λέει ότι τους εξέπληξε το πόσο πολύ επιτάχυνε το Codex την εξέλιξή του.
Πώς χρησιμοποιήθηκε ο Codex σε training και deployment (πραγματικά παραδείγματα)
Η OpenAI περιγράφει ότι οι γρήγορες βελτιώσεις του Codex πατάνε πάνω σε ερευνητικά projects μηνών/ετών σε όλη την εταιρεία, αλλά πλέον αυτά τα projects επιταχύνονται από τον Codex. Μάλιστα, πολλοί researchers/engineers περιγράφουν ότι η δουλειά τους σήμερα είναι «θεμελιωδώς διαφορετική» από πριν δύο μήνες.
Αναφέρει επίσης ότι ακόμη και οι early εκδόσεις του GPT‑5.3‑Codex ήταν αρκετά δυνατές ώστε να χρησιμοποιηθούν για να βελτιώσουν το training και να υποστηρίξουν το deployment των επόμενων εκδόσεων. Και επειδή το Codex καλύπτει πολύ μεγάλο εύρος, δίνουν ενδεικτικά παραδείγματα:
- Η research ομάδα το χρησιμοποίησε για monitoring και debugging του training run της έκδοσης. Δεν έμεινε μόνο σε infra προβλήματα: βοήθησε να εντοπιστούν patterns στη διάρκεια του training, έκανε deep analysis στην ποιότητα αλληλεπίδρασης, πρότεινε fixes και έχτισε rich applications ώστε οι ερευνητές να καταλάβουν με ακρίβεια πώς διαφοροποιείται η συμπεριφορά του μοντέλου από προηγούμενα.
- Η engineering ομάδα το χρησιμοποίησε για optimization και adaptation του harness για το GPT‑5.3‑Codex. Όταν εμφανίστηκαν περίεργα edge cases που επηρέαζαν χρήστες, μέλη της ομάδας το χρησιμοποίησαν για να εντοπίσουν context rendering bugs και να βρουν root cause για χαμηλά cache hit rates.
- Κατά τη διάρκεια του launch, το GPT‑5.3‑Codex συνέχισε να βοηθά με το να κάνει δυναμικό scaling σε GPU clusters ώστε να απορροφώνται traffic surges και να παραμένει σταθερό το latency.
- Σε alpha testing, ένας researcher ήθελε να μετρήσει πόση επιπλέον δουλειά ολοκλήρωνε το μοντέλο ανά turn και πώς αυτό επηρέαζε παραγωγικότητα. Το GPT‑5.3‑Codex πρότεινε απλούς regex classifiers για να εκτιμηθεί η συχνότητα από clarifications, θετικών/αρνητικών αντιδράσεων χρήστη και πρόοδος στο task· στη συνέχεια τους έτρεξε κλιμακωτά πάνω σε όλα τα session logs και έβγαλε report με συμπεράσματα.
- Το συμπέρασμα που αναφέρουν: οι builders ήταν πιο ικανοποιημένοι γιατί ο agent καταλάβαινε καλύτερα την πρόθεση και έκανε περισσότερη πρόοδο ανά turn, με λιγότερες διευκρινιστικές ερωτήσεις.
- Επειδή το GPT‑5.3‑Codex διαφέρει αρκετά από τους προκατόχους του, τα alpha δεδομένα είχαν πολλά ασυνήθιστα/αντι-διαισθητικά αποτελέσματα. Ένας data scientist, με τη βοήθεια του GPT‑5.3‑Codex, έφτιαξε νέα data pipelines και πιο πλούσιες οπτικοποιήσεις από αυτές που επέτρεπαν τα standard dashboarding tools· μετά έγινε co-analysis με τον Codex, που συνόψισε insights από χιλιάδες data points σε λιγότερο από τρία λεπτά.
Η OpenAI το συνοψίζει ως συνολική επιτάχυνση των research, engineering και product ομάδων, όχι μόνο ως μεμονωμένα «εντυπωσιακά demos».
Securing the cyber frontier: πιο δυνατός agent, πιο αυστηρό safety stack
Η ανακοίνωση μπαίνει έντονα και στο cybersecurity. Η OpenAI λέει ότι τους τελευταίους μήνες έχουν δει ουσιαστικές βελτιώσεις σε cyber tasks, κάτι που ωφελεί τόσο developers όσο και security professionals. Παράλληλα, προετοιμάζουν «strengthened cyber safeguards» για να στηρίξουν αμυντική χρήση και ανθεκτικότητα του οικοσυστήματος (link στο σχετικό post).
Το GPT‑5.3‑Codex είναι το πρώτο μοντέλο που ταξινομούν ως High capability για cybersecurity‑related tasks, σύμφωνα με το Preparedness Framework τους. Είναι επίσης το πρώτο που (όπως λένε) εκπαιδεύτηκε άμεσα για να εντοπίζει software vulnerabilities. Παρότι δεν έχουν «definitive evidence» ότι μπορεί να αυτοματοποιήσει cyber attacks end‑to‑end, επιλέγουν προληπτική προσέγγιση και το κάνουν deploy με το πιο ολοκληρωμένο cybersecurity safety stack μέχρι σήμερα.
Οι mitigations που αναφέρονται περιλαμβάνουν:
- safety training
- automated monitoring
- trusted access για advanced capabilities
- enforcement pipelines που περιλαμβάνουν threat intelligence
Επειδή το cybersecurity είναι από τη φύση του dual‑use, περιγράφουν μια evidence‑based, iterative προσέγγιση: επιτάχυνση των defenders στο να βρίσκουν/διορθώνουν ευπάθειες, ενώ ταυτόχρονα επιβράδυνση της κακόβουλης χρήσης.
Στο πλαίσιο αυτό, λανσάρουν το Trusted Access for Cyber, ένα pilot program για επιτάχυνση έρευνας στην cyber άμυνα.
Σε επίπεδο οικοσυστήματος, επενδύουν σε safeguards όπως:
- Επέκταση του private beta του Aardvark, ενός security research agent, ως πρώτο offering στη σουίτα Codex Security products και tools.
- Συνεργασίες με open‑source maintainers για δωρεάν codebase scanning σε ευρέως χρησιμοποιούμενα projects όπως το Next.js – με αναφορά ότι security researcher χρησιμοποίησε Codex για να βρει ευπάθειες που δημοσιοποιήθηκαν την προηγούμενη εβδομάδα: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
Τέλος, πάνω στο $1M Cybersecurity Grant Program που ξεκίνησε το 2023, δεσμεύουν επιπλέον $10M σε API credits για να επιταχύνουν την cyber άμυνα με τα πιο ικανά μοντέλα τους, ειδικά για open source και critical infrastructure systems. Οργανισμοί που κάνουν good‑faith security research μπορούν να αιτηθούν API credits και υποστήριξη μέσω του Cybersecurity Grant Program.
Διαθεσιμότητα και πρακτικές λεπτομέρειες
Το GPT‑5.3‑Codex είναι διαθέσιμο με paid ChatGPT plans, παντού όπου μπορείς να χρησιμοποιήσεις Codex: app, CLI, IDE extension και web. Για το API, η OpenAI αναφέρει ότι δουλεύει ώστε να ενεργοποιήσει API access σύντομα, με ασφαλή τρόπο.
Με αυτή την ενημέρωση, αναφέρουν ότι τρέχουν το GPT‑5.3‑Codex 25% πιο γρήγορα για τους Codex users, χάρη σε βελτιώσεις σε infrastructure και inference stack, κάτι που οδηγεί σε πιο γρήγορες αλληλεπιδράσεις και αποτελέσματα.
Σε επίπεδο hardware/serving: το GPT‑5.3‑Codex συν-σχεδιάστηκε για, εκπαιδεύτηκε με, και σερβίρεται πάνω σε NVIDIA GB200 NVL72 systems.
Τι έρχεται μετά (σύμφωνα με την ανακοίνωση)
Η OpenAI τοποθετεί το GPT‑5.3‑Codex ως το σημείο όπου ο Codex περνά από το να «γράφει κώδικα» στο να χρησιμοποιεί τον κώδικα ως εργαλείο για να χειρίζεται έναν υπολογιστή και να ολοκληρώνει εργασίες end‑to‑end. Σπρώχνοντας τα όρια ενός coding agent, ανοίγει και μια ευρύτερη κατηγορία knowledge work: από build/deploy software μέχρι έρευνα, ανάλυση και εκτέλεση σύνθετων tasks. Αυτό που ξεκίνησε ως στόχος να είναι ο καλύτερος coding agent, παρουσιάζεται πλέον ως βάση για έναν πιο γενικό συνεργάτη πάνω στον υπολογιστή.
Appendix: αριθμοί αξιολογήσεων που δημοσιεύτηκαν
Η ανακοίνωση περιλαμβάνει έναν πίνακα με αποτελέσματα για GPT‑5.3‑Codex (xhigh), GPT‑5.2‑Codex (xhigh) και GPT‑5.2 (xhigh):
- SWE-Bench Pro (Public): GPT-5.3-Codex 56.8% | GPT-5.2-Codex 56.4% | GPT-5.2 55.6%
- Terminal-Bench 2.0: GPT-5.3-Codex 77.3% | GPT-5.2-Codex 64.0% | GPT-5.2 62.2%
- OSWorld-Verified: GPT-5.3-Codex 64.7% | GPT-5.2-Codex 38.2% | GPT-5.2 37.9%
- GDPval (wins or ties): GPT-5.3-Codex 70.9% | GPT-5.2 (xhigh) 70.9% (high)
- Cybersecurity Capture The Flag Challenges: GPT-5.3-Codex 77.6% | GPT-5.2-Codex 67.4% | GPT-5.2 67.7%
- SWE-Lancer IC Diamond: GPT-5.3-Codex 81.4% | GPT-5.2-Codex 76.0% | GPT-5.2 74.6%
Σημείωση για τις αξιολογήσεις
Σύμφωνα με το footnote της ανακοίνωσης, όλα τα evaluations στο blog έτρεξαν σε GPT‑5.3‑Codex με xhigh reasoning effort.
Λήψη & δοκιμή
Η OpenAI δίνει link για να το δοκιμάσεις στο Codex app (Mac):
Try it in the Codex app


Αναφορές / Πηγές
Ελένη Γεωργίου
Προγραμματίστρια τουριστικής τεχνολογίας και πλατφορμών φιλοξενίας. Συστήματα online κρατήσεων και λογισμικό φιλοξενίας είναι ο τομέας μου. Η μεσογειακή φιλοξενία λειτουργεί και ψηφιακά.
Όλες οι αναρτήσεις

