

GPT-5.3-Codex: агентен модел, който изкарва Codex отвъд писането на код
OpenAI представи GPT‑5.3‑Codex (5 февруари 2026) като следващата голяма стъпка в Codex: от агент, който основно пише и ревюира код, към агент, който може да върши почти всичко, което един разработчик (и изобщо професионалист) прави на компютър – проучване, работа с инструменти, изпълнение на комплексни стъпки и довеждане на задачи докрай.
По описанието в анонса моделът комбинира две линии подобрения в едно: frontier coding напредъка на GPT‑5.2‑Codex и reasoning + професионално знание от GPT‑5.2. Освен това се изпълнява 25% по-бързо, което на практика има значение точно при дълги, инструментално-ориентирани задачи, където latency и токен-бюджетът реално определят колко итерации можеш да си позволиш.
Една от най-интересните подробности: GPT‑5.3‑Codex е първият модел, който е бил инструментален в създаването на самия себе си. Екипът на Codex е използвал ранни версии, за да дебъгва собственото обучение, да управлява деплоймънта и да диагностицира тестове и оценки – и според тях темпото на разработка се е ускорило осезаемо.
Frontier agentic capabilities: какво всъщност мери OpenAI
В анонса OpenAI позиционира GPT‑5.3‑Codex като „най-способния agentic coding модел до момента“ и го подкрепя с резултати на четири бенчмарка, които използват за кодиране, агентно поведение и „реална работа“: SWE‑Bench Pro, Terminal‑Bench, OSWorld и GDPval.
Coding: SWE‑Bench Pro и Terminal‑Bench 2.0
За чистото софтуерно инженерство акцентът е SWE‑Bench Pro – по-строг и по-индустриално релевантен от SWE‑bench Verified. Ключовата разлика, която OpenAI подчертава: Verified тества само Python, докато SWE‑Bench Pro обхваща четири езика, по-устойчив е на contamination и е по-разнообразен и предизвикателен.
Отделно, моделът „значително надминава“ предишното state-of-the-art на Terminal‑Bench 2.0, който е насочен към практическите умения в терминал (команди, навигация, комбиниране на инструменти) – точно това, което един агент като Codex трябва да умее, за да не остане на ниво „генерирам код“, а да може да го пусне, провери и поправи. В анонса се отбелязва и нещо важно за продуктивността: GPT‑5.3‑Codex постига това с по-малко токени спрямо предишни модели, което оставя повече бюджет за реална работа в рамките на сесия.
Web development: дълги автономни итерации и по-добри „дефолти“
За уеб разработка OpenAI комбинира три линии: по-силно кодиране, по-добра естетика и „compaction“ (по-компактен/ефективен начин на представяне на контекст и решения). Претенцията е, че това позволява на модела да прави впечатляващи неща – включително сложни игри и приложения от нулата, развивани в рамките на дни.
Като тест за long-running agentic поведение, OpenAI е накарал GPT‑5.3‑Codex да изгради две браузърни игри с „develop web game“ умение и предварително подбрани, общи follow-up подсказки от рода на „fix the bug“ или „improve the game“. Моделът е итерал автономно през милиони токени.
- Racing game v2: състезателна игра с различни „рейсъри“, 8 карти и items, които се използват със space bar. Демото е достъпно тук: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
- Diving game: игра за гмуркане и изследване на рифове, събиране на обекти за „fish codex“, управление на кислород, налягане и опасности. Демото е достъпно тук: https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
Още една практична разлика спрямо GPT‑5.2‑Codex: когато му дадеш „ежедневни“ и дори леко недоизказани инструкции за сайт, GPT‑5.3‑Codex по-често избира смислени дефолти и добавя функционалност, която прави резултата по-близък до production-ready стартов шаблон.
Примерът в материала е с две landing pages за продукт „Quiet KPI“. При GPT‑5.3‑Codex OpenAI отбелязва конкретни подобрения:
- При yearly plan моделът показва discounted monthly price, вместо просто да разпредели годишната сума – така отстъпката изглежда ясна и умишлена.
- Добавен е автоматично преминаващ testimonial carousel с три различни цитата, вместо единичен, което прави страницата по-завършена по подразбиране.
Beyond coding: поддръжка на целия софтуерен lifecycle и knowledge work
Тук идеята е проста: в реалния свят инженерите не „само пишат код“. Има дебъг, деплой, мониторинг, писане на PRD-и, редакция на текстове, потребителско проучване, тестове, метрики и анализи. GPT‑5.3‑Codex е позициониран като модел, който да подпомага целия софтуерен жизнен цикъл, а и задачи извън софтуера – например изготвяне на презентации или анализ в spreadsheets.
OpenAI връзва това към GDPval – evaluation, пуснат през 2025 г., който измерва представянето на модел върху добре специфицирани knowledge-work задачи в 44 професии (презентации, таблици и други работни артефакти). В анонса се казва, че с custom skills (подобни на тези в предишните GDPval резултати) GPT‑5.3‑Codex показва силно представяне и изравнява GPT‑5.2 по GDPval.
Примерна задача от GDPval: презентация за финансови консултанти
Един от дадените примери описва задача, проектирана от опитен професионалист: да се изготви 10-слайд PowerPoint като talking points за финансови консултанти (fiduciaries) защо да препоръчват да не се прави конкретно инвестиционно решение – прехвърляне на certificates of deposits (CDs) към variable annuities. В контекста са зададени и конкретни източници за ползване:
- NAIC документ: https://content.naic.org/sites/default/files/government-affairs-brief-annuity-suitability-best-interest-model.pdf
- FINRA материал: https://www.finra.org/investors/insights/high-yield-cds
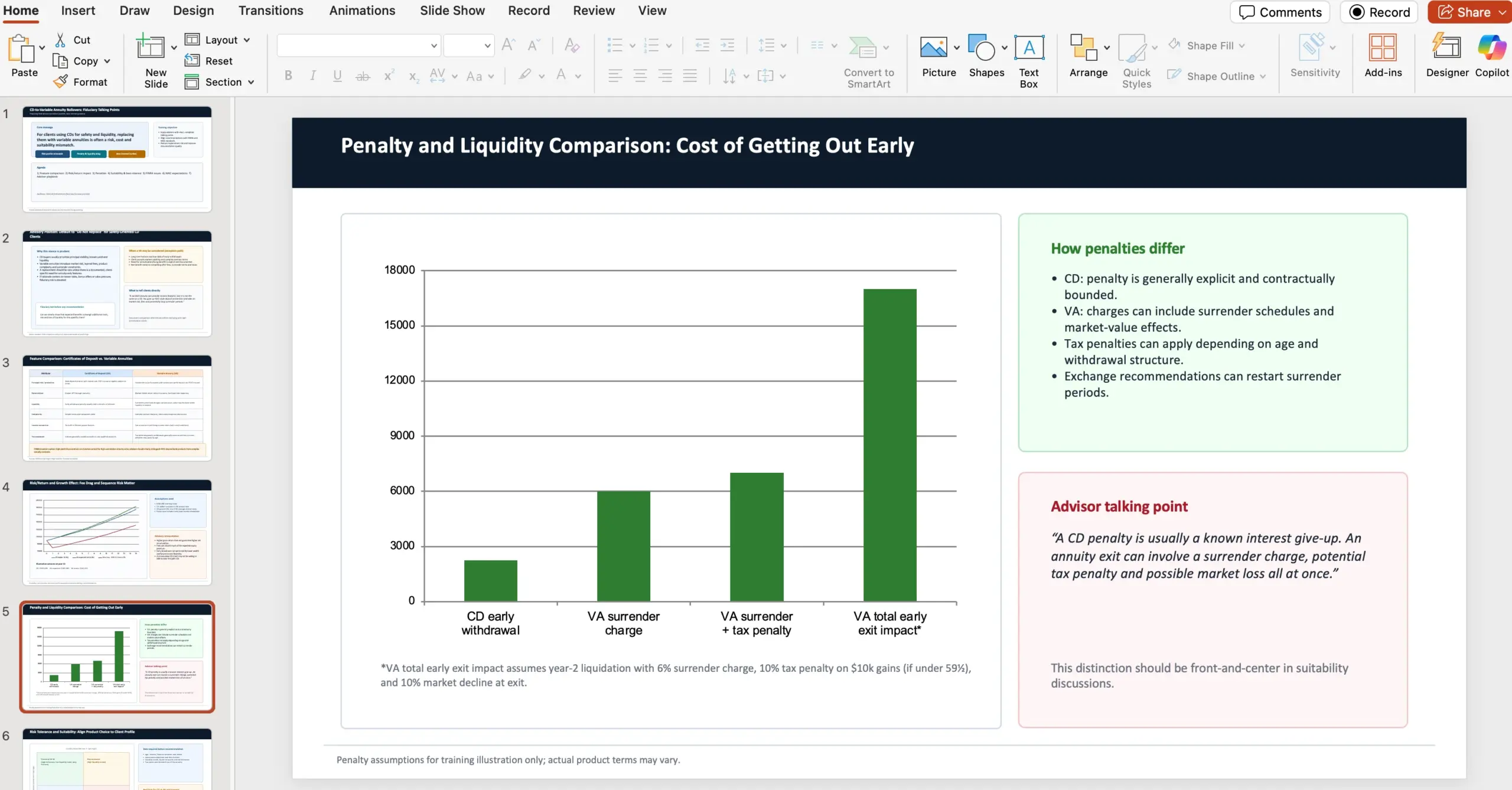
OpenAI подчертава, че всяка GDPval задача е проектирана от практикуващ професионалист и отразява реална работа от съответната професия – т.е. не е просто „тест по общи знания“, а симулация на deliverable.
OSWorld: агент, който работи във визуална десктоп среда
OSWorld е бенчмарк за „computer use“: агентът трябва да изпълнява продуктивни задачи във визуална desktop среда, използвайки vision. В материала се казва, че GPT‑5.3‑Codex демонстрира много по-силни възможности за работа с компютър спрямо предишни GPT модели. Споменава се и референтна точка: при OSWorld-Verified хората постигат ~72%.
Интерактивен колаборатор: как се управлява агентът, докато работи
С повишаването на възможностите проблемът все по-малко е „може ли агентът да направи нещо“ и все повече е „колко лесно човек може да го насочва и надзирава, включително паралелно“. Тук Codex app е ключовият интерфейс – според OpenAI той прави управлението и насочването на агенти значително по-лесно, а с GPT‑5.3‑Codex става и по-интерактивно.
Конкретните промени, описани в анонса:
- Codex дава по-чести обновления за ключови решения и прогрес, докато работи.
- Вместо да чакаш финален резултат, можеш да взаимодействаш в реално време: да задаваш въпроси, да обсъждаш подход и да насочваш решението.
- Моделът „говори“ през това какво прави, реагира на обратна връзка и те държи в течение от начало до край.
За да е възможно това „steering“ поведение (насочване по време на изпълнение) в приложението, настройката е: Settings > General > Follow-up behavior.
Как OpenAI е използвал Codex, за да обучи и деплойне GPT‑5.3‑Codex
В тази част има практични детайли, които си струва да се прочетат като шаблон за това как би изглеждала реалната работа с агент в R&D и production екип.
OpenAI описва, че скорошните подобрения в Codex стъпват върху по-дълги изследователски линии (месеци/години), но темпото е нараснало, защото Codex ускорява самата работа. Те дори казват, че за много изследователи и инженери работата им днес е „фундаментално различна“ спрямо преди два месеца.
Примери от research: мониторинг и дебъг на training run
Изследователският екип е използвал Codex за мониторинг и дебъг на training run за релийза. И не само за инфраструктурни проблеми: Codex е помагал да се следят патерни през целия training, да се прави дълбок анализ на „interaction quality“, да се предлагат фиксове и да се изграждат приложения за човешки изследователи, които да разбират прецизно как поведението на модела се различава спрямо предишни версии.
Примери от engineering: harness, edge cases и latency
Инженерният екип е използвал Codex да оптимизира и адаптира harness-а за GPT‑5.3‑Codex. Когато са започнали да виждат странни edge cases, хората са използвали Codex да идентифицира context rendering bugs и да стигне до root cause за ниски cache hit rate стойности.
По време на launch-а GPT‑5.3‑Codex е продължил да помага оперативно – включително с динамично скалиране на GPU клъстери, за да се поемат traffic surges и да се държи latency стабилна.
Алфа анализ: измерване на продуктивност „per turn“ с regex класификатори
По време на alpha testing един изследовател е искал да оцени колко допълнителна работа GPT‑5.3‑Codex върши „на ход“ (per turn) и как това се превежда в продуктивност. Според описанието GPT‑5.3‑Codex е предложил няколко прости regex classifier-а, с които да се оценява:
- честота на уточняващи въпроси (clarifications)
- позитивни и негативни потребителски реакции
- прогрес по задачата
След това е „пуснал“ тези класификатори мащабно върху session logs и е произвел репорт с изводите си. Изводът, описан в анонса: хората, които билдват с Codex, са били по-доволни, защото агентът по-добре разбира намерението и прави повече прогрес на ход, с по-малко уточняващи въпроси.
Неочаквани резултати и по-богата визуализация
OpenAI отбелязва, че заради това колко различен е GPT‑5.3‑Codex спрямо предшествениците, данните от alpha тестовете са показали много необичайни и контра-интуитивни резултати. Един data scientist е работил с GPT‑5.3‑Codex за изграждане на нови data pipelines и по-богати визуализации от стандартните dashboard инструменти, а после резултатите са били ко-анализирани с Codex – който е обобщил ключовите инсайти върху хиляди datapoints за под 3 минути.
Securing the cyber frontier: киберсигурност, dual-use и „High capability“ класификация
OpenAI твърди, че през последните месеци има значими печалби в представянето на модели върху cybersecurity задачи – полезни както за девелопъри, така и за security професионалисти. Паралелно компанията подготвя „подсилени“ cyber safeguards (линкът в анонса сочи към публикация за укрепване на cyber resilience).
Ключовото: GPT‑5.3‑Codex е първият модел, който OpenAI класифицира като High capability за cybersecurity-related задачи според Preparedness Framework, и първият, който е директно трениран да идентифицира софтуерни уязвимости.
Предпазлив деплоймънт
OpenAI казва, че няма окончателни доказателства, че моделът може да автоматизира кибератаки end-to-end, но въпреки това избира предпазлив подход и деплойва най-цялостния си досега cybersecurity safety stack.
Описаните мерки включват:
- safety training
- автоматизиран мониторинг
- trusted access за advanced capabilities
- enforcement pipelines, включително threat intelligence
Понеже киберсигурността е по природа dual-use, подходът е „evidence-based“ и итеративен: да се ускори работата на защитниците по намиране и поправка на уязвимости, като едновременно се забави злоупотребата.
Като част от това OpenAI стартира Trusted Access for Cyber – pilot програма за ускоряване на research в киберзащитата.
Екосистемни защити: Aardvark и сканиране на open source
OpenAI инвестира и в мерки на ниво екосистема. В анонса има два конкретни детайла:
- Разширяване на private beta на Aardvark – security research агент, позициониран като първа оферта в suite от Codex Security продукти и инструменти.
- Партньорства с open-source maintainers за безплатно сканиране на кодови бази на широко използвани проекти като Next.js. В материала се посочва пример, при който security researcher е използвал Codex, за да намери уязвимости, които са били disclosed от Vercel: https://vercel.com/changelog/summaries-of-cve-2025-59471-and-cve-2025-59472
Финансиране: $10M в API кредити за киберзащита
Върху основата на $1M Cybersecurity Grant Program (стартирана през 2023), OpenAI поема ангажимент за $10M в API credits, насочени към ускоряване на киберзащитата с най-способните модели – особено за open source и системи от критична инфраструктура. Организации, които правят „good-faith security research“, могат да кандидатстват за кредити и подкрепа през: https://openai.com/index/openai-cybersecurity-grant-program/
Наличност и инфраструктурни детайли
По данни от анонса, GPT‑5.3‑Codex е наличен с платени ChatGPT планове, навсякъде, където може да се използва Codex: app, CLI, IDE extension и web. За API достъп се казва само, че работят по това да го активират безопасно „скоро“.
OpenAI допълва, че за потребителите на Codex моделът върви 25% по-бързо, благодарение на подобрения в инфраструктурата и inference stack-а – по-бързи интеракции и по-бързи резултати.
Има и конкретика за хардуера: GPT‑5.3‑Codex е ко-дизайнван, трениран и сервван на NVIDIA GB200 NVL72 системи, като OpenAI изрично благодари на NVIDIA за партньорството.
Какво показват числата: таблицата от Appendix
В Appendix OpenAI публикува сравнителна таблица между GPT‑5.3‑Codex (xhigh), GPT‑5.2‑Codex (xhigh) и GPT‑5.2 (xhigh). Ето стойностите, както са дадени:
- SWE‑Bench Pro (Public): 56.8% (GPT‑5.3‑Codex) vs 56.4% (GPT‑5.2‑Codex) vs 55.6% (GPT‑5.2)
- Terminal‑Bench 2.0: 77.3% vs 64.0% vs 62.2%
- OSWorld‑Verified: 64.7% vs 38.2% vs 37.9%
- GDPval (wins or ties): 70.9% vs – vs 70.9% (high)
- Cybersecurity Capture The Flag Challenges: 77.6% vs 67.4% vs 67.7%
- SWE‑Lancer IC Diamond: 81.4% vs 76.0% vs 74.6%
Бележка за режима на оценяване
OpenAI уточнява, че всички оценки в блога са пуснати на GPT‑5.3‑Codex с xhigh reasoning effort.
Какво следва според OpenAI
В секцията „What’s next“ посланието е, че с GPT‑5.3‑Codex Codex се измества от „генериране на код“ към „използване на кода като инструмент“, за да управлява компютър и да завършва работа end-to-end. Това разширява Codex и към по-широк клас knowledge work – от изграждане и деплой на софтуер до проучване, анализ и изпълнение на комплексни задачи.
Финалният framing е показателен: стремежът да бъдат „най-добрият coding agent“ се превръща във фундамент за по-общ колаборатор на компютъра – разширявайки както кой може да създава, така и какво е възможно да се постигне с Codex.



Препратки / Източници
Георги Петров
Backend разработчик и системен архитект. Експерт по PHP и Laravel, изграждането на уеб приложения с голям трафик е моята специалност.
Всички публикацииОще от Георги Петров
 Joost de Valk се оттегля от FAIR: какво означава това за идеята за независим WordPress repository
Joost de Valk се оттегля от FAIR: какво означава това за идеята за независим WordPress repository
 Европейският акт за достъпност вече е факт: какво трябва да направиш с WordPress сайта си още сега
Европейският акт за достъпност вече е факт: какво трябва да направиш с WordPress сайта си още сега
 WordPress се връща към три major версии през 2026: старт на планирането за 7.0, AI Client, admin refresh и по-висок минимален PHP
WordPress се връща към три major версии през 2026: старт на планирането за 7.0, AI Client, admin refresh и по-висок минимален PHP